
Bigtable 要解决什么问题?
Bigtable 想要解决什么问题?我们不能用 MySQL 这样的关系型数据库,搭建一个集群 来解决吗? Bigtable 的架构是怎么样的?它是怎么来解决可用性、一致性以及容易运维这三个目标 的? Bigtable 的底层数据结构是怎么样的?它是通过什么样的方式在机械硬盘上做到高并发 地随机读写呢?
当你理解了这三个问题,相信你对分布式数据库的设计可以算是正式入门了,而且你对于 计算机底层数据结构、硬件原理和大型系统设计之间的联系也建立起来了。这样,无论你 后续是想专门从事分布式数据库的开发,还是成为一个熟知各类系统原理的架构师,都会 有很大帮助。
不知道你有没有听说过 Friendster这个网站?如果听说过的话,你多半暴露年龄了。 Friendster 是一个成立于 2002 年的社交网络,比 Facebook 要早,更远远早于微信、微 博乃至校内网。然而,Friendster 虽然起了个大早,却最终因为种种原因销声匿迹了。其 中很重要的一个问题,就是在技术上,Friendster 没有解决好“伸缩性”(Scalability) 问题。
从 2003 年开始,Friendster 就一直遇到严重的性能瓶颈,并且因为性能问题限制了很多 功能的实现。甚至 MIT 在 2003 年的一门《Web 应用的软件工程》的课程里,还专门 把 Friendster 的可用性分析,作为期中考试里的一题,可见当时 Friendster 的体验有多糟 糕了。
Friendster 在成立一年之后的 2003 年,就已经有 7500 万用户了,所以服务器压力的确 很大。那么根据上面 MIT 学生的描述,我们可以想象一个简单的社交网络的功能,以及对 应需要的读写请求数量:用户去看自己的时间线的时候,需要看到自己 150 个好友发的帖 子。这里有两种解决办法。
一种是用户发帖子的时候,系统往所有好友的时间线里写一条数据,那么写入就会放大 150 倍。假设每天有 20% 的用户发 3 条帖子,那么写入的数据量就是:
7500 万 x 20% x 150 x 3 = 67.5 亿
67.5 亿条随机数据写入,如果均匀分配到 10 个小时,每秒的随机写入量大概是:
67.5 亿 / (3600 秒 * 10) = 18.75 万次 / 秒
还有一种是每个用户看自己时间线的时候,系统会查询 150 个好友各自发表的内容,然后 做合并。那么对应的就是 22.5 亿次的随机数据读取,也就是每秒 6.25 万次的随机读取。
一块 7200 转的机械硬盘,只能支撑 100 的 IOPS,也就是 100 次随机读写。那按照上面的数 据来看,我们至少需要 600 块硬盘,才能支撑简单地读取自己的时间线信息。事实上, 600 块硬盘远远不够的,无论是读写什么数据,都不太可能只写入 1 条数据,更不可能只 有 1 次随机读写,而我们的硬盘,也不可能刚好跑满 IOPS
所以一方面,我们可能需要数千块硬盘,对应的,也就需要上千台服务器。另一方面,这 个集群需要能够支持海量的随机读写,至少需要支持到每秒百万次级别的随机读写,而 Bigtable 就是这样一个系统。
“小数据”的 MySQL 集群
Bigtable 的论文发表于 2006 年,而基于论文实现的开源系统 HBase,要到 2008 年才第 一次正式发布(0.18.0 版本)。所以,Friendster 并没有 Bigtable 可以用,在 2003 年, 一家互联网公司面对“伸缩性”这个问题,最好的选择是使用一个 MySQL 集群。
维护一个几十乃至上百台服务器的 MySQL 集群是可行的,但是,如果要像 GFS 一样到一 千乃至数千台服务器,还有可行性吗?下面我们就一起来看一下。
分库分表的扩容方式
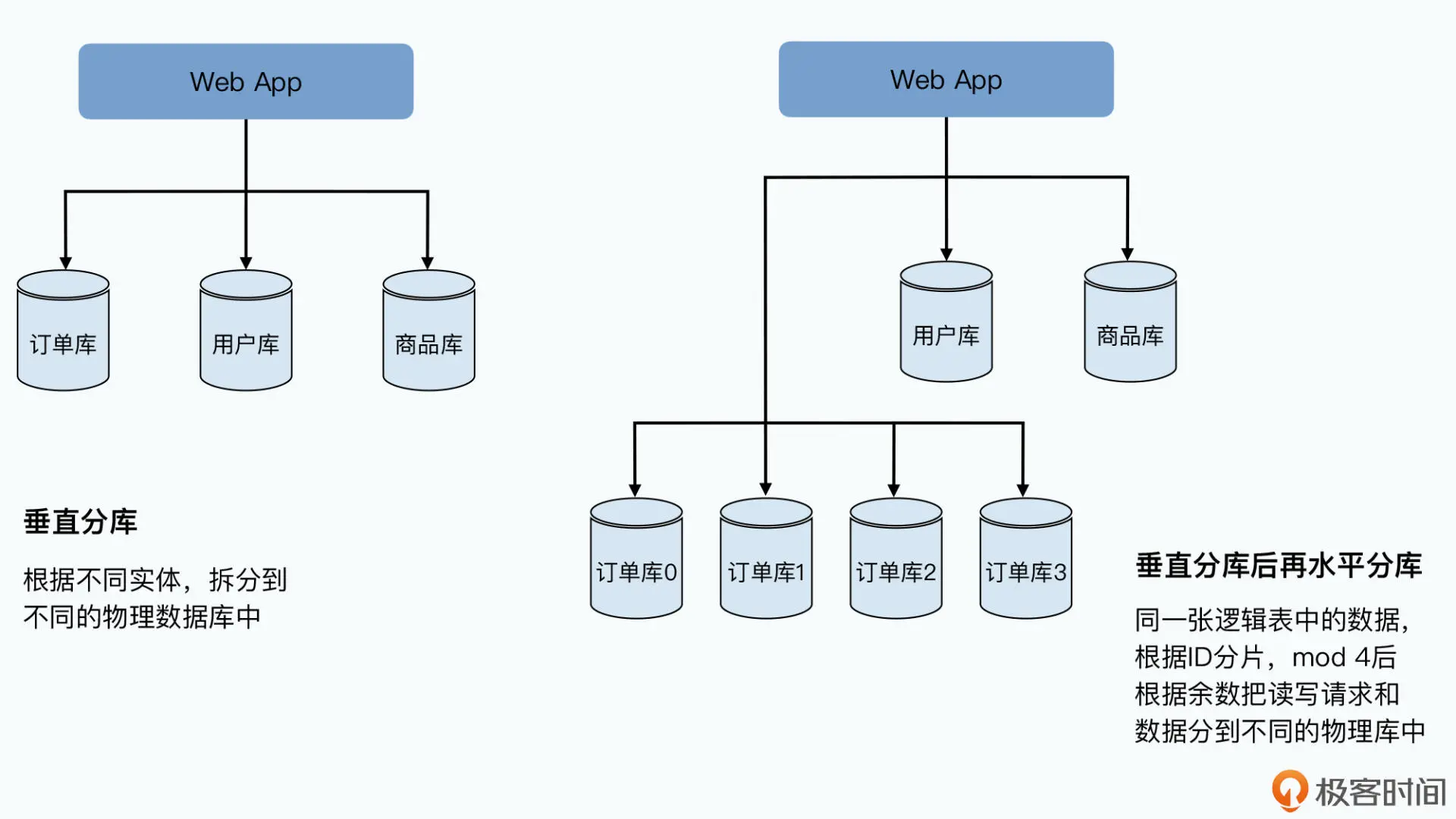
一致性的随机读写,在单个服务器上似乎并不是什么问题。如果你是做后端应用开发的, 肯定用过 MySQL 这样的数据库,你可以很容易地通过简单的 SQL,完成增删改查这样的随机数据读写。如果要把单机的 MySQL 扩展成分布式,好像也不是什么难题,只要做个分库分表就好了,这些套路你应该会非常熟悉。
一般来说,我们会先做垂直分库,在电商的系统里,我们把用户、商品、订单的表拆分到 不同服务器的数据库上。如果发现这样还不行,我们就再进行水平分库,把订单号 Hash 一下,然后取“模”(mod)个 4,拆分到 4 台不同的服务器的数据库里。
这样,每台机器只需要承接 1/4 的负担,看起来这种方式也能解决问题。当然,在分库分 表的过程中,我们已经放弃了 MySQL 这样的关系型数据库的很多特性,比如外键关联这 样的约束,以及单个数据库里面的跨行跨表的事务。
