
GFS 的设计决策
- 第一个是以工程上“简单”作为设计原则。
- 直接使用了 Linux 服务上的普通文件作为基础存储层,并且选择了最简单的单 Master 设计
- 第二个是根据硬件特性来进行设计取舍。
- 重视的是顺序读写的性能,对随机写入的一致性甚至没有任何保障
- 专门设计了一个 Snapshot 的文件复制操作,避免了数据在网络上传输
- 第三个是根据实际应用的特性,放宽了数据一致性(consistency)的选择。
- GFS 本身对于随机写入的一致性没有任何保障,而是把这个任务交给了客户端。对于追加写入(Append),GFS 也只是作出了“至少一次(At Least Once)”这样宽松的保障。
Master 的第一个身份:一个目录服务
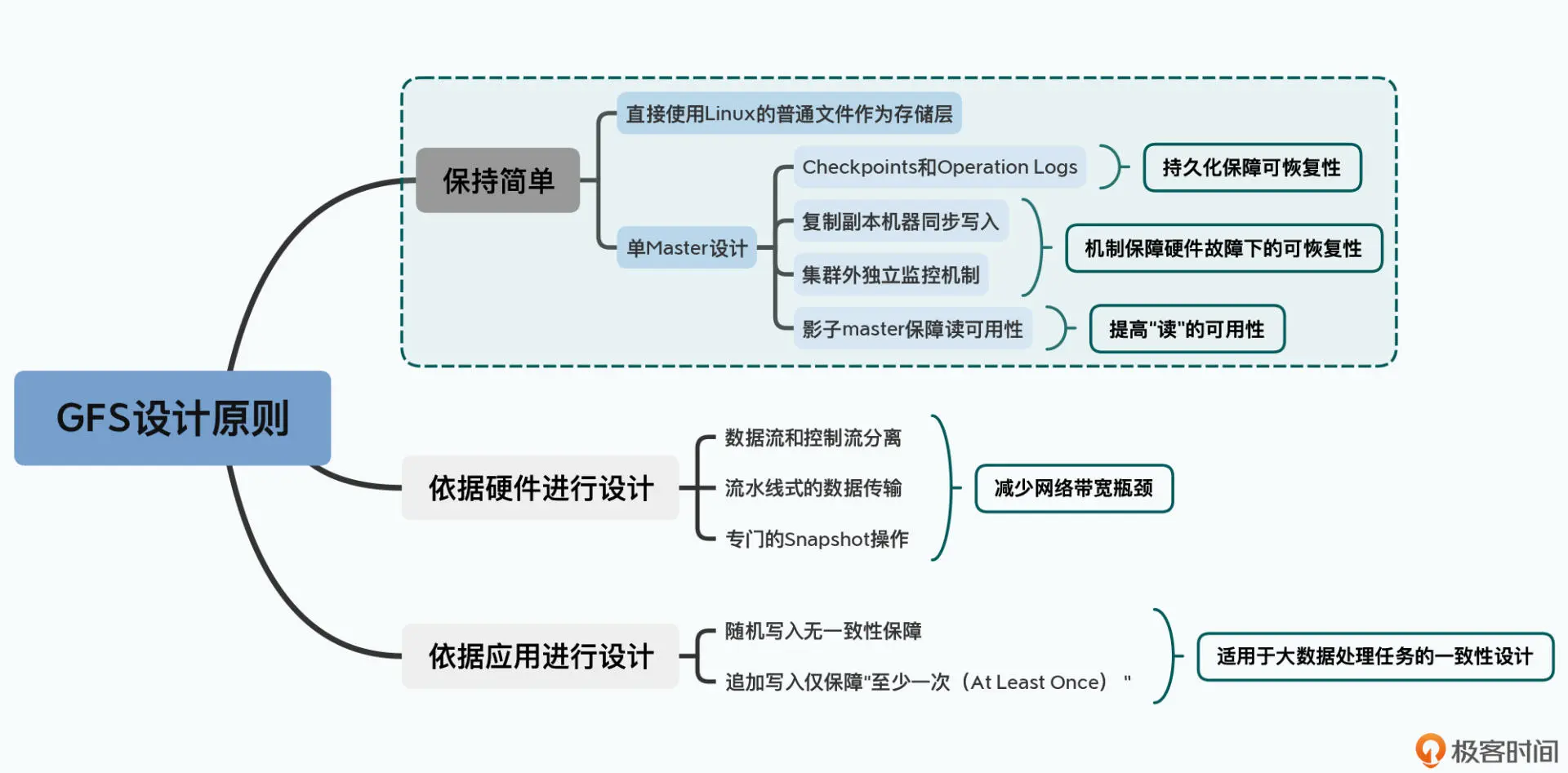
在整个 GFS 中,有两种服务器,一种是 master,也就是整个 GFS 中有且 仅有一个的主控节点;第二种是 chunkserver,也就是实际存储数据的节点。
在 GFS 里面,会把每一个文件按照 64MB 一块的大小,切分成一个个 chunk。每 个 chunk 都会有一个在 GFS 上的唯一的 handle,这个 handle 其实就是一个编号,能够 唯一标识出具体的 chunk。然后每一个 chunk,都会以一个文件的形式,放在 chunkserver 上。
而 chunkserver,其实就是一台普通的 Linux 服务器,上面跑了一个用户态的 GFS 的 chunkserver 程序。这个程序,会负责和 master 以及 GFS 的客户端进行 RPC 通信,完 成实际的数据读写操作。
每个 chunk 都会存上整整三份副本(replica)。其中一份是主数据(primary),两份是副数据 (secondary),当三份数据出现不一致的时候,就以主数据为准。有了三个副本,不仅 可以防止因为各种原因丢数据,还可以在有很多并发读取的时候,分摊系统读取的压力
GFS 的客户端,怎么知道该去哪个 chunkserver 找自己要的文件呢?
