
MapReduce:一个分布式的 Bash
要针对存放在上千个节点的 GFS 上的数据,进行数据处理,你会怎么做?你会有哪些计算方式的需求呢?
最直接的方式就是在很多台机器上,同时来做运算,也就是进行并行计算, 这样可以利用我们有上千个节点的优势。而需要的计算方式,抽象来说,无非是三种情况。
- 第一种,是对所有的数据,我们都只需要单条数据就能完成处理。比如,我们有很多网页的内容,我们要从里面提取出来每一个网页的标题。这样的计算可以完全并行化。
- 第二种,是需要汇总多条数据才能完成计算。比如,要统计日志里面某个 URL 被访问了多少次,只需要简单累加就可以了。或者我们需要更复杂一些的操作,比如统计某个 URL 下面的唯一用户数。而对于这里的第二种情况,我们就需要将所有相同 URL 的数据,搬运到同一个计算节点上进行处理。不过,在搬运之后,不同的 URL 还是可以放到不同的节点进行处理的。
- 自然是一、二两种情况的组合了。比如,我们先从网页数据里面,提取出网页的URL 和标题,然后根据标题里面的关键字,统计特定关键字出现在多少个不同的 URL 里面,这就需要同时采用一二这两种情况的操作。
当然,我们可以有更复杂的数据操作,但是这些动作也都可以抽象成前面的两个动作的组 合。因为无非,我们要处理的数据要么是完全独立的,要么需要多条数据之间的依赖。实 际上,前面的第一种动作,就是 MapReduce 里面的 Map;第二种动作,就是MapReduce 里面的 Reduce;而搬运的过程,就是 Shuffle。
MapReduce 编程模型
MapReduce 的编程模型非常简单,对于想要利用 MapReduce 框架进行数据处理的开发 者来说,只需要实现一个 Map 函数,一个 Reduce 函数。
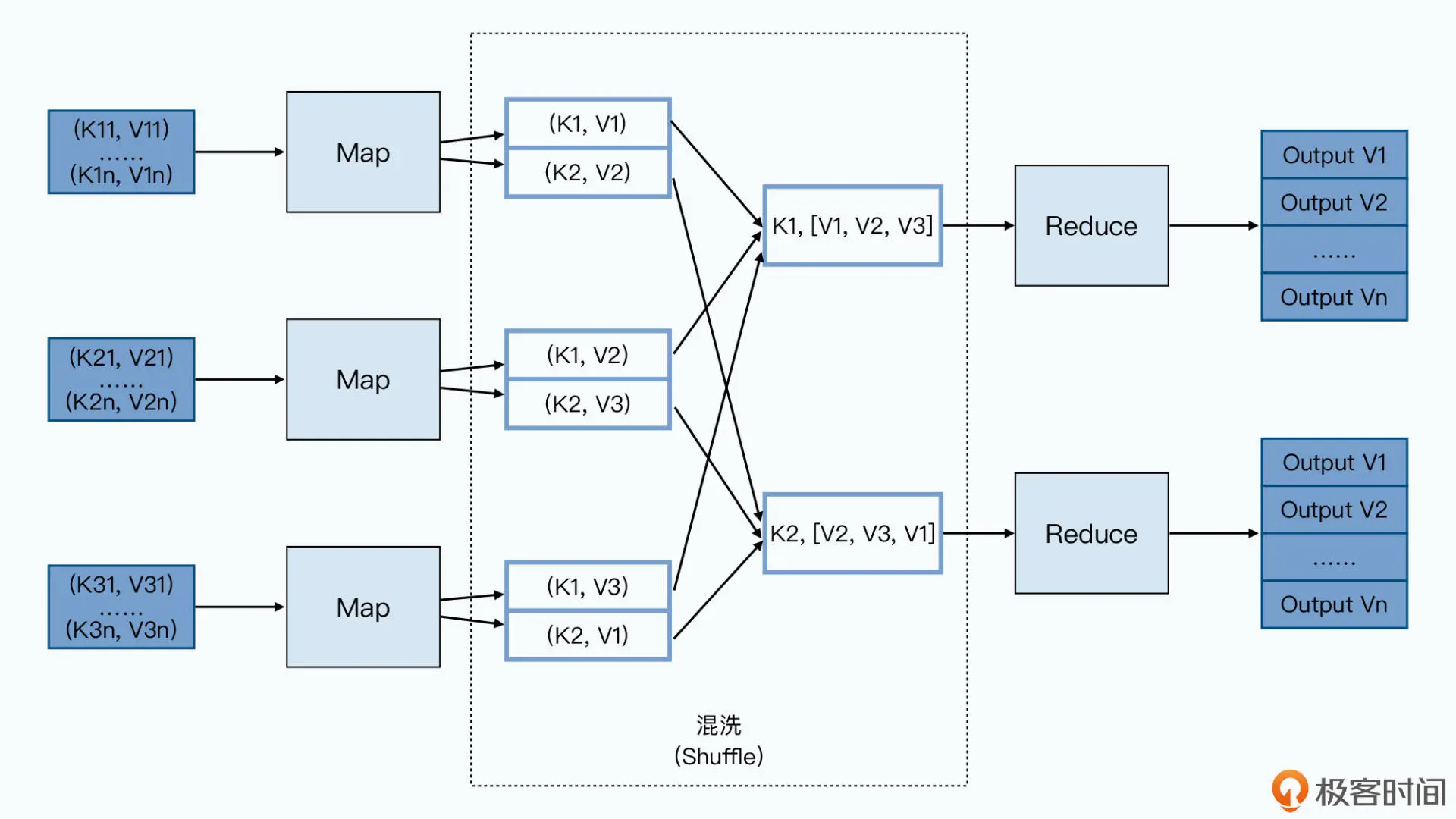
Map 函数,顾名思义就是一个映射函数,它会接受一个 key-value 对,然后把这个 key- value 对转换成 0 到多个新的 key-value 对并输出出去。
map (k1, v1) -> list (k2, v2)
Reduce 函数,则是一个化简函数,它接受一个 Key,以及这个 Key 下的一组 Value,然 后化简成一组新的值 Value 输出出去。
reduce (k2, list(v2)) -> list(v3)
而在 Map 函数和 Reduce 函数之外,开发者还需要指定一下输入输出文件的路径。输入 路径上的文件内容,会变成一个个键值对给到 Map 函数。而 Map 函数会运行开发者写好 的映射逻辑,把数据作为新的一组键值对输出出去。
Map 函数的输出结果,会被整个 MapReduce 程序接手,进行一个叫做混洗的操作。混洗 会把 Map 函数输出的所有相同的 Key 的 Value 整合到一个列表中,给到 Reduce 函数。 并且给到 Reduce 函数的 Key,在每个 Reduce 里,都是按照 Key 排好序的。
MapReduce 的应用场景
别看在 MapReduce 框架下,你只能定义简简单单的一个 Map 和一个 Reduce 函数,实 际上它能够实现的应用场景,论文里可列了不少,包括以下六个:
- 分布式 grep;
- 统计 URL 的访问频次;
- 反转网页 - 链接图;
- 分域名的词向量;
- 生成倒排索引;
- 分布式排序。
主要来关注一下前两个场景的用途,看看最简单的两个场景是如何通过 MapReduce 来实现的。然后,我们可以把其中的第二个场景和 Unix 下的 Bash 脚本对 应起来,来理解为什么我说 MapReduce 的设计思想,就是来自于 Unix 下的 Bash 和管 道。
分布式 grep
在日常使用 Linux 的过程中,相信你没少用过 grep 这个命令。早年间,在出现各种线上 故障的时候,我常常会通过 grep 来检索各种应用和 Web 服务器的错误日志,去排查线上 问题,如下所示:
grep "error" access.log > /tmp/error.log.1
在单台 Linux 服务器上,我们当然可以用一个 grep 命令。那么如果有很多台服务器,我 们怎么才能知道在哪台机器上会有我们需要的错误日志呢?