那么,为什么谷歌还需要发明一个 Bigtable 呢?这是因为分库分表,并不是一个很好的实 现“可伸缩性”和“可运维性”的方案。基于分库分表的方案,运维起来会很费劲,主要 体现在以下三点
不得不进行的“翻倍扩容”
首先,是资源使用很浪费。当服务器性能出现瓶颈需要扩容的时候,我们常常只能采 取“翻倍”分库增加服务器的方案。就以前面举的订单表为例,我们通过把订单 号“模”上个 4,拆分到 4 个不同的服务器的数据库里。
而随着我们承接的订单越来越多,每天 SQL 查询的请求越来越多,服务器的峰值 CPU 可 能超过了 60%。为了安全起见,我们希望对服务器进行扩容,让峰值 CPU 控制在 40% 以 下。但是这个时候,我们没办法只是增加 4 * 0.6 / 0.4 - 4 = 2 台服务器,而是不得不“翻 倍”增加 4 台服务器。
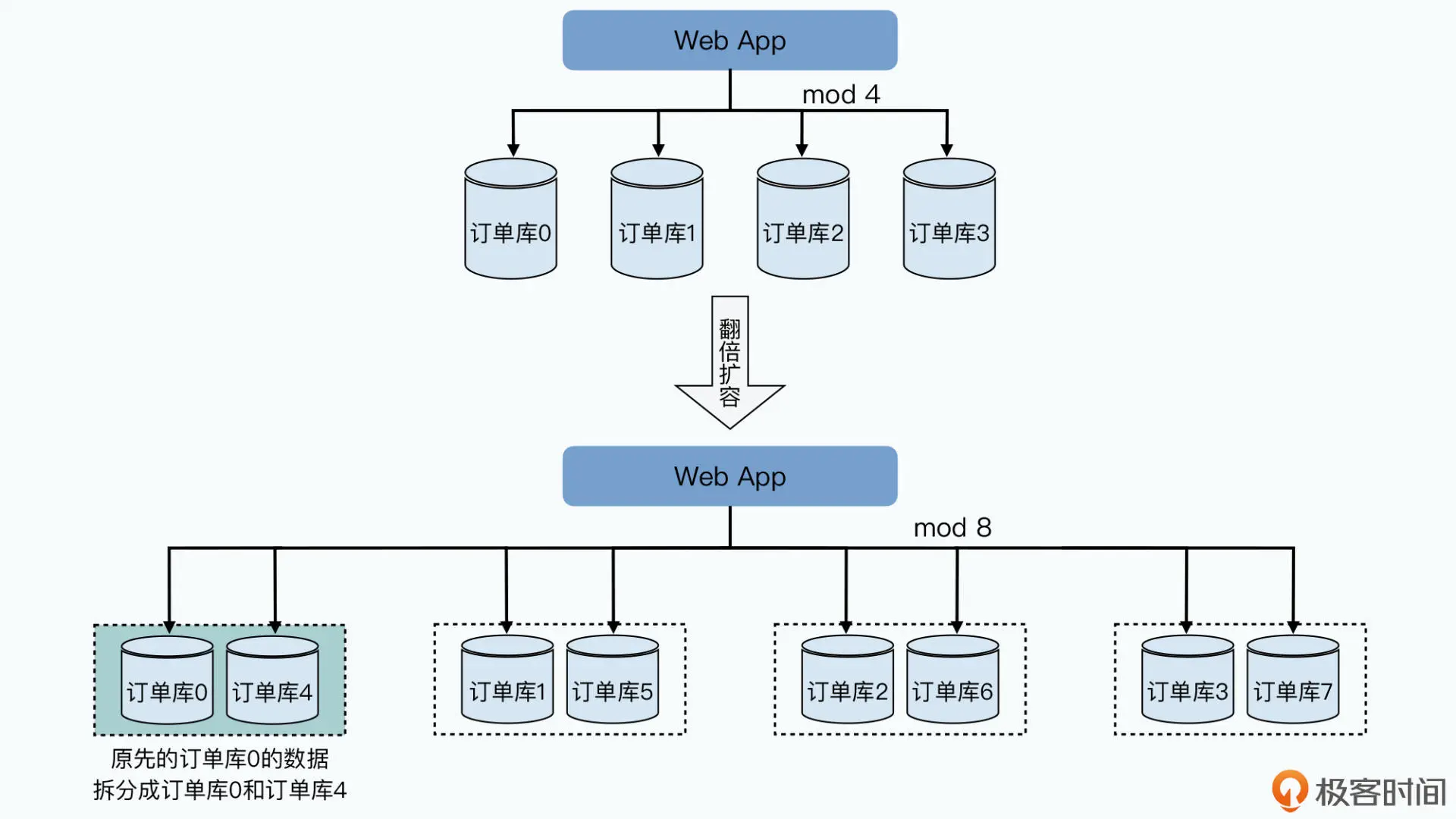
为什么呢?因为如果我们只增加 2 台服务器,把各个服务器的分片,从模上 4 变成模上 6,我们就需要在增加服务器之后,搬运大量的数据。并且这个数据搬运,不只是搬到新增 加的服务器上,而是有些数据还要在原有的 4 台服务器上互相搬运。
这个搬运过程需要占用大量的网络带宽和硬盘读写,所以很有可能要让数据库暂停服务。 而如果不暂停服务的话,我们就要面对在数据搬运的过程中,到底应该从哪个服务器读和 写数据的问题,问题一下子就变得极其复杂了。
而翻倍扩容服务器,我们可以只需要简单复制 50% 的数据,并且在数据完成复制之后自动 切换分片就可以了。但是翻倍扩容的方案,自然就带来了很多浪费,明明我们只需要加两 台服务器,但是现在要加上四台。更浪费的是,我们增加的服务器,也许只是为了应对双 十一促销这样的一小段时间,等到促销完成,我们又不再需要这些服务器了。
可这个时候,如果我们需要缩减服务器,也会非常麻烦,我们需要再把两台服务器的数据 复制到一台服务器上,才能完成缩容。可以看到,这个集群虽然可以“伸缩”,但是伸缩 起来非常不容易。
而我们希望的伸缩性是什么样的呢?自然是需要的时候,加 1 台服务器也加得,加 10 台 服务器也加得。而用不上的时候,减少个 8 台 10 台服务器也没有问题,并且这些动作都 不需要停机。这个,也是 Bigtable 的设计目标。
“我怎么早没想到”的数据分区
其次,是底层的数据分区策略对于应用不透明。如何分库和分表都需要开发人员来设计, 撰写代码的时候,也常常要考虑底层分库分表的设计。
我们还是以 MySQL 分表作为例子,这一次我们来分一下用户表。我们还是分到 4 台机器 上,用了用户出生的月份“模”上个 4。这个时候,很幸运,一年是有 12 个月,正好可以 均匀分布到 4 台不同的机器上。
但是当我们进行扩容,变成 8 台机器之后,问题就出现了。我们会发现,服务器 A 分到了 1 月和 9 月生日的用户,而服务器 B 只分到了 6 月生日的用户。在扩容之后,服务器 A 无 论是数据量,还是日常读写的负载,都比服务器 B 要高上一倍。而我们只能按照服务器 A 的负载要求来采购硬件,这也就意味着,服务器 B 的硬件性能很多都被浪费了。
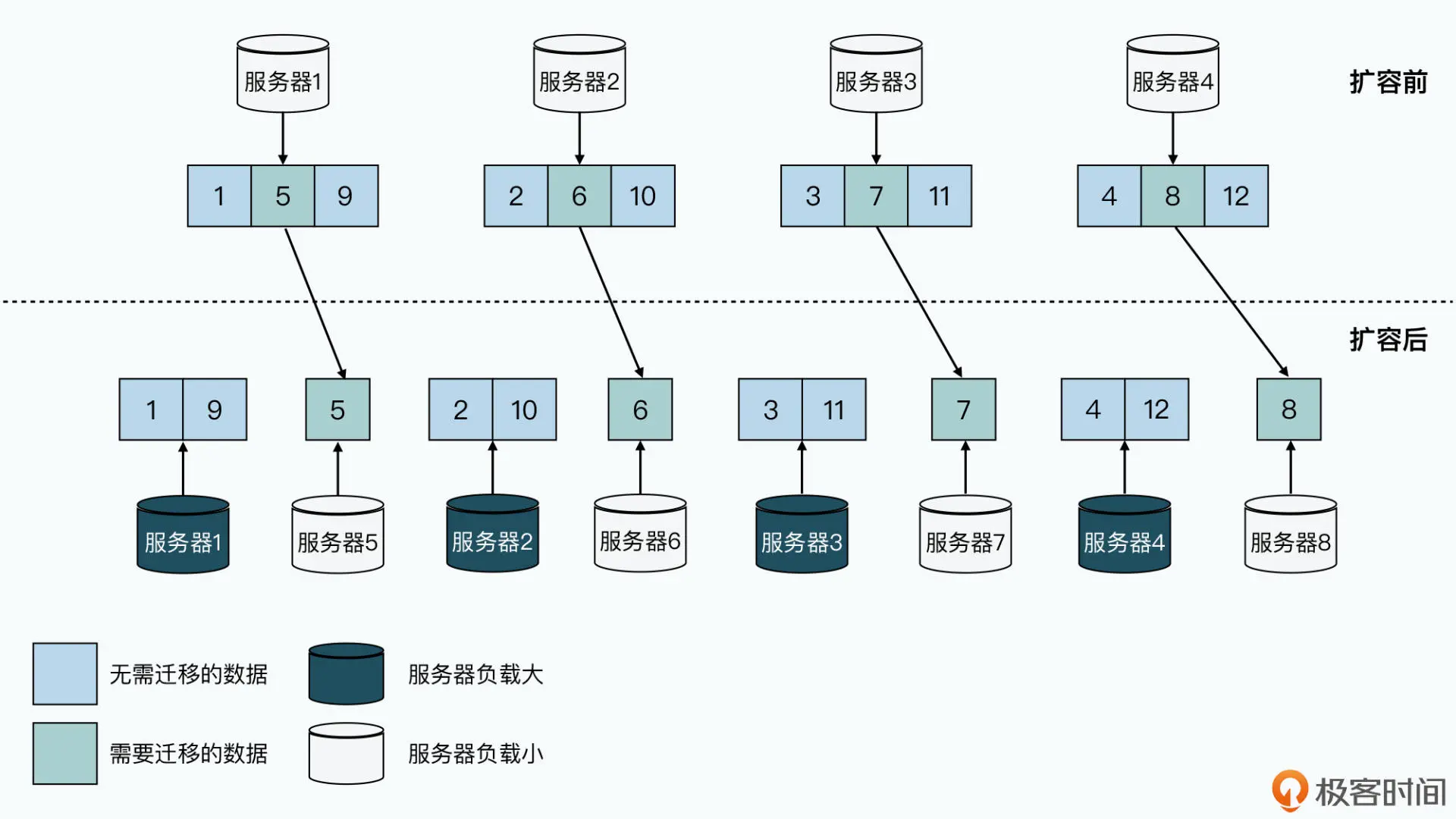
而且,不但用月份不行,用年份和日也不行。比如公司是 2018 年成立,2019 年和 2020 年快速成长,每年订单数涨 10 倍,如果你用年份来进行订单的分片,那么服务器之间的负 载就要差上十倍。而用日的话,双十一这样的大促也会让你猝不及防。
你会发现,使用 MySQL 集群,需要你在一开始就对如何切分数据做好精心设计。一旦稍 有不慎,设计上出现了数据倾斜,就很容易造成服务器忙得忙死,闲得闲死的现象。并且 即使你已经考虑得非常仔细了,随着业务本身的变化,比如要搞个双十一,也会把你一朝 打回原形。
那么,我们希望的分布式数据库是什么样的呢?自然是数据的分片是自适应的。比如 2019 年只有 100 万订单,那就分片到一个服务器节点上;2020 年有了 1000 万订单,自动给 你分了 10 个节点;当 2021 年有 1 亿订单的时候,就给你分配上 100 个节点。而这一 点,也同样是 Bigtable 的设计目标。
天天跑机房的人肉运维
最后,是故障恢复需要人工介入。在 MySQL 集群里,我们可以对每个服务器都准备一个 高可用的备份,避免一出现故障整个集群就没法用了。但是此时,我们的运维人员仍然需 要立刻介入,因为这个时候系统是多了一个“单点”的,我们需要手工添加一台新的服务 器进入集群,同步到最新的数据。
我们可以一起来算一算,如果有一个 1000 台服务器的 MySQL 集群,每台服务器上都给 插上 12 块硬盘,一共有 1 万 2 千块硬盘。这么多硬盘,我们到底要面临多少故障呢?