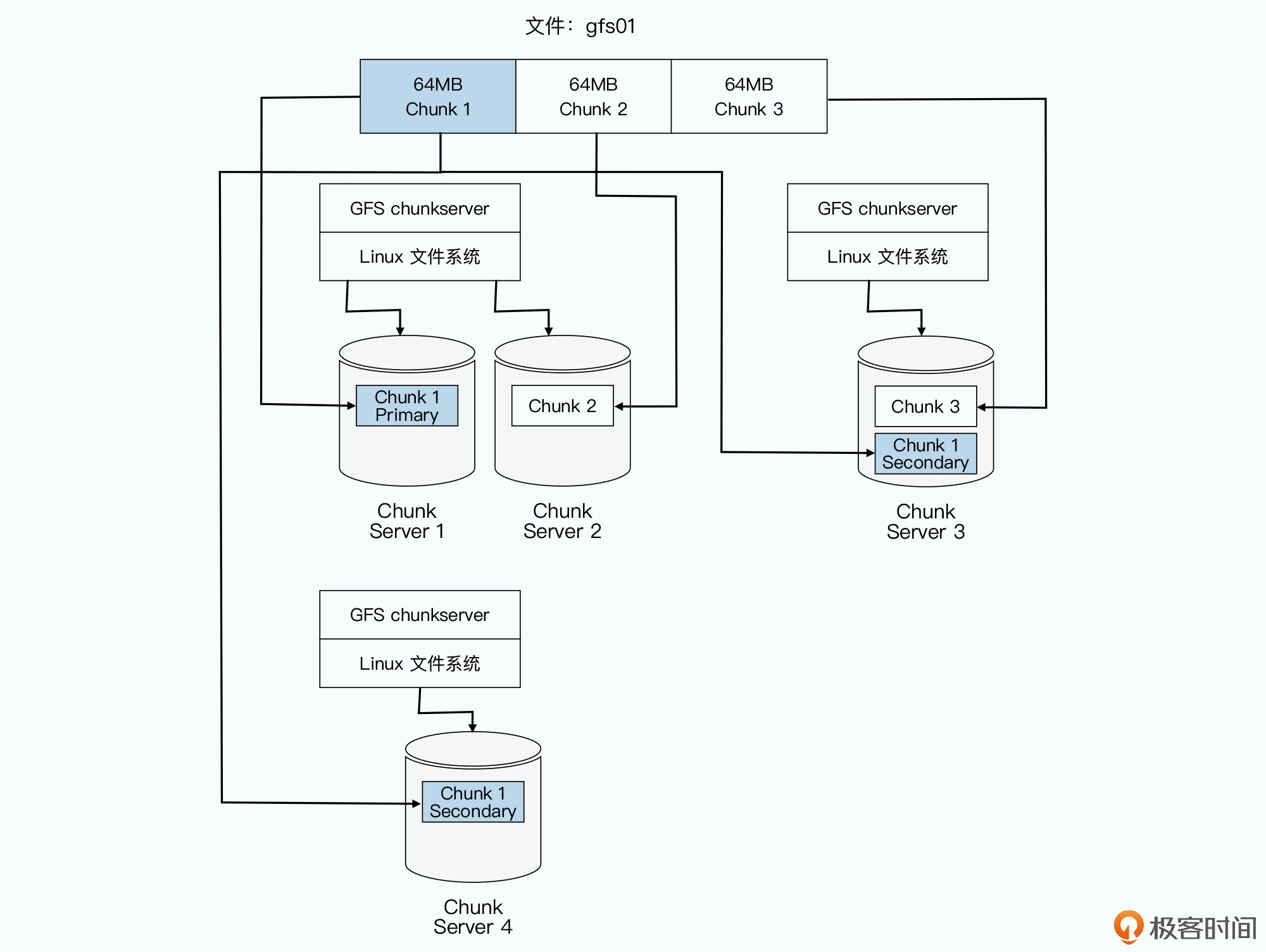
答案当然是问 master 啦。 首先,master 里面会存放三种主要的元数据(metadata):
- 文件和 chunk 的命名空间信息,也就是类似前面 /data/geektime/bigdata/gfs01 这样的路径和文件名;
- 这些文件被拆分成了哪几个 chunk,也就是这个全路径文件名到多个 chunk handle 的映射关系;
- 这些 chunk 实际被存储在了哪些 chunkserver 上,也就是 chunk handle 到 chunkserver 的映射关系。
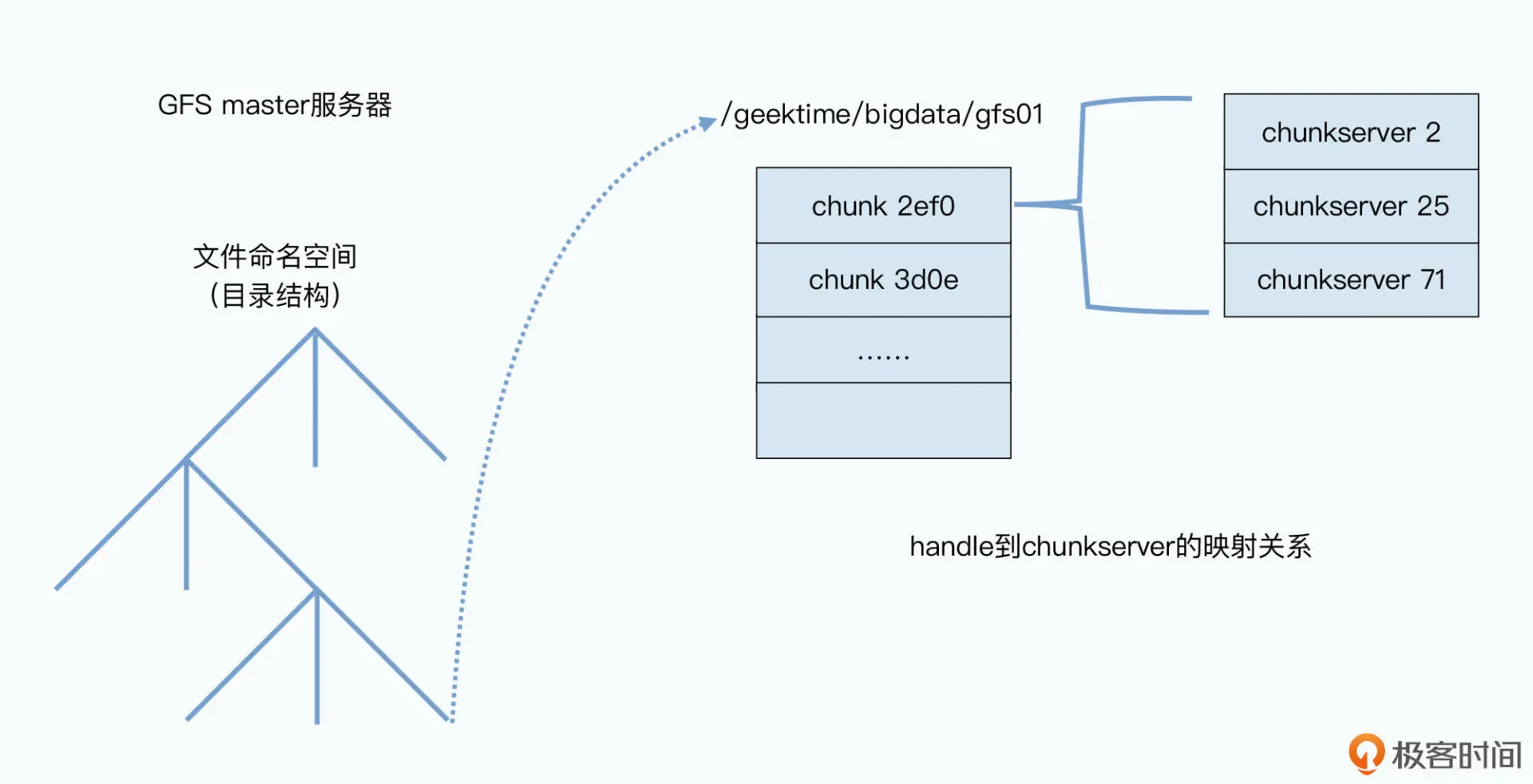
然后,当我们要通过一个客户端去读取 GFS 里面的数据的时候,需要怎么做呢?GFS 会有 以下三个步骤:
客户端先去问 master,我们想要读取的数据在哪里。这里,客户端会发出两部分信息, 一个是文件名,另一个则是要读取哪一段数据,也就是读取文件的 offset 及 length。 因为所有文件都被切成 64MB 大小的一个 chunk 了,所以根据 offset 和 length,我们 可以很容易地算出客户端要读取的数据在哪几个 chunk 里面。于是,客户端就会告诉 master,我要哪个文件的第几个 chunk。
master 拿到了这个请求之后,就会把这个 chunk 对应的所有副本所在的 chunkserver,告诉客户端。
等客户端拿到 chunk 所在的 chunkserver 信息后,客户端就可以直接去找其中任意的 一个 chunkserver 读取自己所要的数据。
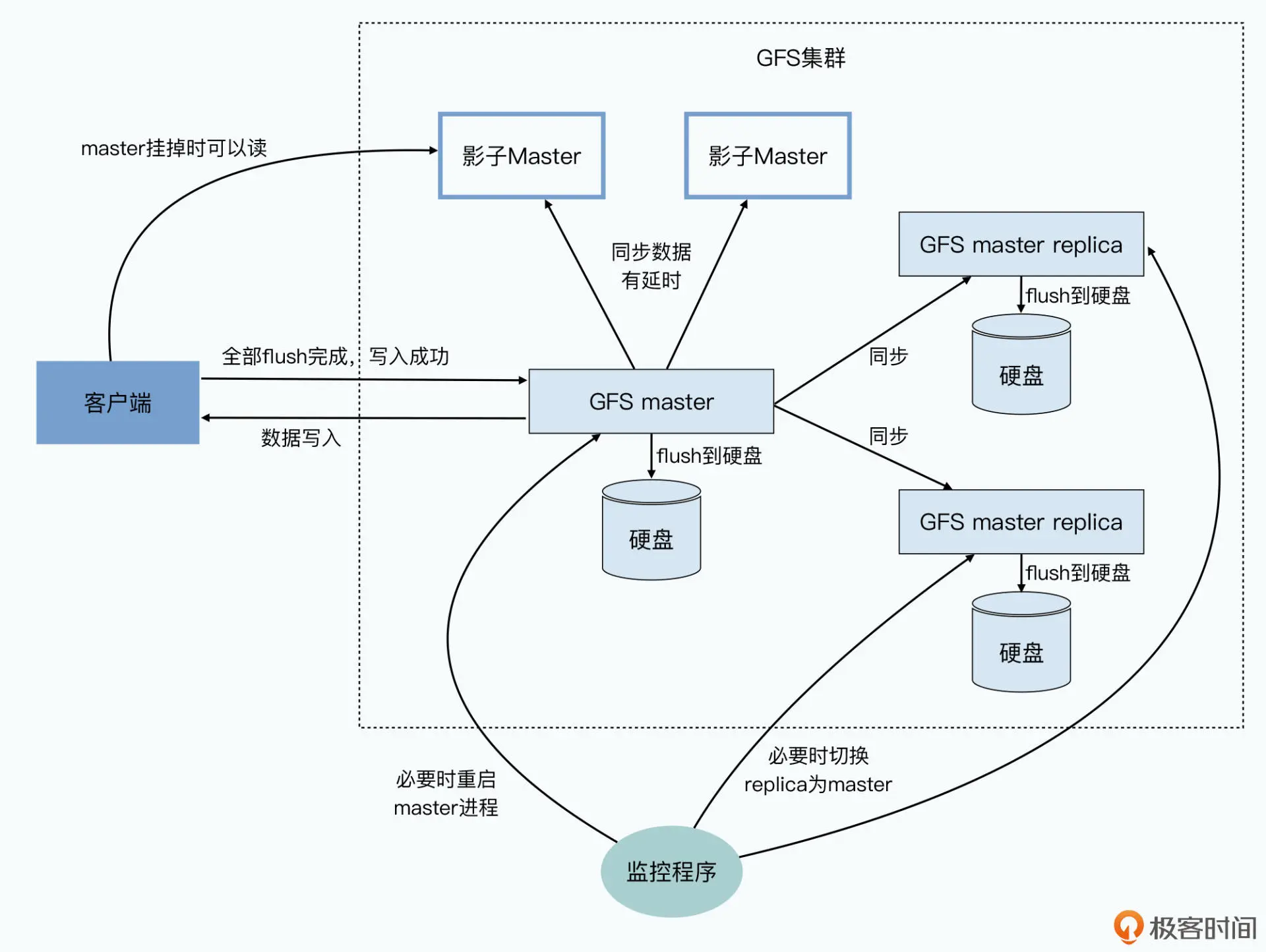
master 的快速恢复性和可用性保障
master 节点的所有数据,都是保存在内存里的。这样,master 的性能才能跟得上 几百个客户端的并发访问。
但是数据放在内存里带来的问题,就是一旦 master 挂掉,数据就会都丢了。所以, master 会通过记录操作日志和定期生成对应的 Checkpoints 进行持久化,也就是写到硬 盘上。