最简单的办法,当然就是在每台服务器上,都执行一遍相同的 grep 命令就好了。这个动作 就是所谓的“分布式 grep”,在整个 MapReduce 框架下,它其实就是一个只有 Map, 没有 Reduce 的任务。
在真实的应用场景下,“分布式 grep”当然不只是用来检索日志。对于谷歌这个全球最大 搜索引擎来说,这是完美地用来做网页预处理的方案。通过网络爬虫抓取到的网页内容, 你都可以直接存到 GFS 上,这样你就可以撰写一个 Map 函数,从 HTML 的网页中,提取 网页里的标题、正文,以及链接。然后你可以再去撰写一个 Map 函数,对标题和正文进行 关键词提取。
这些一步步的处理结果,还会作为后续的反转网页 - 链接图、生成倒排索引等 MapReduce 任务的输入数据。
实际上,“分布式 grep”就是一个分布式抽取数据的抽象,无论是像 grep 一样通过一个 正则表达式来提取内容,还是用复杂的算法和策略从输入中提取内容,都可以看成是一 种“分布式 grep”。而在 MapReduce 这个框架下,你只需要撰写一个 Map 函数,并不 需要关心数据存储在具体哪台机器上,也不需要关心哪台机器的硬件或者网络出了问题。
统计 URL 的访问频次
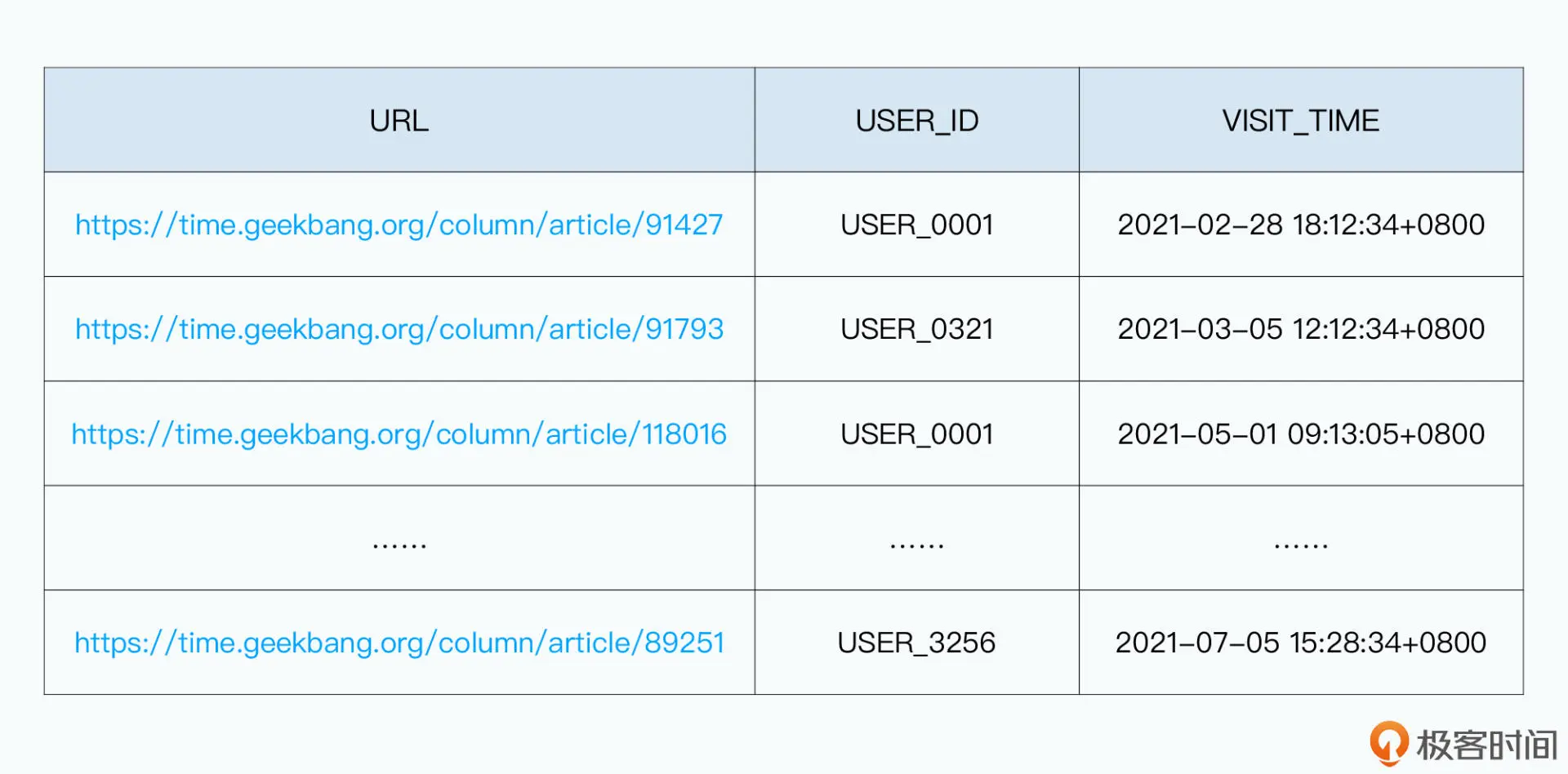
下面放了一个表格,我们把它叫做 url_visit_logs 。在这个表格里面有三个字段,分别是:
- URL,记录用户具体是看专栏里的哪一篇文章;
- USER_ID,记录具体是哪一个用户访问;
- VISIT_TIME,记录用户访问的具体时间。
那么,作为像谷歌这样的搜索引擎,它通常都会有统计网页访问频次的需求。访问频次高 的网页,通常可以被认为是内容质量高,会在搜索结果的排名里面,排在更前面的位置。
如果只是极客时间的网页,我们可以把这张表里面的数据放在数据库里面,通过一句 SQL 就可以完成了:
SELECT URL, COUNT(*) FROM url_visit_logs GROUP BY URL ORDER BY URL
但是,如果考虑全网的所有数据网页访问日志,数据库就肯定放不下了。我们可以把这些 日志以文件的形式放在 GFS 上,然后通过 MapReduce 来做数据统计。 Map 函数很简单,它拿到的输入数据是这样的:
- Key 就是单条日志记录在文件中的行号;
- Value 就是对应单条记录的字符串,不同字段之间以 Tab 分割。

Map 函数只需要通过一个 split 或者类似的函数,对 Value 进行分割,拿到 URL,然后输 出一个 List 的 key-value 对。在当前的场景下,这个 List 只有一个 key-value 对
- 输出的 Key 就是 URL;
- 输出的 Value 为空字符串。

这个 URL 肯定不只被访问了一次,因为 MapReduce 框架会把所有相同 URL 的 Map 的 输出记录,都混洗给到同一个 Reduce 函数里。所以在这里,Reduce 函数拿到的输入数 据是这样的:
- Key 就是 URL;
- 一个 List 的 Value,里面的每一项都是空字符串。

Reduce 函数的逻辑也非常简单,就是把 list 里面的所有 Value 计个数,然后和前面的 Key 拼装到一起,并输出出去。Reduce 函数输出的 list 里,也只有这一个元素。