2003 年,谷歌的论文用的还是传统的机械硬盘,那个时候机械硬盘的可靠性数据我已经找 不到了。不过我们可以看一下 2021 年的数据:Backblaze 这个公司从 2012 年开始就会 发布硬盘的可靠性数据,从 2021 年 Q2 季度来看,他们数据中心里将近 18 万块的硬盘, 在 90 天里一共坏了 439 块,差不多每天要坏上将近 5 块硬盘。
我们的 1 万 2 千块硬盘,是他们的 7% 不到,基本上 3 天也要坏上一块硬盘。要知道,这 个还是只考虑了硬盘的硬件损坏,还没有算上 CPU、内存、交换机、网络等等各种各样的 问题。
而我们希望的可运维性是怎么样的呢?最好是 1000 台节点的服务器,坏个 10 台 8 台没 事儿,系统能够自动把这 10 台 8 台服务器下线,用剩下的 990 台继续完成服务。我们的 运维人员只要 1 个月跑一趟机房批量换些机器就好,而不用 996 甚至 007 地担心硬件故 障带来的不可用问题。
Bigtable 的设计目标
看到这里,相信你对 Bigtable 的设计目标应该更清楚了。最基础的目标自然是应对业务需 求的,能够支撑百万级别随机读写 IOPS,并且伸缩到上千台服务器的一个数据库。但是光 能撑起 IOPS 还不够。在这个数据量下,整个系统的“可伸缩性”和“可运维性”就变得 非常重要。
这里的伸缩性,包括两点:
第一个,是可以随时加减服务器,并且对添加减少服务器数量的限制要小,能够做到忙 的时候加几台服务器,过几个小时峰值过去了,就可以把服务器降下来。
第二个,是数据的分片会自动根据负载调整。某一个分片写入的数据多了,能够自动拆 成多个分片来平衡负载。而如果负载大了,添加了服务器之后,也能很快平衡数据,让 各个节点均匀承担压力。
而可运维性,则除了上面的两点之外,小部分节点的故障,不应该影响整个集群的运行, 我们的运维人员也不用急匆匆地立刻去恢复。集群自身也要有很强的容错能力,能够把对 应的请求和服务,调度到其他节点去。
那么,当我们回头看这个设计目标之后,会发现 Bigtable 的设计思路和 GFS 以及 MapReduce 一脉相承。
这三个系统的核心设计思路,就是把一个集群当成一台计算机。对于使用者来说,完全不 用在意后面的分布式的存在。这样的设计思路,使得所有的工程师,并不需要学习什么新 知识,只要熟悉这些分布式系统给到的接口,就能上手写大型系统。而这一点就让谷歌在 很长一段时间都拥有极强的工程优势。
在 GFS+MapReduce+Bigtable 发布的前后几年里,谷歌发布了很多优秀的产品,比如 Gmail、Google Maps、Google Analytics 等,而这些产品的底层,就是优秀的分布式架 构系统给谷歌带来的竞争优势。
当然,除了这些目标之外,Bigtable 也放弃了很多目标,其中有两个非常重要:
第一个是放弃了关系模型,也不支持 SQL 语言;
第二个,则是放弃了跨行事务,Bigtable 只支持单行的事务模型。
而这两个问题,一直要到 10 年后的 Spanner 里,才被真正解决好。在后续的课程里,你 也会看到 Spanner 是怎么一步步从 Bigtable 进化而来的。到时候,你也可以对照着 Spanner 的论文来回头看看 Bigtable,看看这些逐步迭代的设计是否和你自己的思考和猜 想一致。
无论是加减服务器、数据自动分片,还是硬件故障下的自动恢复,都不是一个“没有也能 坚持,有了更好”的可选的需求。在“大数据时代”,在需要上千台服务器的集群之下, 这些都变成了比优化一下性能、支持一下新的某个接口更重要的需求点了。