这是为了确保在 master 里的这些数据,不会因为一次机器故障就丢失掉。当 master 节点 重启的时候,就会先读取最新的 Checkpoints,然后重放(replay)Checkpoints 之后的 操作日志,把 master 节点的状态恢复到之前最新的状态。这是最常见的存储系统会用到 的可恢复机制。
GFS 还为 master 准备好了几个“备胎”,也就是另外几台 Backup Master。所有针对 master 的数据操作,都需 要同样写到另外准备的这几台服务器上。只有当数据在 master 上操作成功,对应的操作 记录刷新到硬盘上,并且这几个 Backup Master 的数据也写入成功,并把操作记录刷新到 硬盘上,整个操作才会被视为操作成功。
这种方式,叫做数据的“同步复制”,是分布式数据系统里的一种典型模式。假如你需要 一个高可用的 MySQL 集群,一样也可以采用同步复制的方式,在主从服务器之间同步数 据。
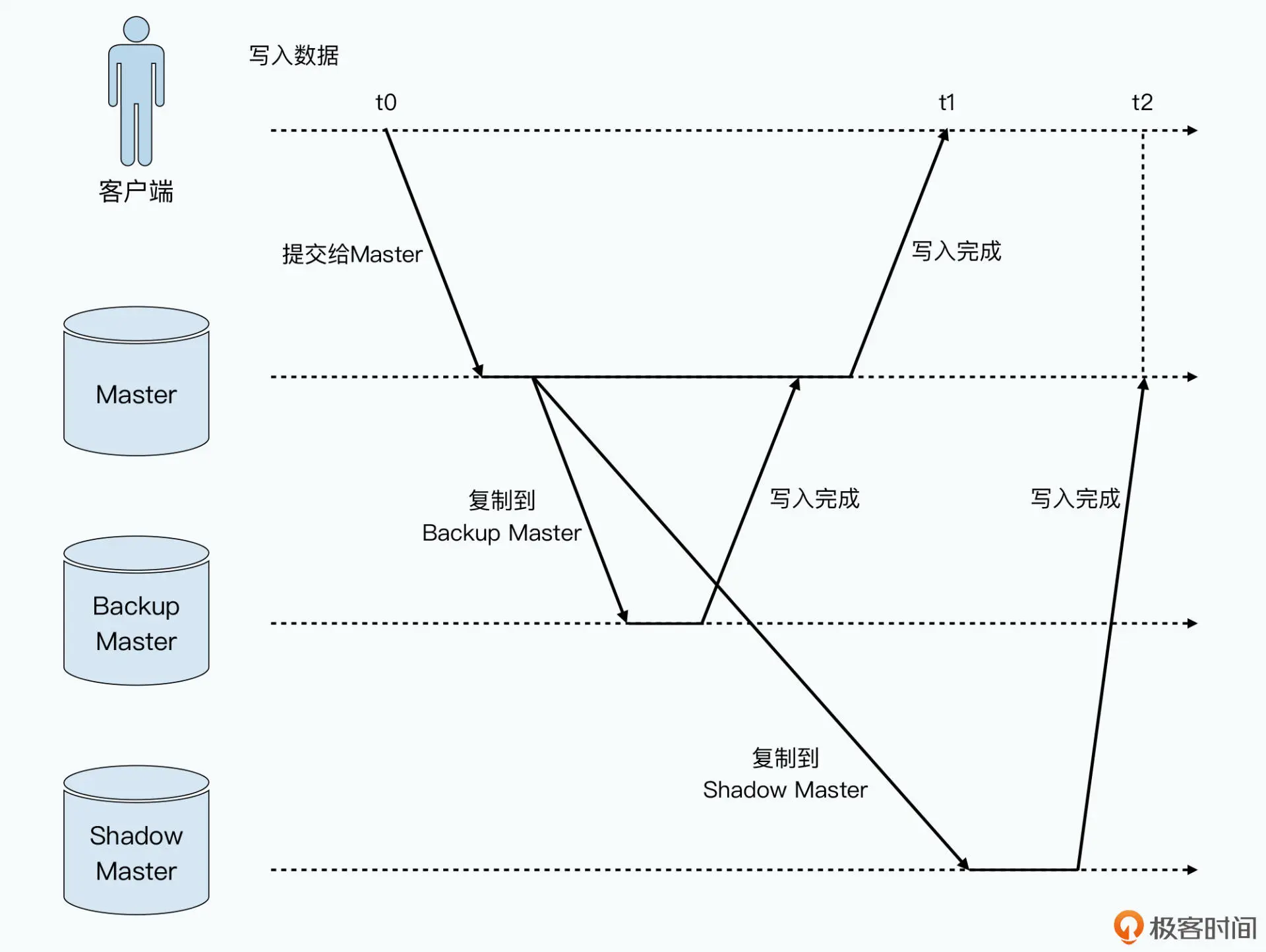
在恢复时间段里,我们可能仍然有几百个客户端程序“嗷嗷待 哺”,希望能够在 GFS 上读写数据。虽然作为单个 master 的设计,这个时候的确是没有 办法去写入数据的。
但是 Google 的工程师还是想了一个办法,让我们这个时候还能够从 GFS 上读取数据。 这个办法就是加入一系列只读的“影子 Master”,这些影子 Master 和前面的备胎不同, master 写入数据并不需要等到影子 Master 也写入完成才返回成功。而是影子 Master 不 断同步 master 输入的写入,尽可能保持追上 master 的最新状态。
这种方式,叫做数据的“异步复制”,是分布式系统里另一种典型模式。异步复制下,影 子 Master 并不是和 master 的数据完全同步的,而是可能会有一些小小的延时。
影子 Master 会不断同步 master 里的数据,不过当 master 出现问题的时候,客户端们就 可以从这些影子 Master 里找到自己想要的信息。当然,因为小小的延时,客户端有很小 的概率,会读到一些过时的 master 里面的信息,比如命名空间、文件名等这些元数据。 但你也要知道,这种情况其实只会发生在以下三个条件都满足的情况下:
第一个,是 master 挂掉了;
第二个,是挂掉的 master 或者 Backup Master 上的 Checkpoints 和操作日志,还没 有被影子 Master 同步完;