这样一个 MapReduce 的过程,就和我们之前通过 SELECT + GROUP BY 关键字执行的 SQL 起到了同样的作用。
事实上,SQL 是一种申明式的语言,MapReduce 是我们的实现过程,后面我们在讲解 Hive 论文时候,你就会发现,Hive 的 HQL 就是通过一个个 MapReduce 程序来实现 的。而前面的整个 MapReduce 的过程,其实用一段 Bash 代码也可以实现。 其中的 Map 过程,类似于 SELECT 关键字,从输入数据中提取出需要使用的 Key 和 Value 字段。
MapReduce 框架完成的混洗过程,类似于 SQL 中的 GROUP BY 关键字,根据相同的 Key,把 Map 中选择的数据混洗到一起。
最后的 Reduce 过程,就是先对混洗后数据中的 Value,执行了 COUNT 这个函数,然 后再将 Key 和 COUNT 执行的结果拼装到一起,输出为最后的结果。
cat $input |
awk '{print $1}' |
sort |
uniq -c > $output
在这段 Bash 代码中: 如果和 MapReduce 框架对照起来,你会发现:
读写 HDFS 文件的内容,对应着 cat 命令和标准输出; 对于数据进行混洗,对应着 sort 命令; 整个框架,不同阶段之间的数据传输,用的就是标准的输入输出管道。
那么,对于开发者来说,只要自己实现 Map 和 Reduce 函数就好了,其他都不需要关 心。而对于实现 MapReduce 的底层框架代码,也可以映射到读取、外部排序、输出,以 及通过网络进行跨机器的数据传输就好了。在这个设计框架下,每一个组件都只需要完成 自己的工作,整个框架就能很容易地串联起来了。
作为一个框架,MapReduce 设计的一个重要思想,就是让使用者意识不到“分布式”这 件事情本身的存在。从设计模式的角度,MapReduce 框架用了一个经典的设计模式,就 是模版方法模式。而从设计思想的角度,MapReduce 的整个流程,类似于 Unix 下一个个 命令通过管道把数据处理流程串接起来。
MapReduce 的数据处理设计很直观,并不难理解。Map 帮助我们解决了并行在很多台机 器上处理互相之间没有依赖关系的数据;而 Reduce 则用来处理互相之间有依赖关系的数 据,我们可以通过 MapReduce 框架自带的 Shuffle 功能,通过排序来根据设定好的 Key 进行分组,把相同 Key 的数据放到同一个节点上,供 Reduce 处理。
cat 相当于我们 MapReduce 框架从 HDFS 读取数据; awk 的脚本,是我们实现的 Map 函数; sort 相当于 MapReduce 的混洗,只是这个混洗是在本机上执行的; 而最后的 uniq -c 则是实现了 Reduce 函数,在排好序的数据下,完成了同一 URL 的去 重计数的工作。
MapReduce 框架的三个挑战
要想让写 Map 和 Reduce 函数的人不需要关心“分布式”的存在,那么 MapReduce 框 架本身就需要解决好三个很重要的问题:
第一个,自然是如何做好各个服务器节点之间的“协同”,以及解决出现各种软硬件问 题后的“容错”这两部分的设计。