而 Bigtable 针对这些问题的答案,其实就是三点:
第一点,是将整个系统的存储层,搭建在 GFS 上。然后通过单 Master 调度多 Tablets 的方式,使得整个集群非常容易伸缩和维护。
第二点,是通过 MemTable+SSTable 这样一个底层文件格式,解决高速随机读写数据 的问题。
最后一点,则是通过 Chubby 这个高可用的分布式锁服务解决一致性的挑战。
Bigtable 在一开始,也不准备先考虑事务、Join 等高级的功能,而是把核心放在 了“可伸缩性”上。因此,Bigtable 自己的数据模型也特别简单,是一个很宽的稀疏表。
每一张 Bigtable 的表都特别简单,每一行就是一条数据:
第一个,Bigtable 是如何进行数据分区,使得整个集群灵活可扩展的;
第二个,Bigtable 是如何设计,使得 Master 不会成为单点故障,乃至单点性能的瓶 颈;
最后,自然是整个 Bigtable 的整体架构和组件由哪些东西组成。
一条数据里面,有一个行键(Row Key),也就是这条数据的主键,Bigtable 提供了通 过这个行键随机读写这条记录的接口。因为总是通过行键来读写数据,所以很多人也把 这样的数据库叫做 KV 数据库。
每一行里的数据呢,你需要指定一些列族(Column Family),每个列族下,你不需要 指定列(Column)。每一条数据都可以有属于自己的列,每一行数据的列也可以完全 不一样,因为列不是固定的。这个所谓不是固定的,其实就是列下面没有值。因为 Bigtable 在底层存储数据的时候,每一条记录都要把列和值存下来,没有值,意味着对 应的这一行就没有这个列。这也是为什么说 Bigtable 是一个“稀疏”的表。
列下面如果有值的话,可以存储多个版本,不同版本都会存上对应版本的时间戳 (Timestamp),你可以指定保留最近的 N 个版本(比如 N=3,就是保留时间戳最近 的三个版本),也可以指定保留某一个时间点之后的版本。
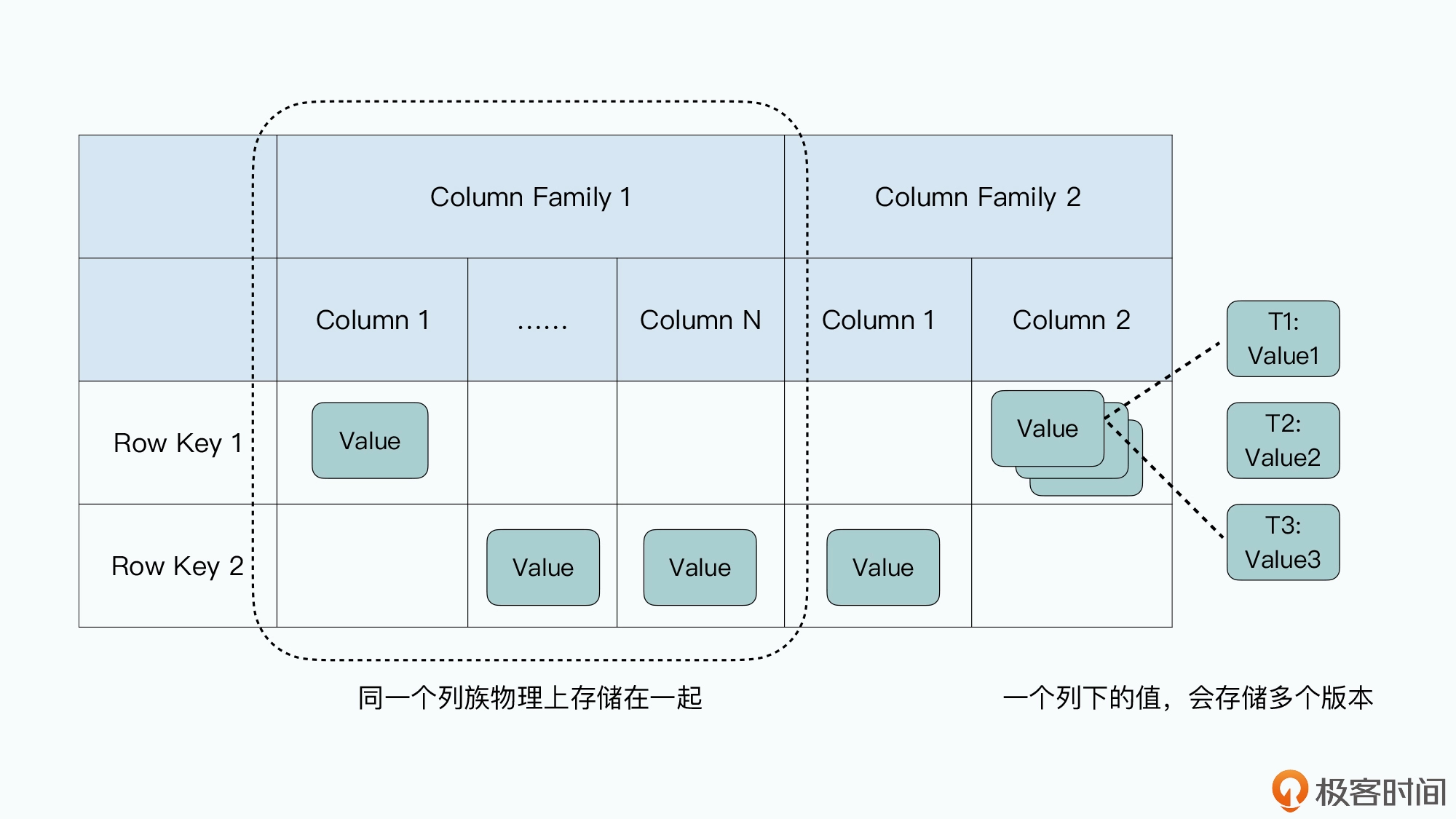
其实,这里的有些命名容易让人误解,比如列族,这个名字很容易让人误解 Bigtable 是一 个基于列存储的数据库。但事实完全不是这样,我觉得对于列族,更合理的解读是,它是 一张“物理表”,同一个列族下的数据会在物理上存储在一起。而整个表,是一张“逻辑 表”。
在现实当中,Bigtable 的开源实现 HBase,就是把每一个列族的数据存储在同一个 HFile 文件里。而在 Bigtable 的论文中,Google 定义了一个叫做本地组(Locality Group)的 概念,我们可以把多个列族放在同一个本地组中,而同一个本地组的所有列的数据,都会 存储在同一个 SSTable 文件里。
这个设计,就使得我们不需要针对字段多的数据表,像 MySQL 那样,进行纵向拆表了。
Bigtable 的这个数据模型,使得我们能很容易地去增加列,而且增加列并不算是修改 Bigtable 里一张表的 Schema,而是在某些这个列需要有值的行里面,直接写入数据就好 了。这里的列和值,其实是直接以 key-value 键值对的形式直接存储下来的。
这个灵活、稀疏而又宽的表,特别适合早期的互联网业务。虽然数据量很大,但是数据本 身的 Schema 我们可能没有想清楚,加减字段都不需要停机或者锁表。要知道,MySQL 直到 5.5 版本,用 ALTER 命令修改表结构仍然需要将整张表锁住。并且在锁住这张表的时 候,我们是不能往表里写数据的。对于一张数据量很大的表来说,这会让整张表有很长一 段时间不能写入数据。