第三个,则是我们要读取的内容,恰恰是在没有同步完的那部分操作上;
GFS 的数据写入
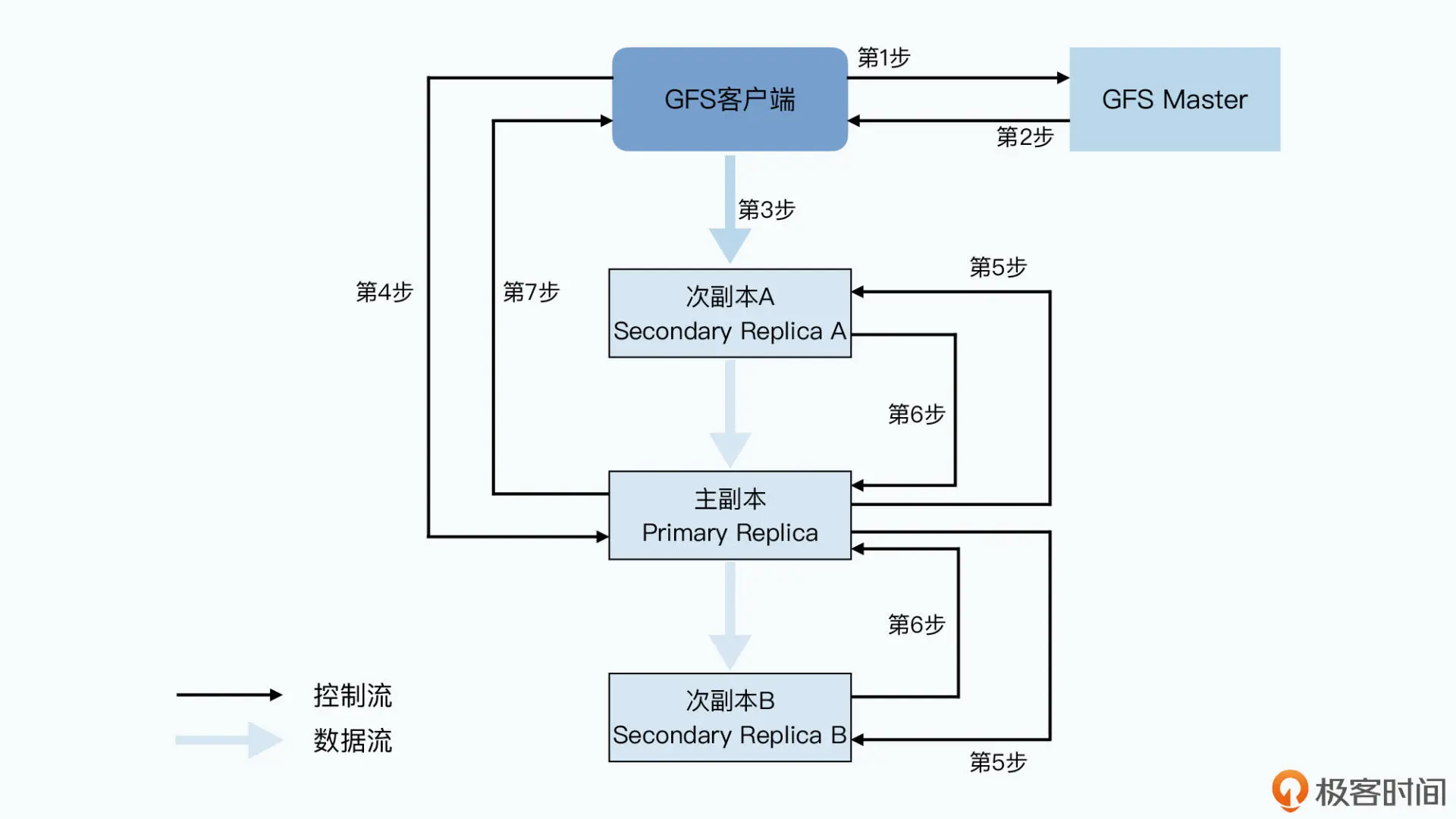
GFS 写入数据的具体步骤
第一步,客户端会去问 master 要写入的数据,应该在哪些 chunkserver 上。
第二步,和读数据一样,master 会告诉客户端所有的次副本(secondary replica)所 在的 chunkserver。这还不够,master 还会告诉客户端哪个 replica 是“老大”,也就 是主副本(primary replica),数据此时以它为准。
第三步,拿到数据应该写到哪些 chunkserver 里之后,客户端会把要写的数据发给所有 的 replica。不过此时,chunkserver 拿到发过来的数据后还不会真的写下来,只会把数 据放在一个 LRU 的缓冲区里。
第四步,等到所有次副本都接收完数据后,客户端就会发送一个写请求给到主副本。我 在上节课一开始就说过,GFS 面对的是几百个并发的客户端,所以主副本可能会收到很 多个客户端的写入请求。主副本自己会给这些请求排一个顺序,确保所有的数据写入是 有一个固定顺序的。接下来,主副本就开始按照这个顺序,把刚才 LRU 的缓冲区里的数 据写到实际的 chunk 里去。
第五步,主副本会把对应的写请求转发给所有的次副本,所有次副本会和主副本以同样 的数据写入顺序,把数据写入到硬盘上。
第六步,次副本的数据写入完成之后,会回复主副本,我也把数据和你一样写完了。
第七步,主副本再去告诉客户端,这个数据写入成功了。而如果在任何一个副本写入数 据的过程中出错了,这个出错都会告诉客户端,也就意味着这次写入其实失败了。
分离控制流和数据流
和之前从 GFS 上读数据一样,GFS 客户端只从 master 拿到了 chunk data 在哪个 chunkserver 的元数据,实际的数据读写都不再需要通过 master。另外,不仅具体的数据 传输不经过 master,后续的数据在多个 chunkserver 上同时写入的协调工作,也不需要 经过 master。
流水线式的网络数据传输
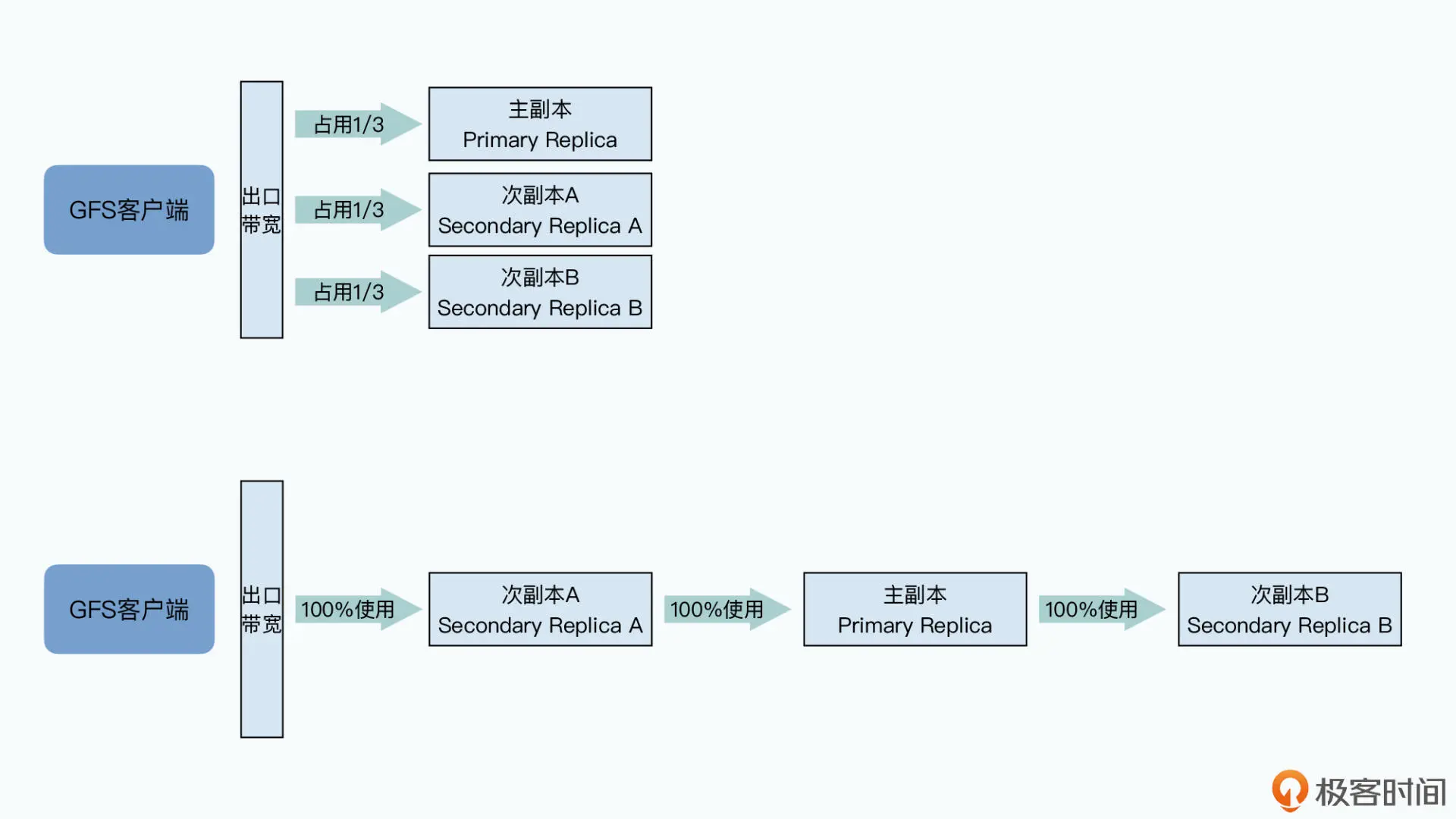