第二个,是性能问题。 MapReduce 框架一样非常容易遇到网络性能瓶颈。尽量充分利用 MapReduce 集群的 计算能力,并让整个集群的性能可以随硬件的增加接近于线性增长,可以说是非常大的 一个挑战。
最后一个,还是要回到易用性。Map 函数和 Reduce 函数最终还是运行在多个不同的机 器上的,并且在 Map 和 Reduce 函数中还会遇到各种千奇百怪的数据。当我们的程序 在遭遇到奇怪的数据出错的时候,我们需要有办法来进行 debug。
而谷歌在论文里面,也通过第三部分的“MapReduce 的实现”,以及第四部分 的“MapReduce 的完善”,很好地回答了怎么解决这三个问题。下面,我们就来具体看 看,论文里是怎么讲的。
MapReduce 的协同
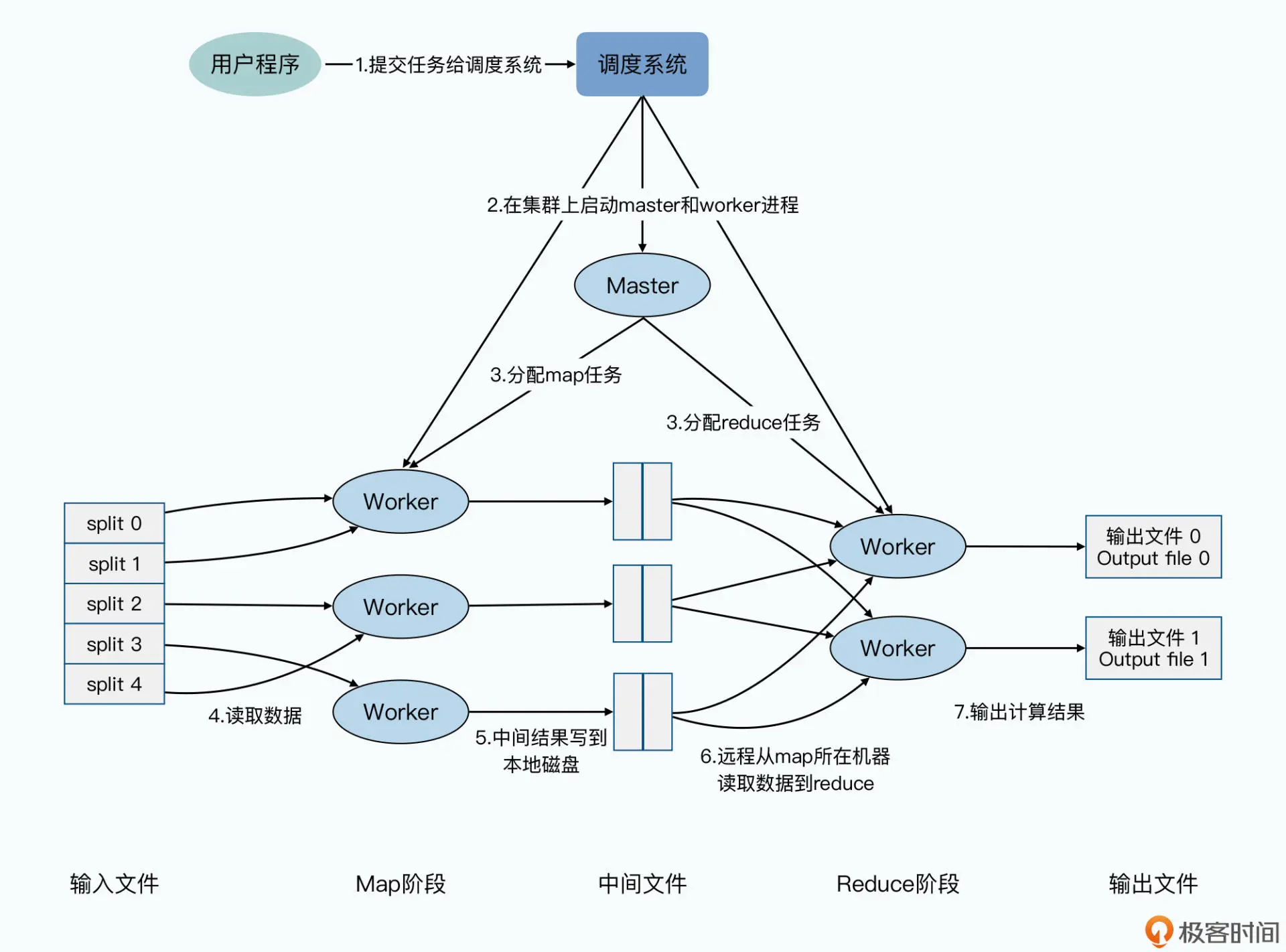
一个 MapReduce 的集群,通常就是之前的分布式存储系统 GFS 的集群。在这个集群里, 本身会有一个调度系统(Scheduler)。当我们要运行一个 MapReduce 任务的时候,其 实就是把整个 MapReduce 的任务提交给这个调度系统,让这个调度系统来分配和安排 Map 函数和 Reduce 函数,以及后面会提到的 master 在不同的硬件上运行。
在 MapReduce 任务提交了之后,整个 MapReduce 任务就会按照这样的顺序来执行。
第一步,你写好的 MapReduce 程序,已经指定了输入路径。所以 MapReduce 会先找到 GFS 上的对应路径,然后把对应路径下的所有数据进行分片(Split)。每个分片的大小通 常是 64MB,这个尺寸也是 GFS 里面一个块(Block)的大小。接着,MapReduce 会在 整个集群上,启动很多个 MapReduce 程序的复刻(fork)进程。
第二步,在这些进程中,有一个和其他不同的特殊进程,就是一个 master 进程,剩下的 都是 worker 进程。然后,我们会有 M 个 map 的任务(Task)以及 R 个 reduce 的任 务,分配给这些 worker 进程去进行处理。这里的 master 进程,是负责找到空闲的(idle)worker 进程,然后再把 map 任务或者 reduce 任务,分配给 worker 进程去处理。
这里你需要注意一点,并不是每一个 map 和 reduce 任务,都会单独建立一个新的 worker 进程来执行。而是 master 进程会把 map 和 reduce 任务分配给有限的 worker, 因为一个 worker 通常可以顺序地执行多个 map 和 reduce 的任务。
第三步,被分配到 map 任务的 worker 会读取某一个分片,分片里的数据就像上一讲所说 的,变成一个个 key-value 对喂给了 map 任务,然后等 Map 函数计算完后,会生成的新 的 key-value 对缓冲在内存里。
第四步,这些缓冲了的 key-value 对,会定期地写到 map 任务所在机器的本地硬盘上。 并且按照一个分区函数(partitioning function),把输出的数据分成 R 个不同的区域。 而这些本地文件的位置,会被 worker 传回给到 master 节点,再由 master 节点将这些地 址转发给 reduce 任务所在的 worker 那里。