而 Bigtable 这个稀疏列的设计,就为我们带来了很大的灵活性,如同《架构整洁之道》的 作者 Uncle Bob说的那样:“架构师的工作不是作出决策,而是尽可能久地推迟决策, 在现在不作出重大决策的情况下构建程序,以便以后有足够信息时再作出决策。
数据分区,可伸缩的第一步
Bigtable 是怎么解决上一讲MySQL 集群解决不好的水平分库问题的。
把一个数据表,根据主键的不同,拆分到多个不同的服务器上,在分布式数据库里被称之 为数据分区( Paritioning)。分区之后的每一片数据,在不同的分布式系统里有不同的名 字,在 MySQL 里呢,我们一般叫做 Shard,Bigtable 里则叫做 Tablet。
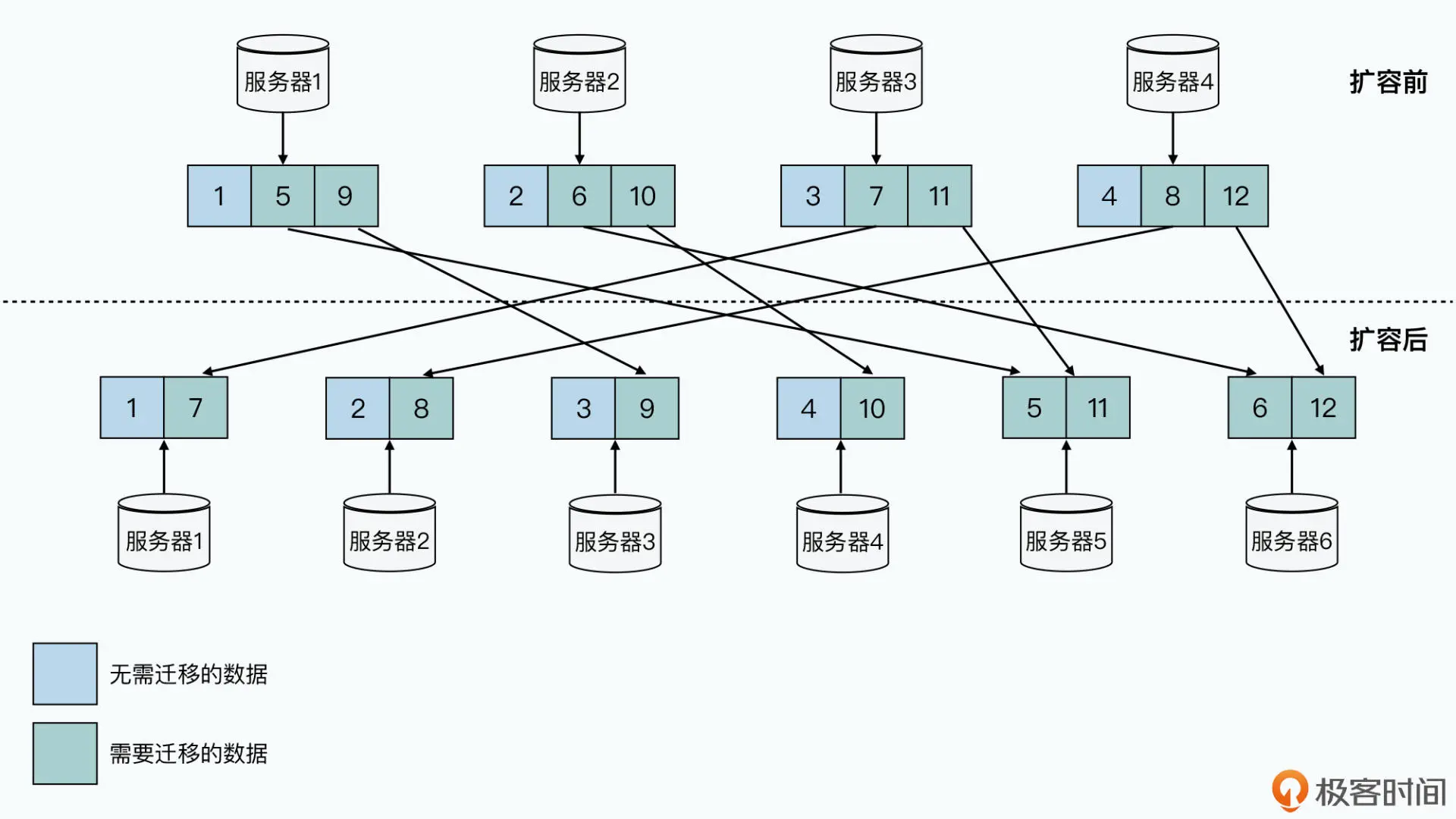
MySQL 集群的分区之所以遇到种种困难,是因为我们通过取模函数来进行分 区,也就是所谓的哈希分区。我们会拿一个字段哈希取模,然后划分到预先定好 N 个分片 里面。这里最大的问题,在于分区需要在一开始就设计好,而不是自动随我们的数据变化 动态调整的。
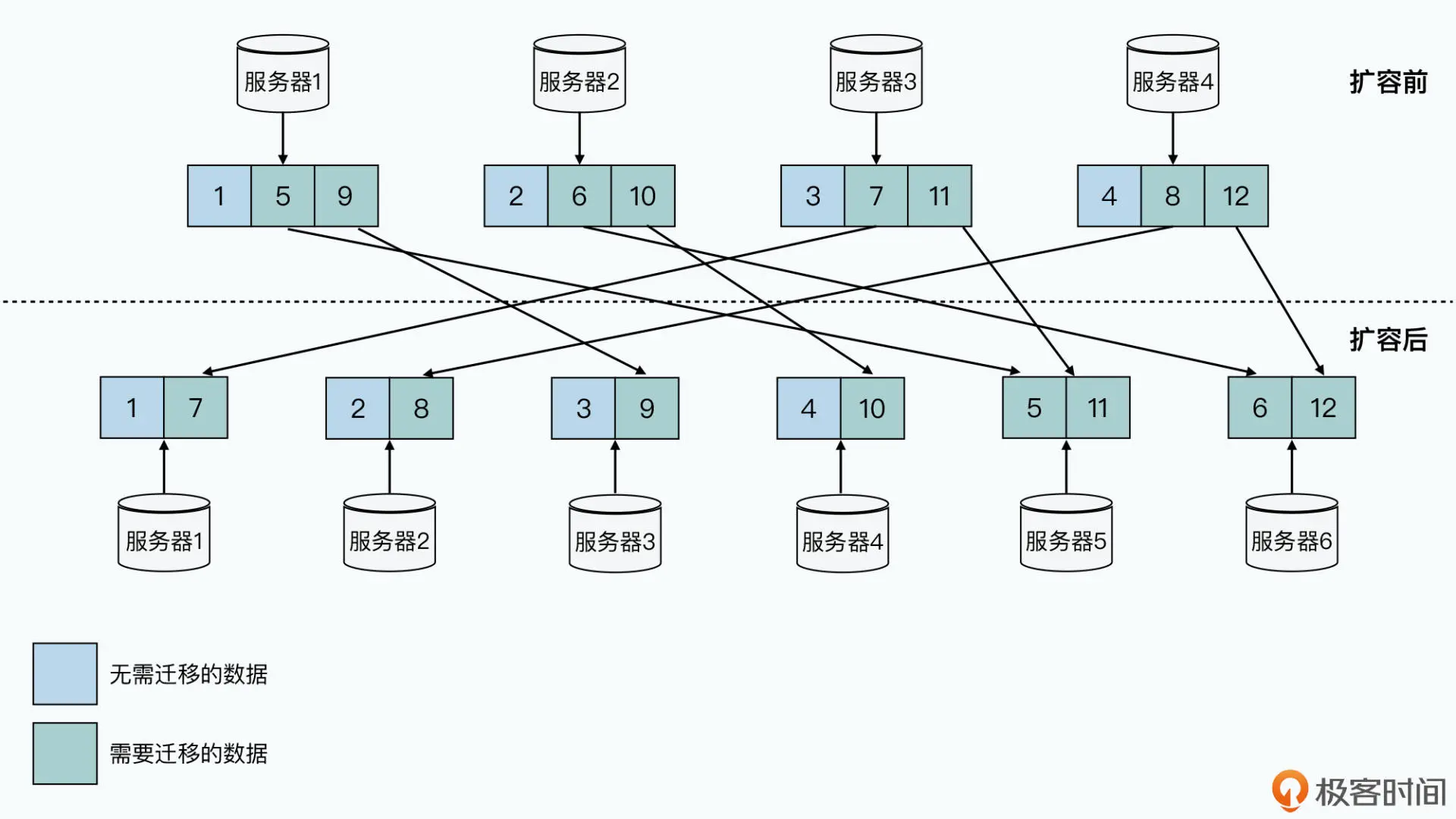
但是往往计划不如变化快,当我们的业务变化和计划稍有不同,就会遇到需要搬运数据或 者各个分片负载不均衡的情况。你可以看一下我从上一讲里搬过来的这张图,当我们将 4 台服务器扩展到 6 台服务器的时候,哈希分区的方式使得我们要在网络上搬运整个数据库 2/3 的数据。
所以,在 Bigtable 里,我们就采用了另外一种分区方式,也就是动态区间分区。我们不再 是一开始就定义好需要多少个机器,应该怎么分区,而是采用了一种自动去“分 裂”(split)的方式来动态地进行分区。
我们的整个数据表,会按照行键排好序,然后按照连续的行键一段段地分区。如果某一段 行键的区间里,写的数据越来越多,占用的存储空间越来越大,那么整个系统会自动地将 这个分区一分为二,变成两个分区。而如果某一个区间段的数据被删掉了很多,占用的空 间越来越小了,那么我们就会自动把这个分区和它旁边的分区合并到一起。
这个分区的过程,就好像你按照 A~Z 的字母顺序去管理你的书的过程。一开始,你只有一 个空箱子放在地上,然后你把你的书按照书名的拼音,从上到下放在箱子里。当有一本新 书需要放进来的时候,你就按照字母顺序插在某两本书中间。而当箱子放不下的时候,你 就再拿一个空箱子,放在放不下的箱子下面,然后把之前的箱子里的图书从中间一分,把 下面的一半放到新箱子里。
而我们删除数据的时候,就要把书从箱子里面拿走。当两个相邻的箱子里都很空的时候, 我们就可以把两个箱子里面的书放到一个箱子里面,然后把腾出来的空箱子挪走。这里的 一个个“箱子”就是我们的分片,这里面的一本本书,就是我们的一行数据,而书名的拼 音,就是我们的行键。可能以 A、B、C 开头的书多一些,那么它们占用的分区就会多一 些,以 U、V、W 开头的书少一些,可能这些书就都在一个分区里面。
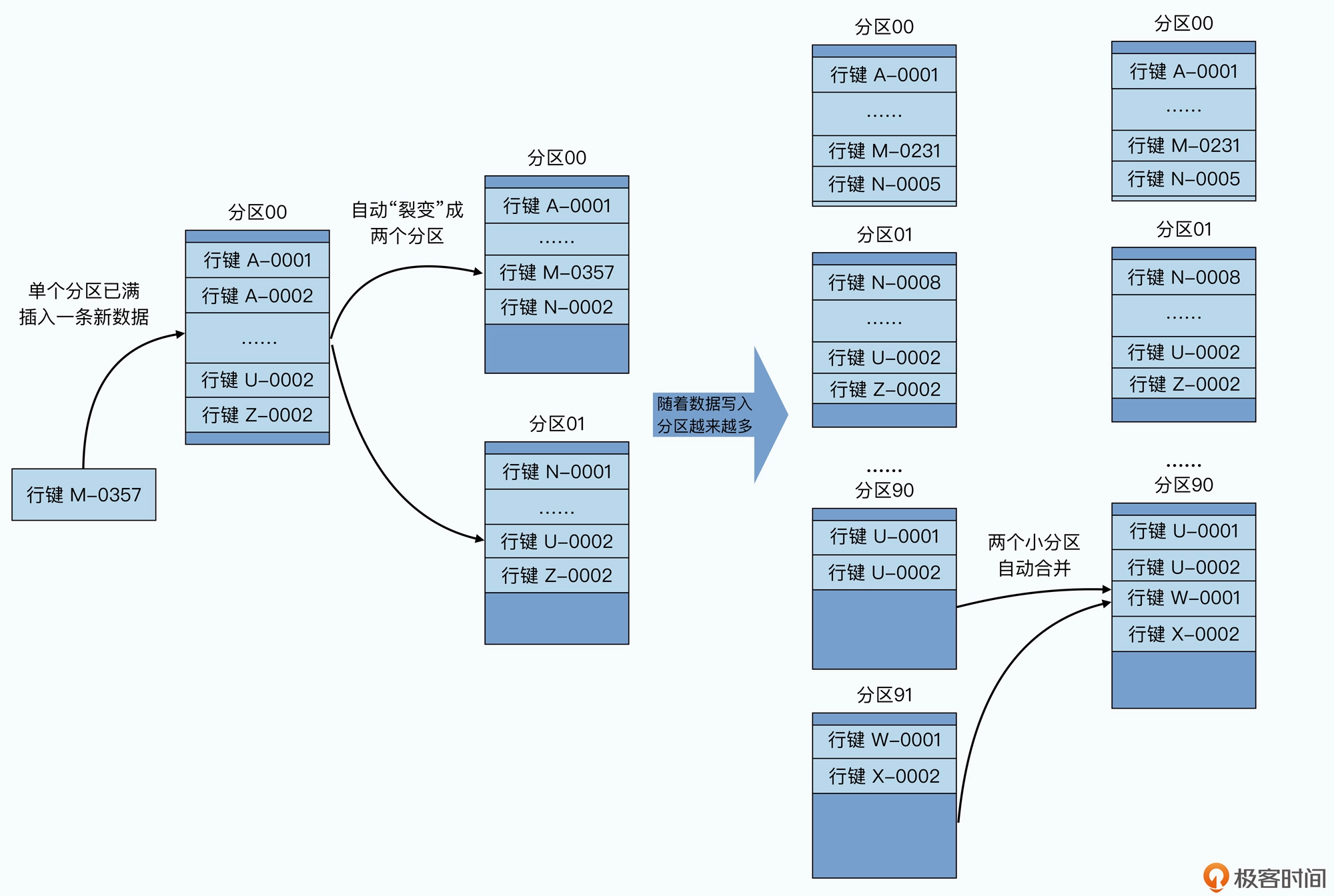
采用这样的方式,你会发现,你可以动态地调整数据是如何分区的,并且每个分区在数据 量上,都会相对比较均匀。而且,在分区发生变化的时候,你需要调整的只有一个分区, 再没有需要大量搬运数据的压力了。
通过 Master + Chubby 进行分区管理
MySQL 集群也用这样的分区方式,问题是不是就解决了?