采用了流水线(pipeline)式的网络传输。数据不一定是先给到主副本,而是看 网络上离哪个 chunkserver 近,就给哪个 chunkserver,数据会先在 chunkserver 的缓冲 区里存起来,就是前面提到的第 3 步。但是写入操作的指令,也就是上面的第 4~7 步,则 都是由客户端发送给主副本,再由主副本统一协调写入顺序、拿到操作结果,再给到客户 端的。
之所以要这么做,还是因为 GFS 最大的瓶颈就在网络。如果用一个最直观的想法来进行数 据传输,我们可以把所有数据直接都从客户端发给三个 chunkserver。
但是这种方法的问题在于,客户端的出口网络会立刻成为瓶颈
而在流水线式的传输方式下,客户端可以先把所有数据,传输给到网络里离自己最近的次 副本 A,然后次副本 A 一边接收数据,一边把对应的数据传输给到离自己最近的另一个副 本,也就是主副本。
同样的,主副本可以如法炮制,把数据也同时传输给次副本 B。在这样的流水线式的数据 传输方式下,只要网络上没有拥堵的情况,只需要 10 秒多一点点,就可以把所有的数据从 客户端,传输到三个副本所在的 chunkserver 上。
为什么客户端传输数据,是先给离自己最近的次副本 A,而不是先给主副本呢?
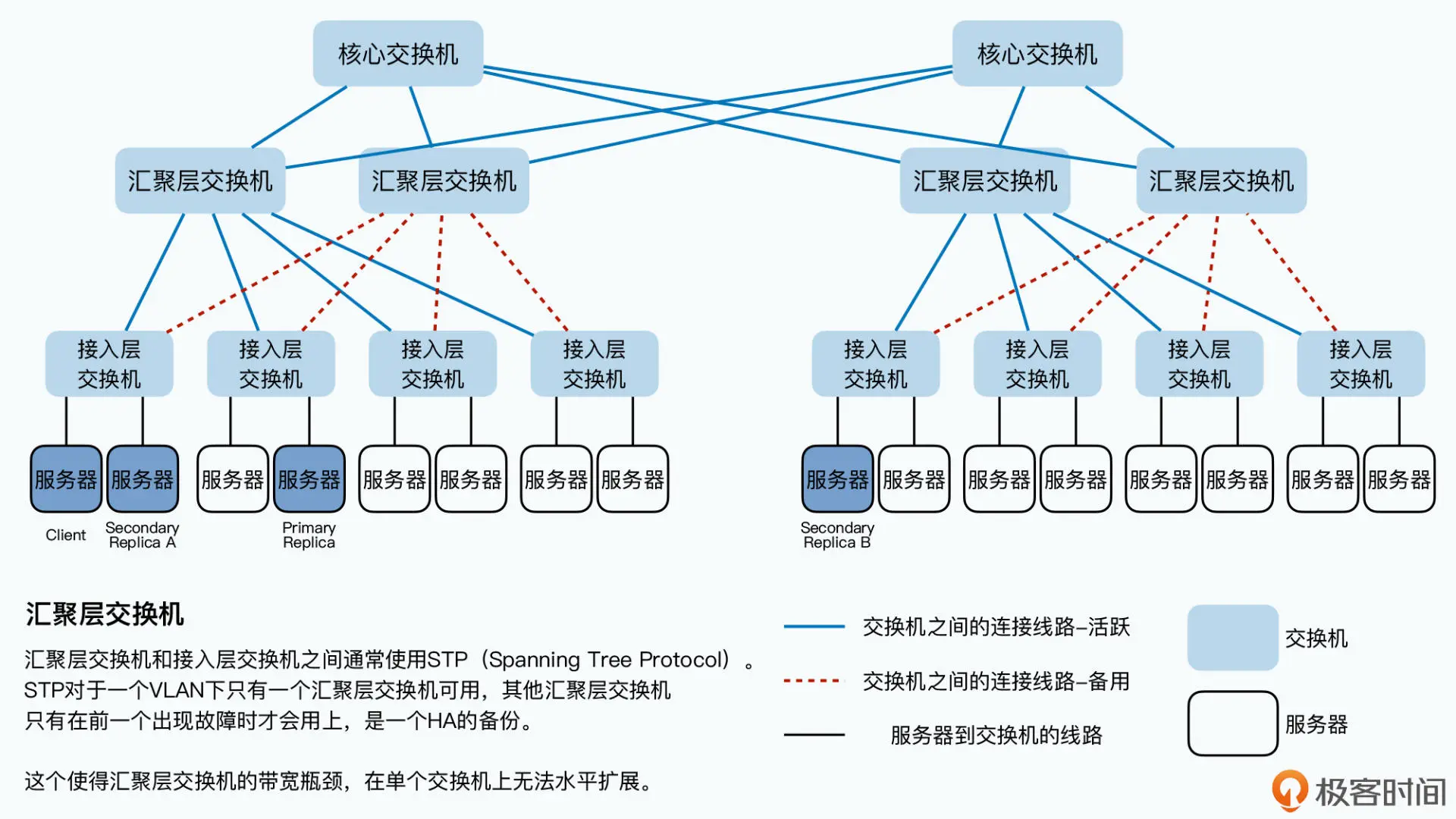
我们几百台服务器所在的数据中心,一般都是通过三层交换机连通起来的:
同一个机架(Rack)上的服务器,都会接入到一台接入层交换机(Access Switch) 上;
各个机架上的接入层交换机,都会连接到某一台汇聚层交换机(Aggregation Switch) 上;
而汇聚层交换机,再会连接到多台核心交换机(Core Switch)上。
那么根据这个网络拓扑图,你会发现,两台服务器如果在同一个机架上,它们之间的网络 传输只需要通过接入层的交换机即可。在这种情况下,除了两台服务器本身的网络带宽之 外,它们只会占用所在的接入层交换机的带宽。
但是,如果两台服务器不在一个机架,乃至不在一个 VLAN 的情况下,数据传输就要通过 汇聚层交换机,甚至是核心交换机了。而如果大量的数据传输,都是在多个不同的 VLAN 之间进行的,那么汇聚层交换机乃至核心交换机的带宽,就会成为瓶颈。
所以我们再回到之前的链式传输的场景,GFS 最大利用网络带宽,同时又减少网络瓶颈的 选择就是这样的:
首先,客户端把数据传输给离自己“最近”的,也就是在同一个机架上的次副本 A 服务 器;