第五步,运行 reduce 任务的 worker,在收到 master 的通知之后,会通过 RPC(远程过 程调用)来从 map 任务所在机器的本地磁盘上,抓取数据。当 reduce 任务的 worker 获 取到所有的中间文件之后,它就会将中间文件根据 Key 进行排序。这样,所有相同 Key 的 Value 的数据会被放到一起,也就是完成了我们上一讲所说的混洗(Shuffle)的过程。
第六步,reduce 会对排序后的数据执行实际的 Reduce 函数,并把 reduce 的结果输出到 当前这个 reduce 分片的最终输出文件里。
第七步,当所有的 map 任务和 reduce 任务执行完成之后,master 会唤醒启动 MapReduce 任务的用户程序,然后回到用户程序里,往下执行 MapReduce 任务提交之 后的代码逻辑。
其实,以上整个 MapReduce 的执行过程,还是一个典型的 Master-Slave 的分布式系 统。map 和 reduce 所在的 worker 之间并不会直接通信,它们都只和 master 通信。另 外,像是 map 的输出数据在哪里这样的信息,也是告诉 master,让 master 转达给 reduce 所在的 worker。reduce 从 map 里获取数据,也是直接拿到数据所在的地址去抓 取,而不是让 reduce 通过 RPC,调用 map 所在的 worker 去获取数据。
在 Hadoop 1.0 里,MapReduce 论文里面的 worker 就是 TaskTracker,用来执行 map 和 reduce 的任务。而分配任务,以及和 TaskTracker 沟通任务的执行情况,都由单 一的 JobTracker 来负责。
这个设计,也导致了只要服务器数量一多,JobTracker 的负载就会很重。所以早年间,单 个 Hadoop 集群能够承载的服务器上限,被卡在了 4000 台。而且 JobTracker 也成为了 整个 Hadoop 系统很脆弱的“单点”。
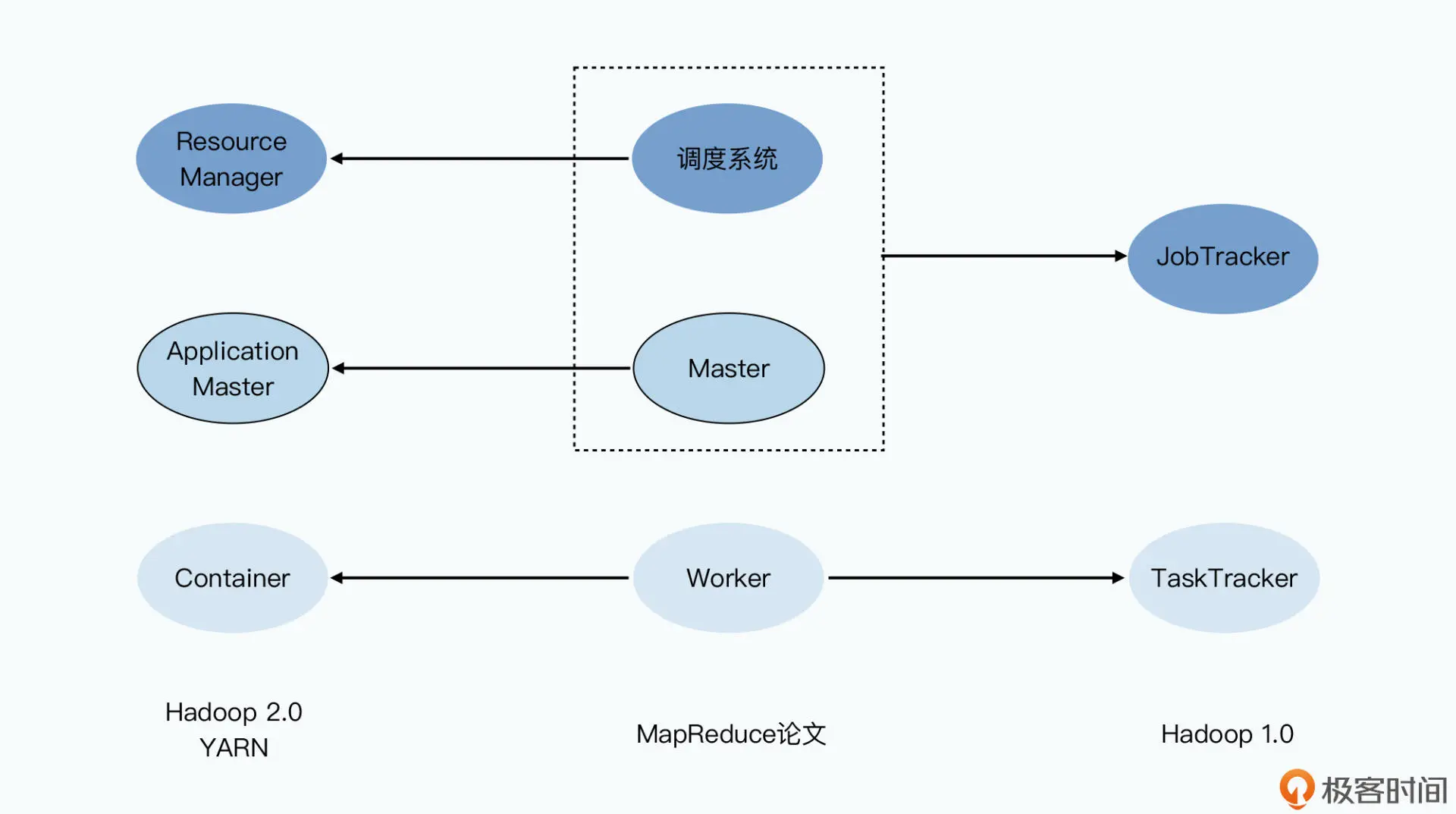
所以之后在 Hadoop 2.0,Hadoop 社区把 JobTracker 的角色,拆分成了进行任务调度的 Resource Mananger,以及监控单个 MapReduce 任务执行的 Application Master, 回到了和 MapReduce 论文相同的架构。
而在 2015 年,谷歌发布了 Borg 这个集群管理系统的论文的时候,大家发现谷歌早在 2003~2004 年,就已经有了独立的集群管理系统 Borg,也就是 MapReduce 里面所提到 的调度系统。
MapReduce 的容错(Fault Tolerance)
MapReduce 的容错机制非常简单,可以简单地用两个关键词来描述,就是重新运行和写 Checkpoints。
worker 节点的失效(Master Failure)
对于 Worker 节点的失效,MapReduce 框架解决问题的方式非常简单。就是换一台服务 器重新运行这个 Worker 节点被分配到的所有任务。master 节点会定时地去 ping 每一个 worker 节点,一旦 worker 节点没有响应,我们就会认为这个节点失效了。