答案当然是办不到了。因为我们还需要有一套存储、管理分区信息的机制,这在哈希分片 的 MySQL 集群里是没有的。在 Bigtable 里,我们是通过 Master 和 Chubby 这两个组 件来完成这个任务的。这两个组件,加上每个分片提供服务的 Tablet Server,以及实际 存储数据的 GFS,共同组成了整个 Bigtable 集群。
Master、Chubby 和 Tablet Server 的用途
Tablet Server 的角色最明确,就是用来实际提供数据读写服务的。一个 Tablet Server 上 会分配到 10 到 1000 个 Tablets,Tablet Server 就去负责这些 Tablets 的读写请求,并且在单个 Tablet 太大的时候,对它们进行分裂。
而哪些 Tablets 分配给哪个 Tablet Server,自然是由 Master 负责的,而且 Master 可以 根据每个 Tablet Server 的负载进行动态的调度,也就是 Master 还能起到负载均衡 (load balance)的作用。而这一点,也是 MySQL 集群很难做到的。
这是因为,Bigtable 的 Tablet Server 只负责在线服务,不负责数据存储。实际的存储, 是通过一种叫做 SSTable 的数据格式写入到 GFS 上的。也就是 Bigtable 里,数据存储和 在线服务的职责是完全分离的。我们调度 Tablet 的时候,只是调度在线服务的负载,并不 需要把数据也一并搬运走。
而MySQL 集群服务职责和数据存储是在同一个节点上的。我们要想把负 载大的节点调度到其他地方去,就意味着数据也要一并迁移走,而复制和迁移数据又会进 一步加大节点的负载,很有可能造成雪崩效应。
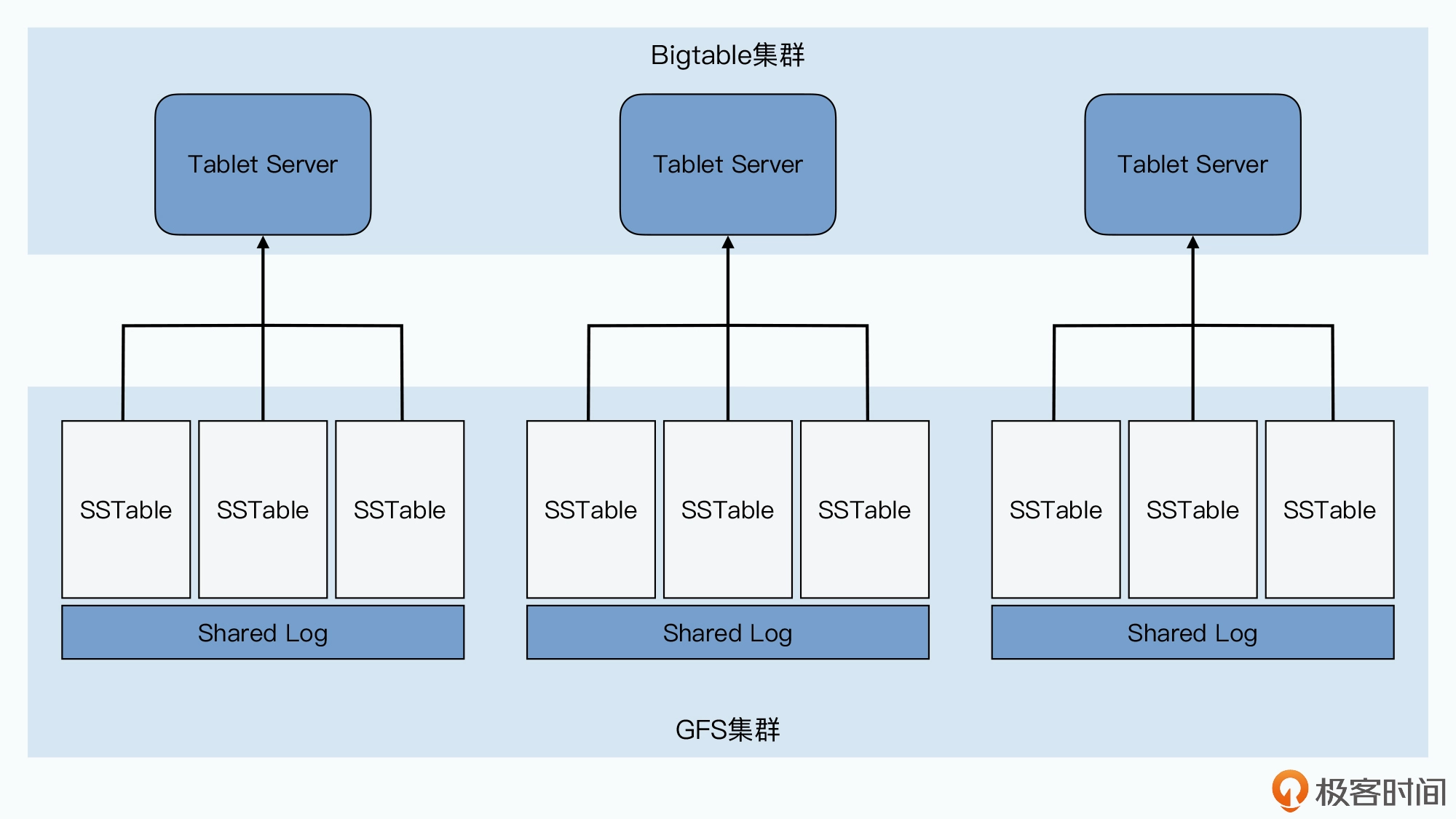
事实上,Master 一共会负责 5 项工作:
- 分配 Tablets 给 Tablet Server;
- 检测 Tablet Server 的新增和过期;
- 平衡 Tablet Server 的负载;
- 对于 GFS 上的数据进行垃圾回收(GC);
- 管理表(Table)和列族的 Schema 变更,比如表和列族的创建与删除。
好像 Master 加上 Tablet Server 就足以组成 Bigtable 了,为 什么还有一个 Chubby 这个组件呢?
Bigtable 需要 Chubby 来搞定这么几件事儿:
- 确保我们只有一个 Master;
- 存储 Bigtable 数据的引导位置(Bootstrap Location);
- 发现 Tablet Servers 以及在它们终止之后完成清理工作;
- 存储 Bigtable 的 Schema 信息;
- 存储 ACL,也就是 Bigtable 的访问权限。
这里面的最后两项只是简单的数据存储功能,我们重点来看看前三项。
如果没有 Chubby 的话,我能想到最直接的集群管理方案,就是让所有的 Tablet Server 直接和 Master 通信,把分区信息以及 Tablets 分配到哪些 Tablet Server,也直接放在 Master 的内存里面。这个办法,就和我们之前在 GFS 里的办法一样。但是这个方案,也 就使得 Master 变成了一个单点故障点(SPOF-Single Point of Failure)。当然,我们可 以通过 Backup Master 以及 Shadow Master 等方式,来尽可能提升可用性。
可是这样第一个问题就来了,我们在 GFS 的论文里面说过,我们可以通过一个外部服务去 监控 Master 的存活,等它挂了之后,自动切换到 Backup Master。但是,我们怎么知道 Master 是真的挂了,还是只是“外部服务”和 Master 之间的网络出现故障了呢?
如果是后者的话,我们很有可能会遇到一个很糟糕的情况,就是系统里面出现了两个 Master。这个时候,可能两个客户端分别认为这两个 Master 是真的,当它们分头在两边 写入数据的时候,我们就会遇到数据不一致的问题。
那么 Chubby,就是这里的这个外部服务,不过 Chubby 不是 1 台服务器,而是 5 台服务 器组成的一个集群,它会通过 Paxos 这样的共识算法,来确保不会出现误判。而且因为它 有 5 台服务器,所以也一并解决了高可用的问题,就算挂个 1~2 台,也并不会丢数据。
为什么数据读写不需要 Master?