然后,次副本 A 服务器再把数据传输给离自己“最近”的,在不同机架,但是处于同一 个汇聚层交换机下的主副本服务器上;
最后,主副本服务器,再把数据传输给在另一个汇聚层交换机下的次副本 B 服务器。
这样的传输顺序,就最大化地利用了每台服务器的带宽,并且减少了交换机的带宽瓶颈。 而如果我们非要先把数据从客户端传输给主副本,再从主副本传输到次副本 A,那么同样 的数据就需要多通过汇聚层交换机一次,从而就占用了更多的汇聚层交换机的资源。
独特的 Snapshot 操作
GFS 就专门为文件复制设计了一个 Snapshot 指令,当客户端通过这个指令进行文 件复制的时候,这个指令会通过控制流,下达到主副本服务器,主副本服务器再把这个指 令下达到次副本服务器。不过接下来,客户端并不需要去读取或者写入数据,而是各个 chunkserver 会直接在本地把对应的 chunk 复制一份。
这样,数据流就完全不需要通过网络传输了。
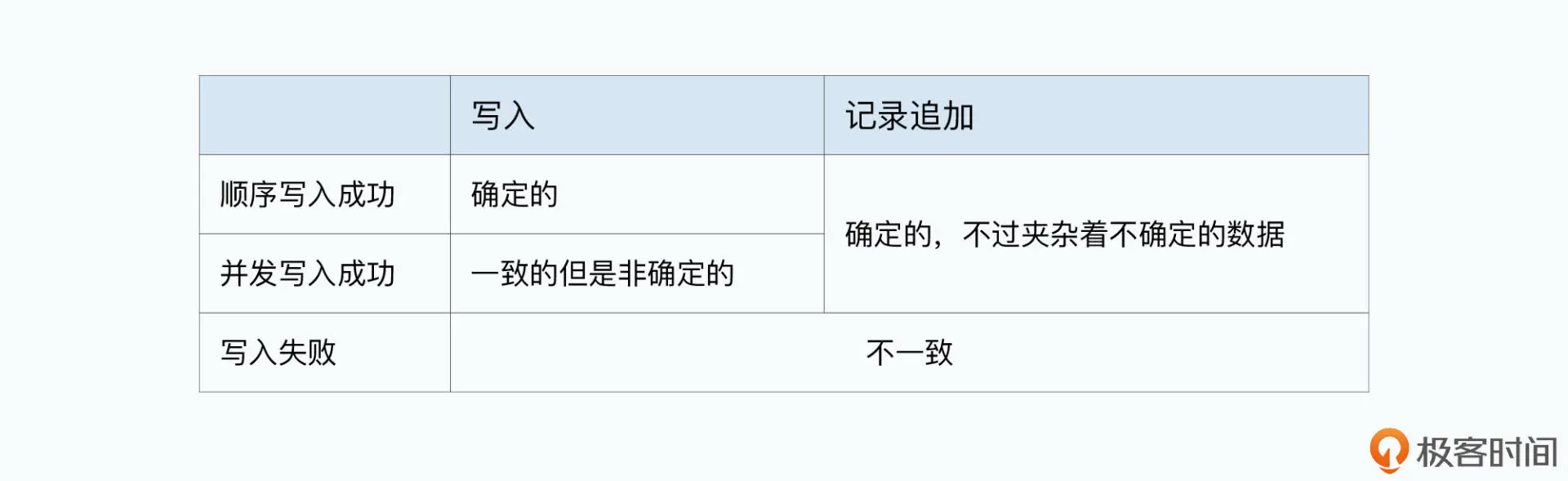
放宽数据一致性的要求
在 GFS 里面,主要定义了对一致性的两个层级的概念:
第一个,就叫做“一致的(Consistent)”。这个就是指,多个客户端无论是从主副本 读取数据,还是从次副本读取数据,读到的数据都是一样的。
第二个,叫做“确定的(Defined)”。这个要求会高一些,指的是对于客户端写入到 GFS 的数据,能够完整地被读到。可能看到这个定义,你还是不清楚,没关系,我下面 会给你详细讲解“确定的”到底是个什么问题。
首先,如果数据写入失败,GFS 里的数据就是不一致的。
其次,如果客户端的数据写入是顺序的,并且写入成功了,那么文件里面的内容就是确定的。
但是,如果由多个客户端并发写入数据,即使写入成功了,GFS 里的数据也可能会进入一个一致但是非确定的状态
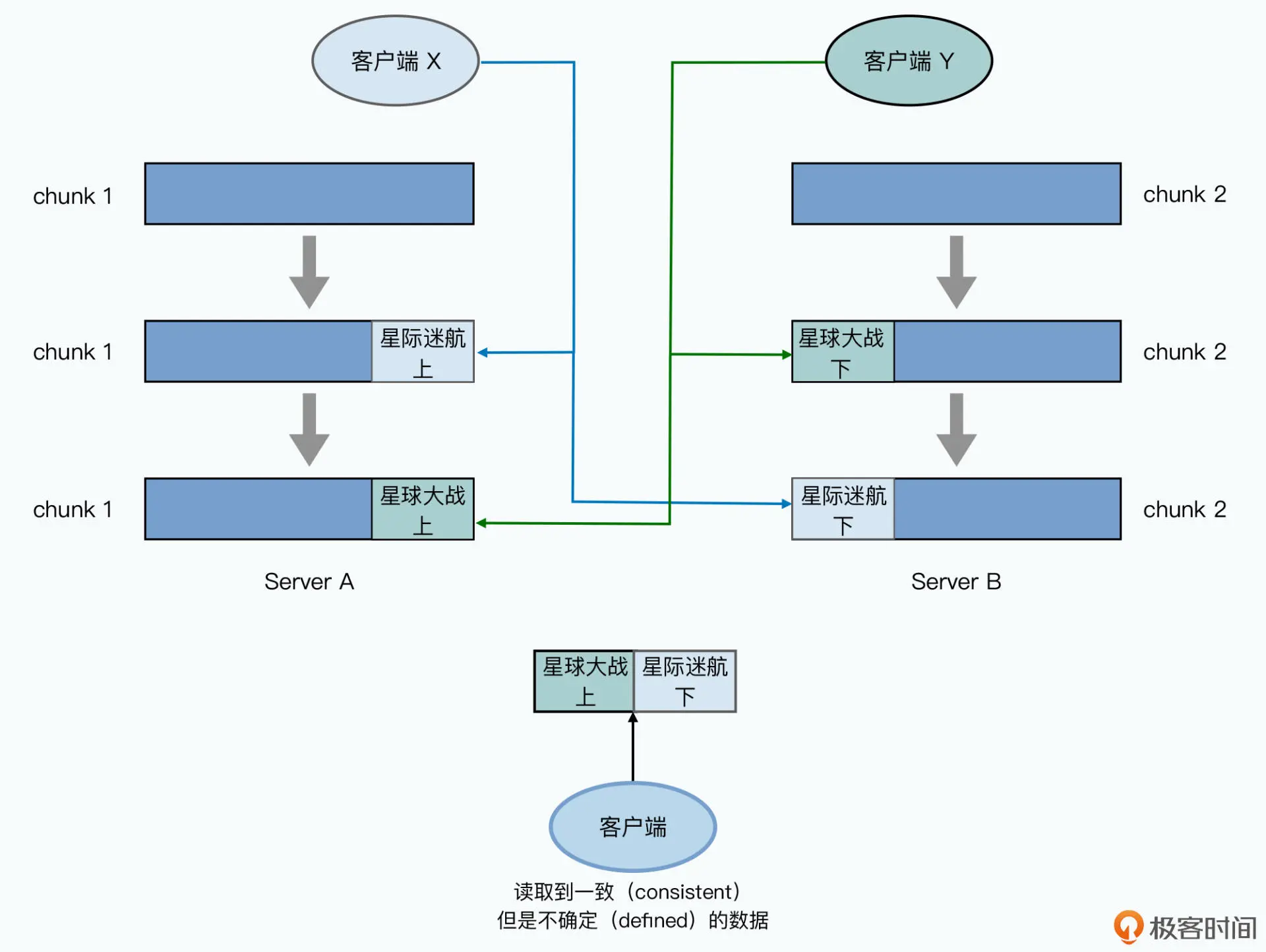
为什么 GFS 的数据写入会出现一致但是非确定的状态呢?这个来自于两个因素。
第一种因素是在 GFS 的数据读写中,为了减轻 Master 的负载,数据的写入顺序并不需要 通过 Master 来进行协调,而是直接由存储了主副本的 chunkserver,来管理同一个 chunk 下数据写入的操作顺序。
第二种因素是随机的数据写入极有可能要跨越多个 chunk。