于是,我们会重新在另一台服务器上,启动一个 worker 进程,并且在新的 worker 进程所 在的节点上,重新运行所有失效节点上被分配到的任务。而无论失效节点上,之前的 map 和 reduce 任务是否执行成功,这些任务都会重新运行。因为在节点 ping 不通的情况下, 我们很难保障它的本地硬盘还能正常访问。
master 节点的失效(Worker Failure)
对于 master 节点的失效,事实上谷歌已经告诉了我们,他们就任由 master 节点失败了, 也就是整个 MapReduce 任务失败了。那么,对于开发者来说,解决这个问题的办法也很 简单,就是再次提交一下任务去重试。
因为 master 进程在整个任务中只有一个,它会失效的可能性很小。而 MapReduce 的任 务也是一个用户离线数据处理的任务,并不是一个实时在线的服务,失败重来通常也没有 什么影响,只是晚一点拿到数据结果罢了。
虽然在论文发表的时候,谷歌并没有实现对于 master 的失效自动恢复机制,但他们也给 出了一个很简单的解决方案,那就是让 master 定时把它里面存放的信息,作为一个个的 Checkpoint 写入到硬盘中去。
那么我们动一下脑筋,我们可以把这个 Checkpoint 直接写到 GFS 里,然后让调度系统监 控 master。这样一旦 master 失效,我们就可以启动一个新的 master,来读取 Checkpoints 数据,然后就可以恢复任务的继续执行了,而不需要重新运行整个任务。
对错误数据视而不见
worker 和 master 的节点失效,以及对应的恢复机制,通常都是来自于硬件问题。但是在 海量数据处理的情况下,比如在 TB 乃至 PB 级别的数据下,我们还会经常遇到“脏数 据”的问题。
这些数据,可能是日志采集的时候就出错了,也可能是一个非常罕见的边界情况(edge- case),我们的 Map 和 Reduce 函数正好处理不了。甚至有可能,只是简单的硬盘硬件 的问题带来的错误数据。
那么,对于这些异常数据,我们固然可以不断 debug,一一修正。但是这么做,大多数时 候都是划不来的,你很可能为了一条数据记录,由于 Map 函数处理不了,你就要重新扫描 几 TB 的数据。
所以,MapReduce 不仅为节点故障提供了容错机制,对于这些极少数的数据异常带来的 问题,也提供了一个容错机制。MapReduce 会记录 Map 或者 Reduce 函数,运行出错 的具体数据的行号,如果同样行号的数据执行重试还是出错,它就会跳过这一行的数据。 如果这样的数据行数在总体数据中的比例很小,那么整个 MapReduce 程序会忽视这些错 误,仍然执行完成。毕竟,一个 URL 被访问了 1 万次还是 9999 次,对于搜素引擎的排序 结果不会有什么影响。
MapReduce 的性能优化
我们在前面说过,其实 MapReduce 的集群就是 GFS 的集群。所以 MapReduce 集群里的硬件 配置,和 GFS 的硬件配置差不多,最容易遇到的性能瓶颈,也是 100MB 或者 1GB 的网 络带宽。
把程序搬到数据那儿去