Chubby 帮我们保障了只有一个 Master,那么我们再来看看分区和 Tablets 的分配信息, 这些信息也没有放在 Master。Bigtable 在这里用了一个很巧妙的方法,就是直接把这个 信息,存成了 Bigtable 的一张 METADATA 表,而这张表在哪里呢,它是直接存放在 Bigtable 集群里面的,其实 METADATA 表自己就是一张 Bigtable 的数据表。
这其实有点像 MySQL 里面的 information_schema 表,也就是数据库定义了一张特殊的 表,用来存放自己的元数据。不过,Bigtable 是一个分布式数据库,所以我们还要知道, 这个元数据究竟存放在哪个 Tablet Server 里,这个就需要通过 Chubby 来告诉我们了。
Bigtable 在 Chubby 里的一个指定的文件里,存放了一个叫做 Root Tablet 的分区所 在的位置。
然后,这个 Root Tablet 的分区,是 METADATA 表的第一个分区,这个分区永远不会 分裂。它里面存的,是 METADATA 里其他 Tablets 所在的位置。
而 METADATA 剩下的这些 Tablets,每一个 Tablet 中,都存放了用户创建的那些数据 表,所包含的 Tablets 所在的位置,也就是所谓的 User Tablets 的位置。
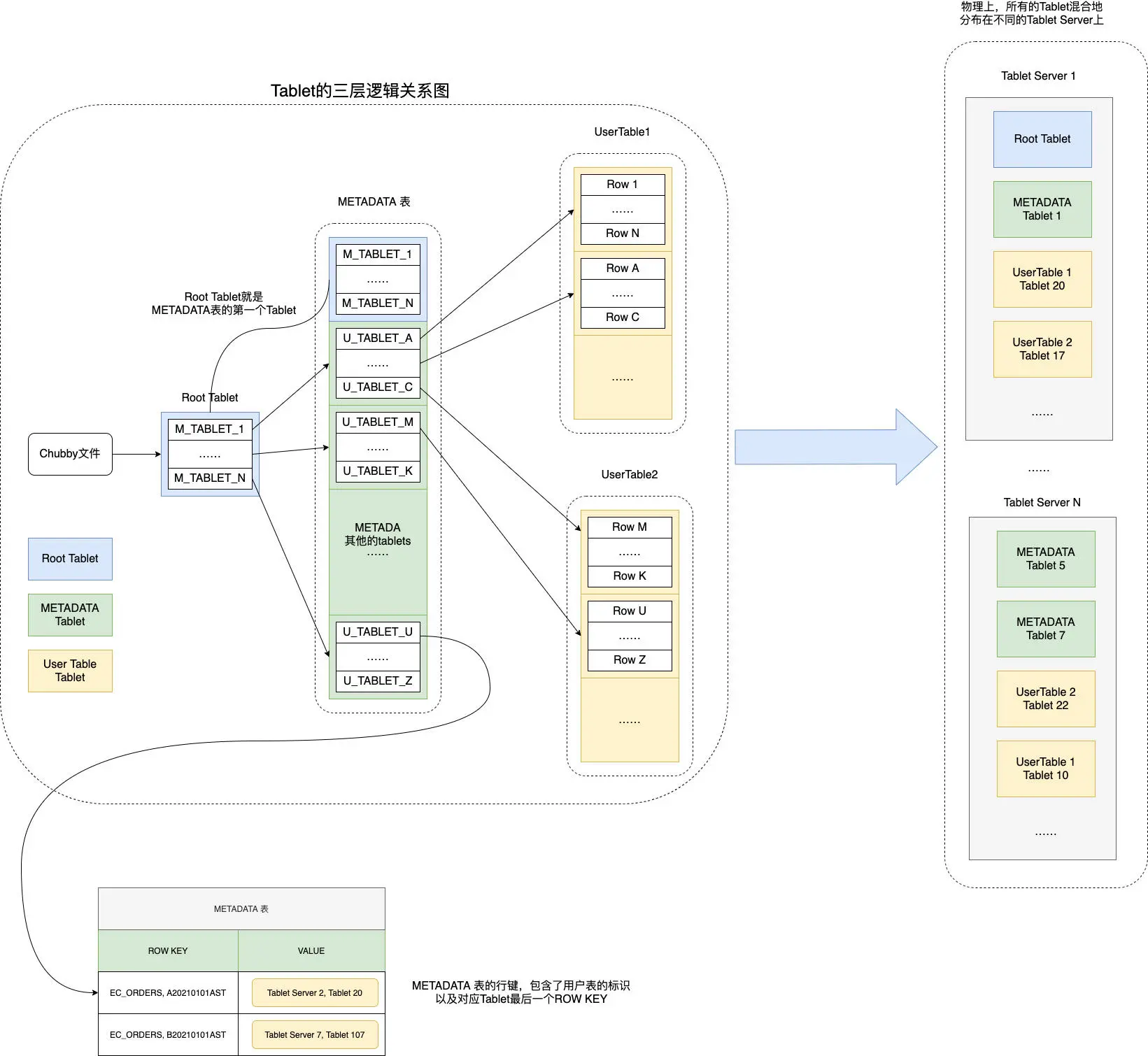
这里我们来看一个具体的 Bigtable 数据读写的例子,来帮助你理解这样一个三层结构。比 如,客户端想要根据订单号,查找我们的订单信息,订单都存在 Bigtable 的 ECOMMERCE_ORDERS 表里,这张要查的订单号,就是 A20210101RST。
那么,我们的客户端具体是怎么查询的呢?
- 客户端先去发起请求,查询 Chubby,看我们的 Root Tablet 在哪里。(第一次查询)
- Chubby 会告诉客户端,Root Tablet 在 5 号 Tablet Server,这里我们简写成 TS5。
- 客户端呢,会再向 TS5 发起请求,说我要查 Root Tablet,告诉我哪一个 METADATATablet 里,存放了 ECOMMERCE_ORDERS 业务表,行键为 A20210101RST 的记录的位置。(第二次查询)
- TS5 会从 Root Tablet 里面查询,然后告诉客户端,说这个记录的位置啊,你可以从TS8 上面的 METADATA 的 tablet 107,找到这个信息。
- 然后,客户端再发起请求到 TS8,说我要在 tablet 107 里面,找ECOMMERCE_ORDERS 表,行键为 A20210101RST 具体在哪里。(第三次查询)
- TS8 告诉客户端,这个数据在 TS20 的 tablet 253 里面。
- 客户端发起最后一次请求,去问 TS20 的 tablet 253,问 ECOMMERCE_ORDERS 表,行键为 A20210101RST 的具体数据。(第四次查询)
- TS20 最终会把数据返回给客户端
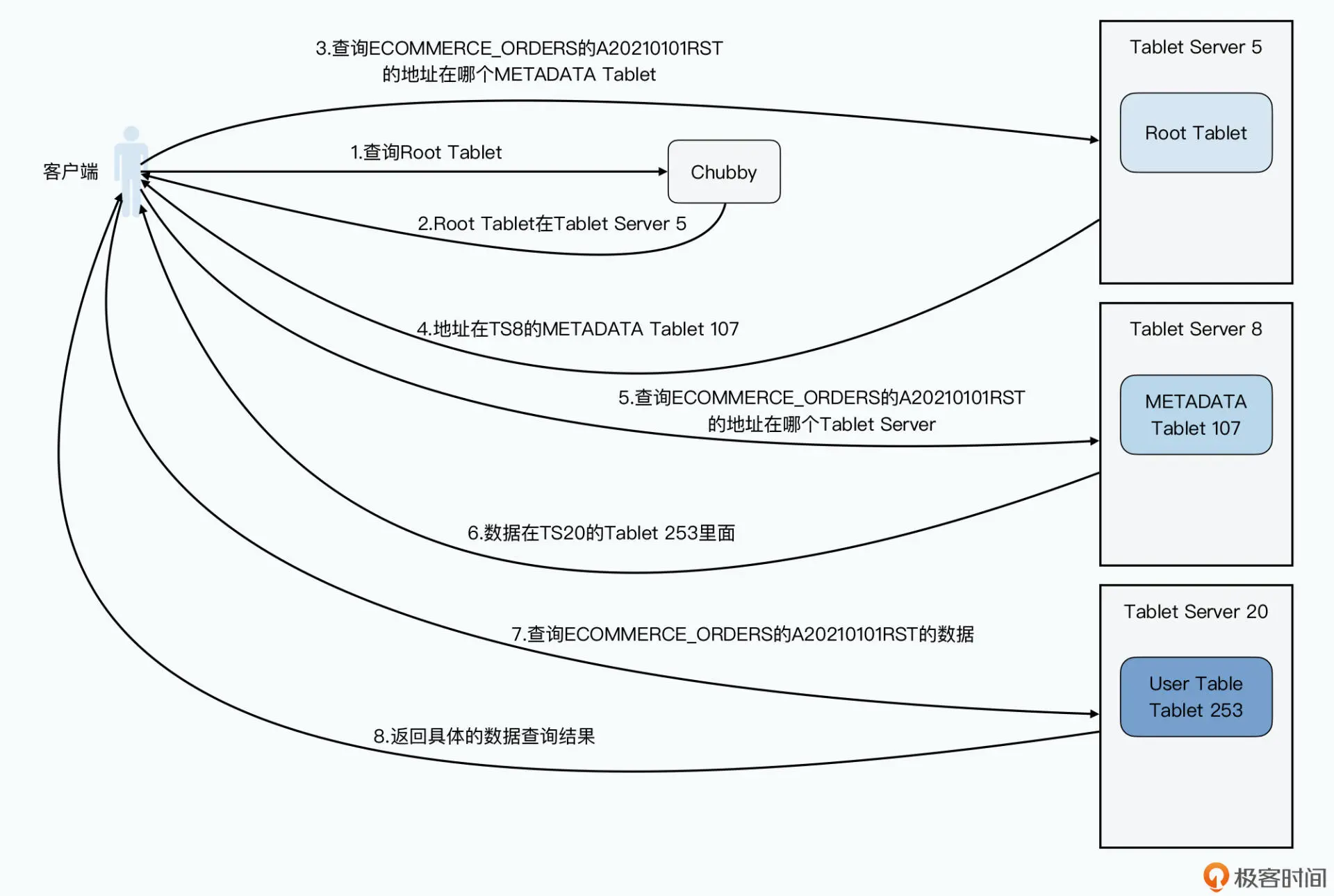
可以看到,在这个过程里,我们用了三次网络查询,找到了想要查询的数据的具体位置, 然后再发起一次请求拿到最终的实际数据。一般我们会把前三次查询位置结果缓存起来, 以减少往返的网络查询次数。而对于整个 METADATA 表来说,我们都会把它们保留在内 存里,这样每个 Bigtable 请求都要读写的数据,就不需要通过访问 GFS 来读取到了。
这个 Tablet 分区信息,其实是一个三层 Tablet 信息存储的架构,而三层结构让 Bigtable 可以“伸缩”到足够大。METADATA 的一条记录,大约是 1KB,而 METADATA 的 Tablet 如果限制在 128MB,三层记录可以存下大约 (128*1000)2=234 个 Tablet 的位 置,也就是大约 160 亿个 Tablet,肯定是够用了。
这个设计带来了一个很大的好处,就是查询 Tablets 在哪里这件事情,尽可能地被分摊到 了 Bigtable 的整个集群,而不是集中在某一个 Master 节点上。而唯一所有人都需要查 询的 Root Tablet 的位置和里面的数据,考虑到 Root Tablet 不会分裂,并且客户端可以 有缓存,Chubby 和 Root Tablet 所在的 Tablet 服务器也不会有太大压力。
另外你还会发现,在整个数据读写的过程中,客户端是不需要经过 Master 的。即使 Master 节点已经挂掉了,也不会影响数据的正常读写。客户端不需要认识 Master 这 个“主人”,也不依赖 Master 这个“主人”为我们提供服务。这个设计,让 Bigtable 更 加“高可用”了。