这个一致但是非确定的状态,是因为随机的数据写入,没有原子性(Atomic)或者 事务性(Transactional)。如果想要随机修改 GFS 上的数据,一般会建议使用方在客户端 的应用层面,保障数据写入是顺序的,从而可以避免并发写入的出现。
追加写入的“至少一次”的保障
实际上,这是因为随机写入并不是 GFS 设计的主要的数据写入模式,GFS 设计了一个专门 的操作,叫做记录追加(Record Appends)。这是 GFS 希望我们主要使用的数据写入的 方式,而且它是原子性(Atomic)的,能够做到在并发写入时候是基本确定的。
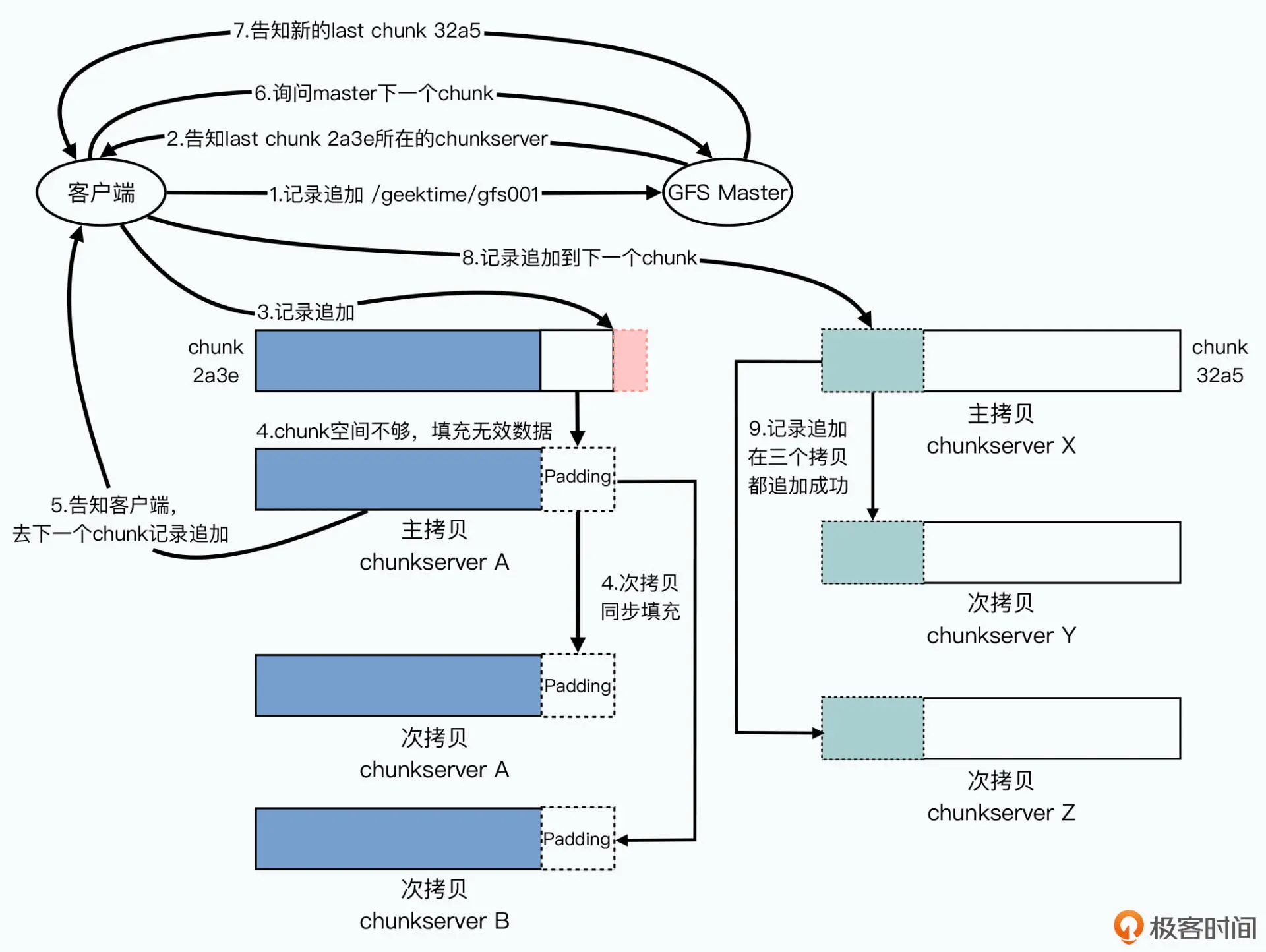
GFS 的记录追加的写入过程,和上一讲的数据写入几乎一样。它们之间的差别主要在于, GFS 并不会指定在 chunk 的哪个位置上写入数据,而是告诉最后一个 chunk 所在的主副 本服务器,“我”要进行记录追加。
这个时候,主副本所在的 chunkserver 会做这样几件事情:
检查当前的 chunk 是不是可以写得下现在要追加的记录。如果写得下,那么就把当前的 追加记录写进去,同时,这个数据写入也会发送给其他次副本,在次副本上也写一遍。
如果当前 chunk 已经放不下了,那么它先会把当前 chunk 填满空数据,并且让次副本 也一样填满空数据。然后,主副本会告诉客户端,让它在下一个 chunk 上重新试验。这 时候,客户端就会去一个新的 chunk 所在的 chunkserver 进行记录追加。
因为主副本所在的 chunkserver 控制了数据写入的操作顺序,并且数据只会往后追加, 所以即使在有并发写入的情况下,请求也都会到主副本所在的同一个 chunkserver 上排 队,也就不会有数据写入到同一块区域,覆盖掉已经被追加写入的数据的情况了。
而为了保障 chunk 里能存的下需要追加的数据,GFS 限制了一次记录追加的数据量是 16MB,而 chunkserver 里的一个 chunk 的大小是 64MB。所以,在记录追加需要在 chunk 里填空数据的时候,最多也就是填入 16MB,也就是 chunkserver 的存储空间最 多会浪费 1/4
如果在主副本上写入成功了,但是在次副本上写入失败了怎么办呢?这样不是还会出现数据不一致的情况吗?