既然网络带宽是瓶颈,那么优化的办法自然就是尽可能减少需要通过网络传输的数据。
在 MapReduce 这个框架下,就是在分配 map 任务的时候,根据需要读取的数据在哪里 进行分配。通过前面 GFS 论文的学习,我们可以知道,GFS 是知道每一个 Block 的数据是 在哪台服务器上的。而 MapReduce,会找到同样服务器上的 worker,来分配对应的 map 任务。如果那台服务器上没有,那么它就会找离这台服务器最近的、有 worker 的服 务器,来分配对应的任务。你可以参考下面给出的示意图:
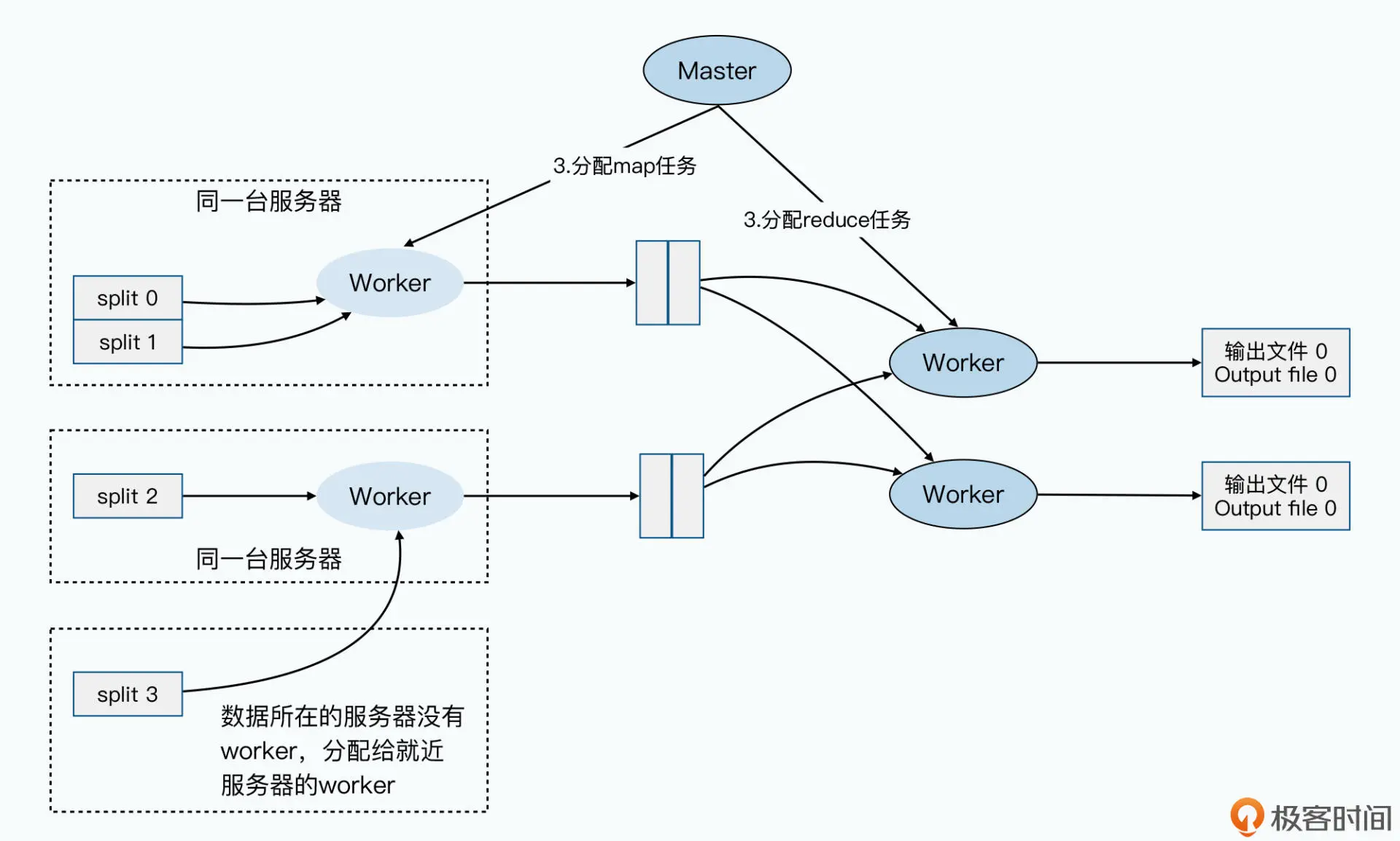
除此之外,由于 MapReduce 程序的代码往往很小,可能只有几百 KB 或者几 MB,但是 每个 map 需要读取的一个分片的数据是 64MB 大小。这样,我们通过把要执行的 MapReduce 程序,复制到数据所在的服务器上,就不用多花那 10 倍乃至 100 倍的网络 传输量了。
这就好像你想要研究金字塔,最好的办法不是把金字塔搬到你家来,而是你买张机票飞过 去。这里的金字塔就是要处理的数据,而你,就是那个分配过去的 MapReduce 程序。
通过 Combiner 减少网络数据传输
除了 Map 函数需要读取输入的分片数据之外,Reduce 所在的 worker 去抓取中间数据, 一样也需要通过网络。那么要在这里减少网络传输,最简单的办法,就是尽可能让中间数 据的数据量小一些。
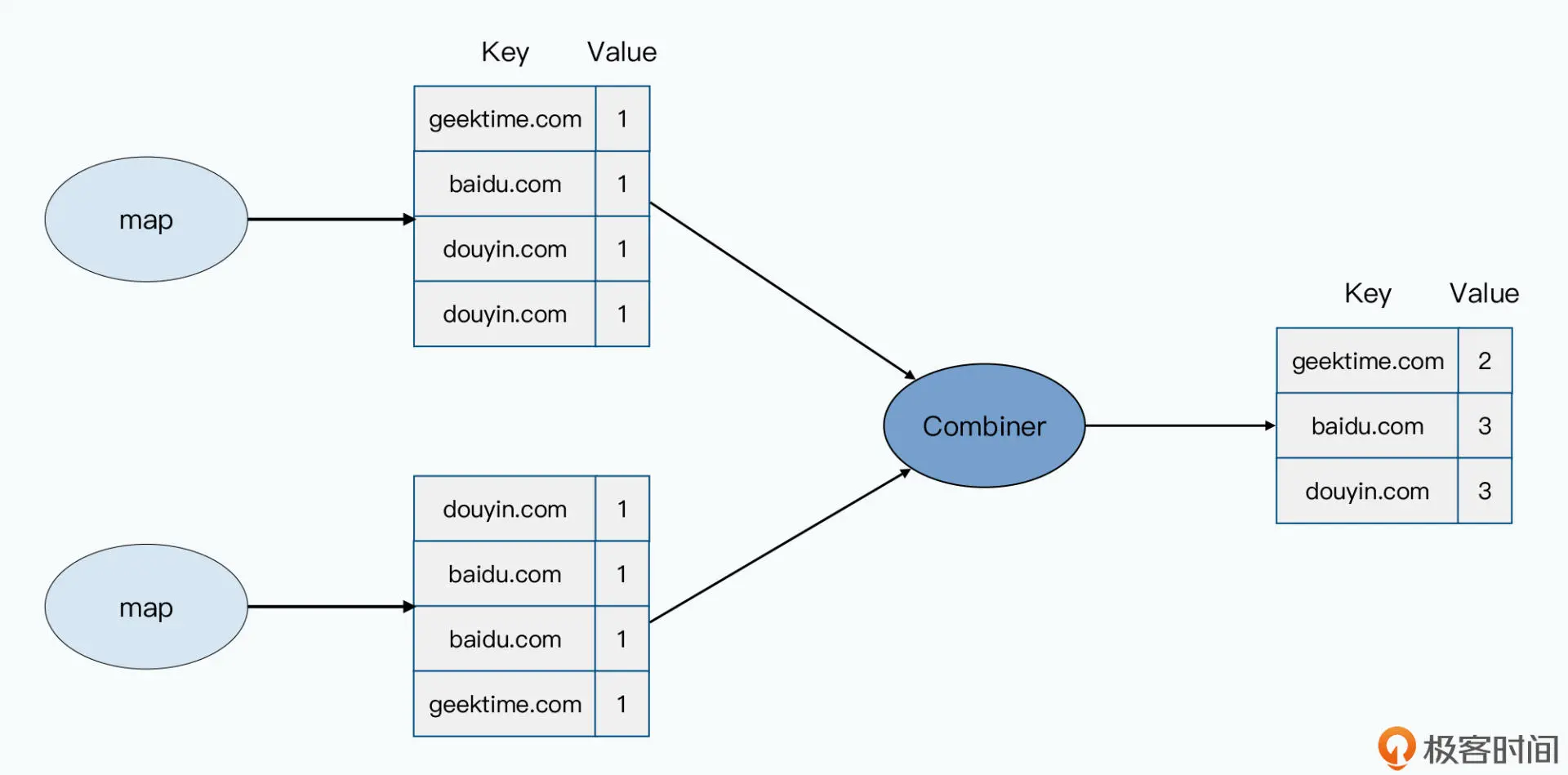
自然,在 MapReduce 的框架里,也不会放过这一点。MapReduce 允许开发者自己定义 一个 Combiner 函数。这个 Combiner 函数,会对在同一个服务器上所有 map 输出的结 果运行一次,然后进行数据合并。
既然只是对访问次数计数,我们自然就可以通过一个 Combiner,把 1 万条相同域名的访 问记录做个化简。把它们变成 Key 还是域名,Value 就是有多少次访问的数值这样的记录 就好了。而这样一化简,reduce 所在的 worker 需要抓取的数据,就从 1 万条变成了 1 条。
实际上,不仅是同一个 Map 函数的输出可以合并,同一台服务器上多个 Map 的输出,我 们都可以合并。反正它们都在一台机器上,合并只需要本地的硬盘读写和 CPU,并不需要 我们最紧缺的网络资源。
我就以域名的访问次数为例,它的数据分布一定有很强的头部效应,少量 20% 的域名可能 占了 80% 的访问记录。这样一合并,我们要传输的数据至少可以减少 60%。如果考虑一 台 16 核的服务器,有 16 个 map 的 worker 运行,应该还能再减少 80% 以上。这样,通 过一个中间的 Combiner,我们要传输的数据一下子就下降了两个数量级,大大缓解了网 络传输的压力。
你可以参考下面给出的示意图:
MapReduce 的 debug 信息
虽然我们一直说,我们希望 MapReduce 让开发者意识不到分布式的存在。但是归根到 底,map 和 reduce 的任务都是在分布式集群上运行的,这个就给我们对程序 debug 带 来了很大的挑战。无论是通过 debugger 做单步调试,还是打印出日志来看程序执行的情 况,都不太可行。所以,MapReduce 也为开发者贴心地提供了三个办法来解决这一点。