而如果我们回顾前面整个查询过程,其实就很容易理解,为什么 Chubby 里面存的叫做 Bigtable 的引导位置,因为这个过程和操作系统启动的过程很类似,都是要从一个固定的 位置读取信息,来获得后面的动态的信息。在操作系统里,这个是读取硬盘的第一个扇 区,而在 Bigtable 里,则是 Chubby 里存放 Root Tablet 位置的固定文件。
Master 的调度者角色
的确,在单纯的数据读写的过程中不需要 Master。Master 只负责 Tablets 的调度而已, 而且这个调度功能,也对 Chubby 有所依赖。我们来看一看这个过程是怎么样的:
- 所有的 Tablet Server,一旦上线,就会在 Chubby 下的一个指定目录,获得一个和自己名字相同的独占锁(exclusive lock)。你可以看作是,Tablet Server 把自己注册到集群上了。
- Master 会一直监听这个目录,当发现一个 Tablet Server 注册了,它就知道有一个新的Tablet Server 可以用了,也就是可以分配 Tablets。
- 分配 Tablets 的情况很多,可能是因为其他的 Tablet Server 挂了,导致部分 Tablets没有分配出去,或者因为别的 Tablet Server 的负载太大,这些情况都可以让 Master去重新分配 Tablet。具体的分配策略论文里并没有说,你可以根据自己的需要实现对应的分配策略。
- Tablet Server 本身,是根据是否还独占着 Chubby 上对应的锁,以及锁文件是否还在,来确定自己是否还为自己分配到的 Tablets 服务。比如 Tablet Server 到 Chubby的网络中断了,那么 Tablet Server 就会失去这个独占锁,也就不再为原先分配到的Tablets 提供服务了。
- 而如果我们把 Tablet Server 从集群中挪走,那么 Tablet Server 会主动释放锁,当然它也不再服务那些 Tablets 了,这些 Tablets 都需要重新分配。
- 无论是前面的第 4、5 点这样异常或者正常的情况,都是由 Master 来检测 TabletServer 是不是正常工作的。检测的方法也不复杂,其实就是通过心跳。Master 会定期问 Tablets,你是不是还占着独占锁呀?无论是 Tablet Server 说它不再占有锁了,还是Master 连不上 Tablet Server 了,Master 都会做一个小小的测试,就是自己去获取这个锁。如果 Master 能够拿到这个锁,说明 Chubby 还活得好好的,那么一定是 Tablet Server 那边出了问题,Master 就会删除这个锁,确保 Tablet Server 不会再为 Tablets提供服务。而原先 Tablet Server 上的 Tablets 就会变回一个未分配的状态,需要回到上面的第 3 点重新分配。
- 而 Master 自己,一旦和 Chubby 之间的网络连接出现问题,也就是它和 Chubby 之间的会话过期了,它就会选择“自杀”,这个是为了避免出现两个 Master 而不自知的情况。反正,Master 的存活与否,不影响已经存在的 Tablets 分配关系,也不会影响到整个 Bigtable 数据读写的过程。
整个 Bigtable 是由 4 个组件组成的,分别是:
- 负责存储数据的 GFS;
- 负责作为分布式锁和目录服务的 Chubby;
- 负责实际提供在线服务的 Tablet Server;
- 负责调度 Tablet 和调整负载的 Master。
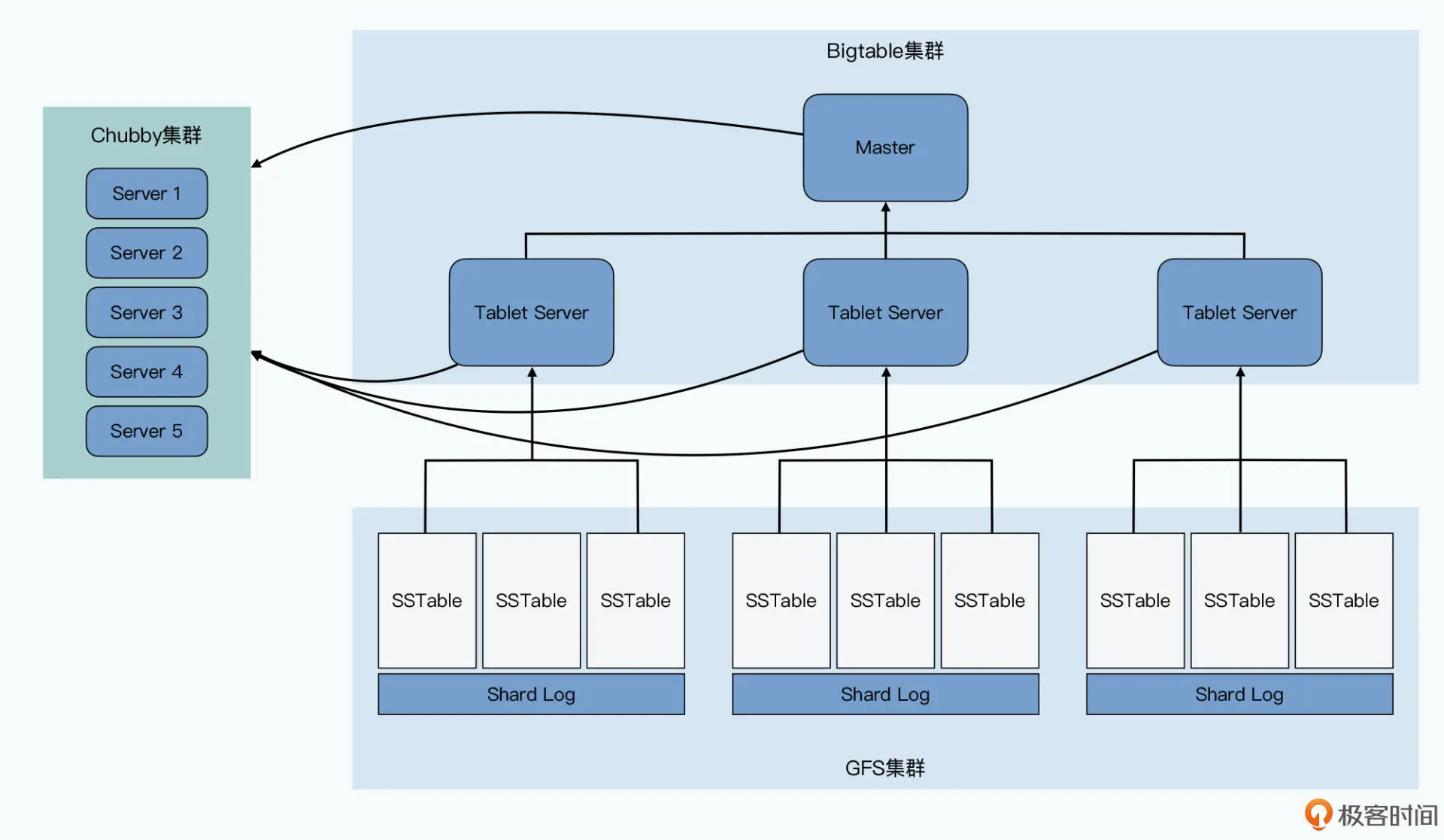
而通过动态区域分区的方式,Bigtable 的分区策略需要的数据搬运工作量会很小。在 Bigtable 里,Master 并不负责保存分区信息,也不负责为分区信息提供查询服务。
Bigtable 是通过把分区信息直接做成了三层树状结构的 Bigtable 表,来让查询分区位置 的请求分散到了整个 Bigtable 集群里,并且通过把查询的引导位置放在 Chubby 中,解 决了和操作系统类似的“如何启动”问题。而整个系统的分区分配工作,由 Master 完 成。通过对于 Chubby 锁的使用,就解决了 Master、Tablet Server 进出整个集群的问 题。
参考链接
https://time.geekbang.org/column/article/421579
文档信息
- 本文作者:ironartisan
- 本文链接:https://ironartisan.github.io/2022/06/21/%E5%A4%A7%E6%95%B0%E6%8D%AE-3.Bigtable%E8%A7%A3%E8%AF%BB/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)