其实在这个时候,主副本会告诉客户端数据写入失败,然后让客户端重试。不过客户端发 起的重试,并不是在原来的位置去写入数据,而是发起一个新的记录追加操作。这个时 候,可能已经有其他的并发追加写入请求成功了,那么这次重试会写入到更后面。
我们可以一起来看这样一个例子:有三个客户端 X、Y、Z 并发向同一个文件进行记录追 加,写入数据 A、B、C,对应的三个副本的 chunkserver 分别是 Q、P、R。
主副本先收到数据 A 的记录追加,在主副本和次副本上进行数据写入。在 A 写入的同时, B,C 的记录追加请求也来了,这个时候写入会并行进行,追加在 A 的后面。
这个时候,A 的写入在某个次副本 R 上失败了,于是主副本告诉客户端去重试;同时,客 户端再次发起记录追加的重试,这次的数据写入,不在 A 原来的位置,而会是在 C 后面。 如此一来,在 B 和 C 的写入,以及 A 的重试完成之后,我们可以看到:
所以在这个记录追加的场景下,GFS 承诺的一致性,叫做“至少一次(At Least Once)”。也就是写入一份数据 A,在重试的情况下,至少会完整地在三个副本的同一个 位置写入一次。但是也可能会因为失败,在某些副本里面写入多次。那么,在不断追加数 在 Q 和 P 上,chunkserver 里面的数据顺序是 A-B-C-A;
但是在 R 上,chunkserver 里面的数据顺序是 N/A-B-C-A;
也就是 Q 和 P 上,A 的数据被写入了两次,而在 R 上,数据里面有一段是有不可用的 脏数据。
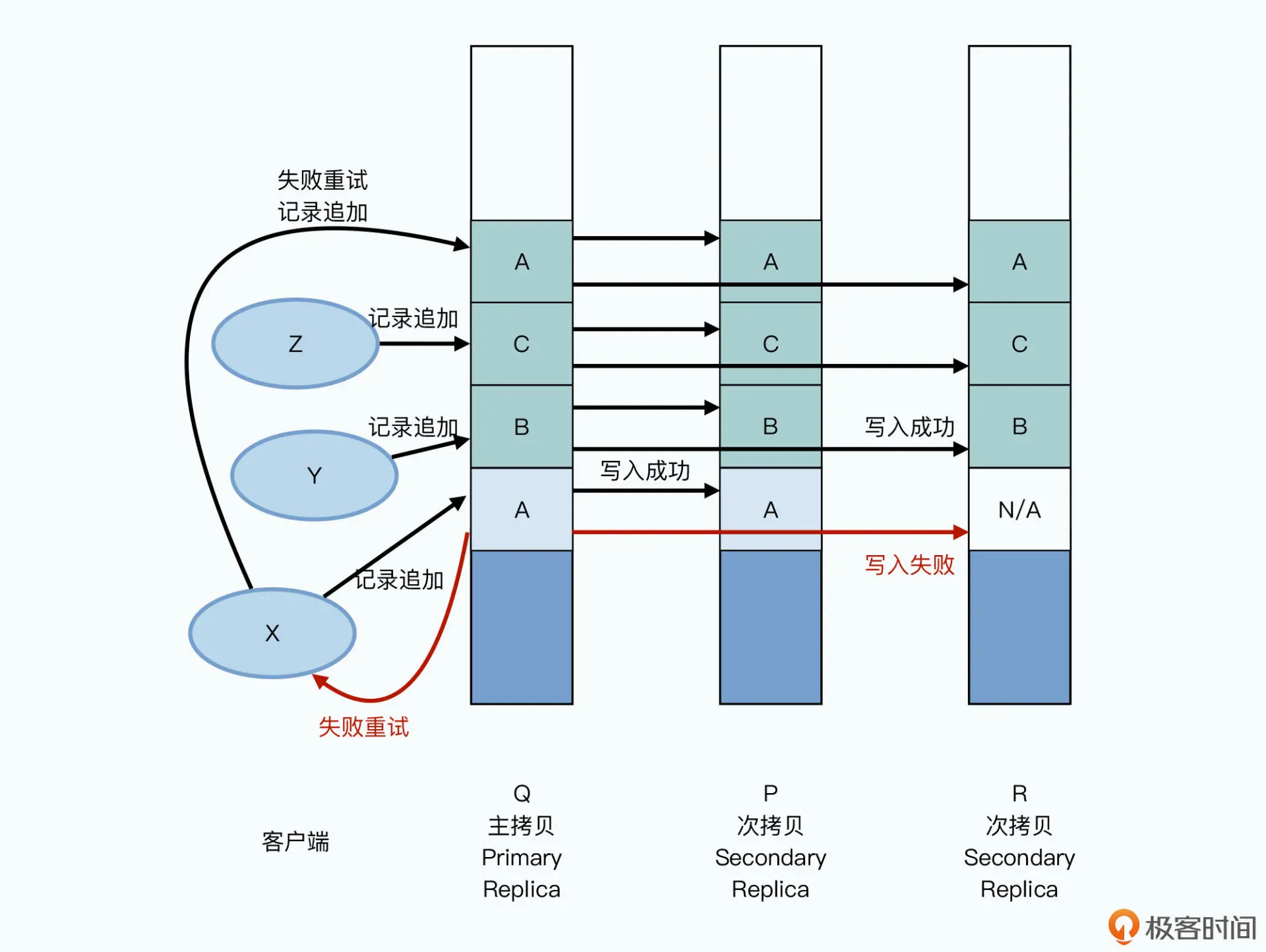
所以在这个记录追加的场景下,GFS 承诺的一致性,叫做“至少一次(At Least Once)”。也就是写入一份数据 A,在重试的情况下,至少会完整地在三个副本的同一个 位置写入一次。但是也可能会因为失败,在某些副本里面写入多次。那么,在不断追加数据的情况下,你会看到大部分数据都是一致的,并且是确定的,但是整个文件中,会夹杂 着少数不一致也不确定的数据。
解决一致性的机制
事实上,GFS 的客户端里面自带了对写入的数据去添加校验和(checksum),并在读取 的时候计算来验证数据完整性的功能。而对于数据可能重复写入多次的问题,你也可以对 每一条要写入的数据生成一个唯一的 ID,并且在里面带上当时的时间戳。这样,即使这些 日志顺序不对、有重复,你也可以很容易地在你后续的数据处理程序中,通过这个 ID 进行 排序和去重。
而这个“至少一次”的写入模型也带来了两个巨大的好处。
第一是高并发和高性能,这个设计使得我们可以有很多个客户端并发向同一个 GFS 上的文 件进行追加写入,而高性能本身也是我们需要分布式系统的起点。
第二是简单,GFS 采用了一个非常简单的单 master server,多个 chunkserver 架构,所 有的协调动作都由 master 来做,而不需要复杂的一致性模型。毕竟,2003 年我们只有极 其难以读懂的 Paxos 论文,Raft 这样的分布式共识算法要在 10 年之后的 2013 年才会诞 生。而简单的架构设计,使得系统不容易出 Bug,出了各种 Bug 也更容易维护。
参考链接
https://time.geekbang.org/column/article/421579
文档信息
- 本文作者:ironartisan
- 本文链接:https://ironartisan.github.io/2022/06/13/%E5%A4%A7%E6%95%B0%E6%8D%AE-1.GFS%E8%A7%A3%E8%AF%BB/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)