第一个,是提供一个单机运行的 MapReduce 的库,这个库在接收到 MapReduce 任务 之后,会在本地执行完成 map 和 reduce 的任务。这样,你就可以通过拿一点小数据,在 本地调试你的 MapReduce 任务了,无论是 debugger 还是打日志,都行得通。
第二个,是在 master 里面内嵌了一个 HTTP 服务器,然后把 master 的各种状态展示出 来给开发者看到。这样一来,你就可以看到有多少个任务执行完了,有多少任务还在执行 过程中,它处理了多少输入数据,有多少中间数据,有多少输出的结果数据,以及任务完 成的百分比等等。同样的,里面还有每一个任务的日志信息。
另外通过这个 HTTP 服务器,你还可以看到具体是哪一个 worker 里的任务失败了,对应 的错误日志是什么。这样,你就可以快速在线上定位你的程序出了什么错,是在哪台服务 器上。
最后一个,是 MapReduce 框架里提供了一个计数器(counter)的机制。作为开发者, 你可以自己定义几个计数器,然后在 Map 和 Reduce 的函数里去调用这个计数器进行自 增。所有 map 和 reduce 的计数器都会汇总到 master 节点上,通过上面的 HTTP 服务器 里展现出来。
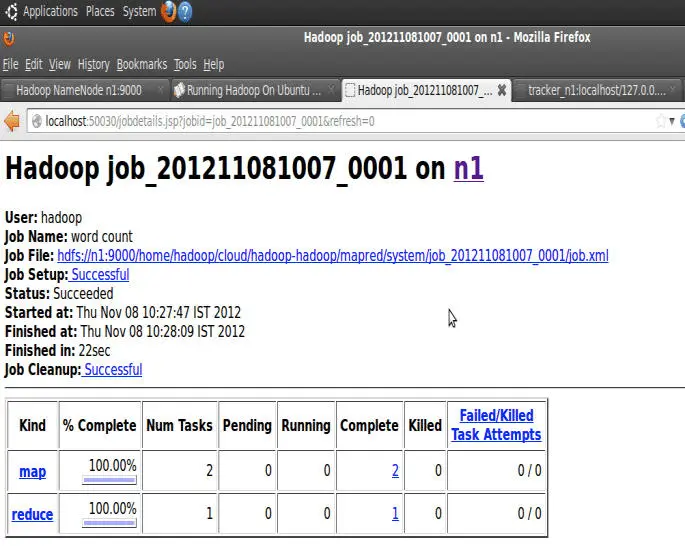
比如,你就可以利用这个计数器,去统计有多少输入日志的格式和预期的不一样。如果比 例太高,那么多半你的程序就有 Bug,没有兼容所有合法的日志。下图展示的就是在 Hadoop 里,通过 JobTracker 查看 Task 的执行情况,以及对应每个 Task 的日志:
遗憾与缺陷
尽管 MapReduce 框架已经作出了很多努力,但是今天来看,整个计算框架的缺陷还是不 少的。在我看来,主要的缺陷有两个:
第一个是还没有 100% 做到让用户意识不到“分布式”的存在,无论是 Combiner 还 是 Partitioner,都是让开发者意识到,它面对的还是分布式的数据和分布式的程序。
第二个是性能仍然不太理想,这体现在两个方面,一个是每个任务都有比较大的 overhead,都需要预先把程序复制到各个 worker 节点,然后启动进程;另一个是所有 的中间数据都要读写多次硬盘。map 的输出结果要写到硬盘上,reduce 抓取数据排序 合并之后,也要先写到本地硬盘上再进行读取,所以快不起来。
不过,随着时间的变迁,会有更多新一代的系统,像是 Dremel 和 Spark 逐步取代 MapReduce,让我们能更容易地写出分布式数据处理程序,处理起数据也比原始的 MapReduce 快上不少。
参考链接
https://time.geekbang.org/column/article/421579
文档信息
- 本文作者:ironartisan
- 本文链接:https://ironartisan.github.io/2022/06/20/%E5%A4%A7%E6%95%B0%E6%8D%AE-2.MapReduce%E8%A7%A3%E8%AF%BB/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)