
上海人工智能实验室重磅推出书生·浦语大模型实战营,为广大开发者搭建大模型学习和实践开发的平台,两周时间带你玩转大模型微调、部署与评测全链路。
大模型成为发展通用人工智能的重要途径
- 专用模型:针对特定任务,一个模型解决一个问题
- 通用大模型:一个模型应对多种任务、多种模态
从模型到应用
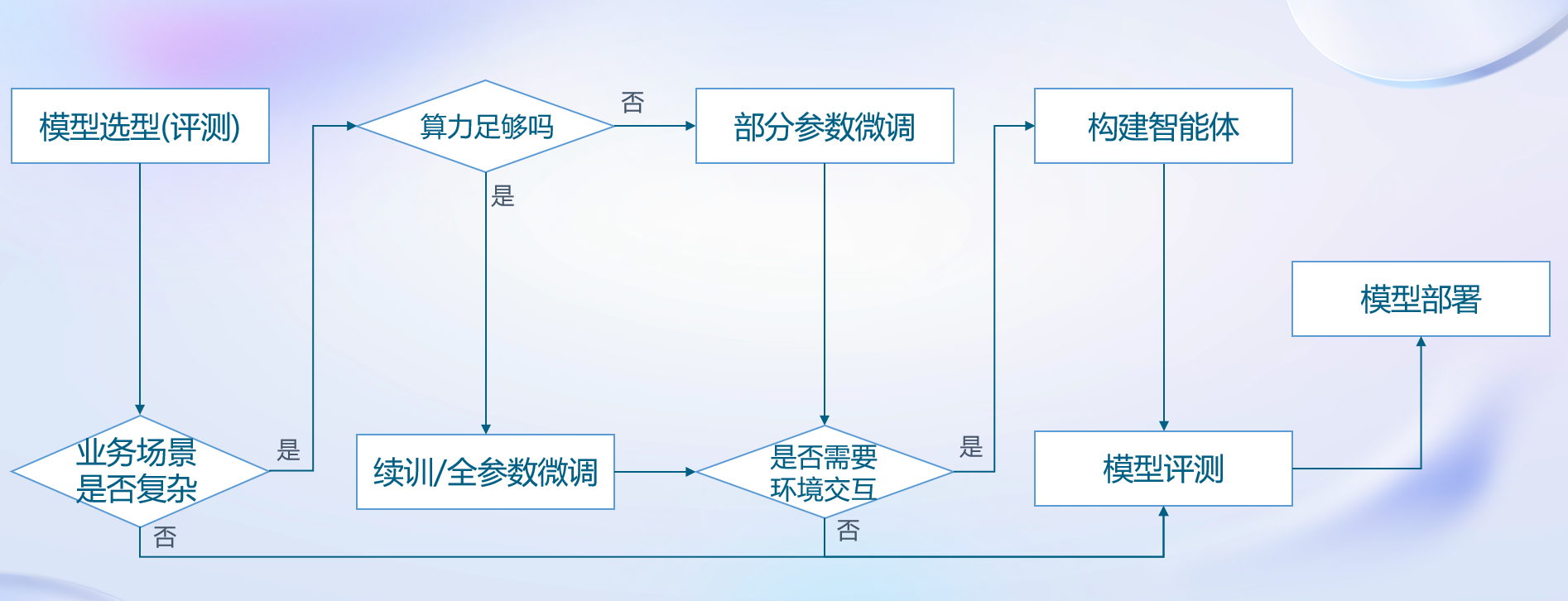
- 模型选型
- 根据模型特点和应用场景选择合适的模型
- 评估业务场景
- 简单:能直接满足业务需求,判断是否需要环境交互
- 不需要环境交互,则直接进行模型评测
- 需要环境交互,构建智能体解决
- 复杂:需要微调
- 简单:能直接满足业务需求,判断是否需要环境交互
- 微调
- 算法足够:进行续训和全参数微调
- 算力不足:利用LoRA、QLoRA等算法进行部分参数微调
- 构建智能体
- 需要环境交互,调用外部API、操作数据库等操作
- 模型评测
- 评测模型能力是否能满足业务需求,若满足,则上线,进行模型部署
- 模型部署
- 考虑硬件环境,对模型进行量化、加速等操作
全链条开源开放体系
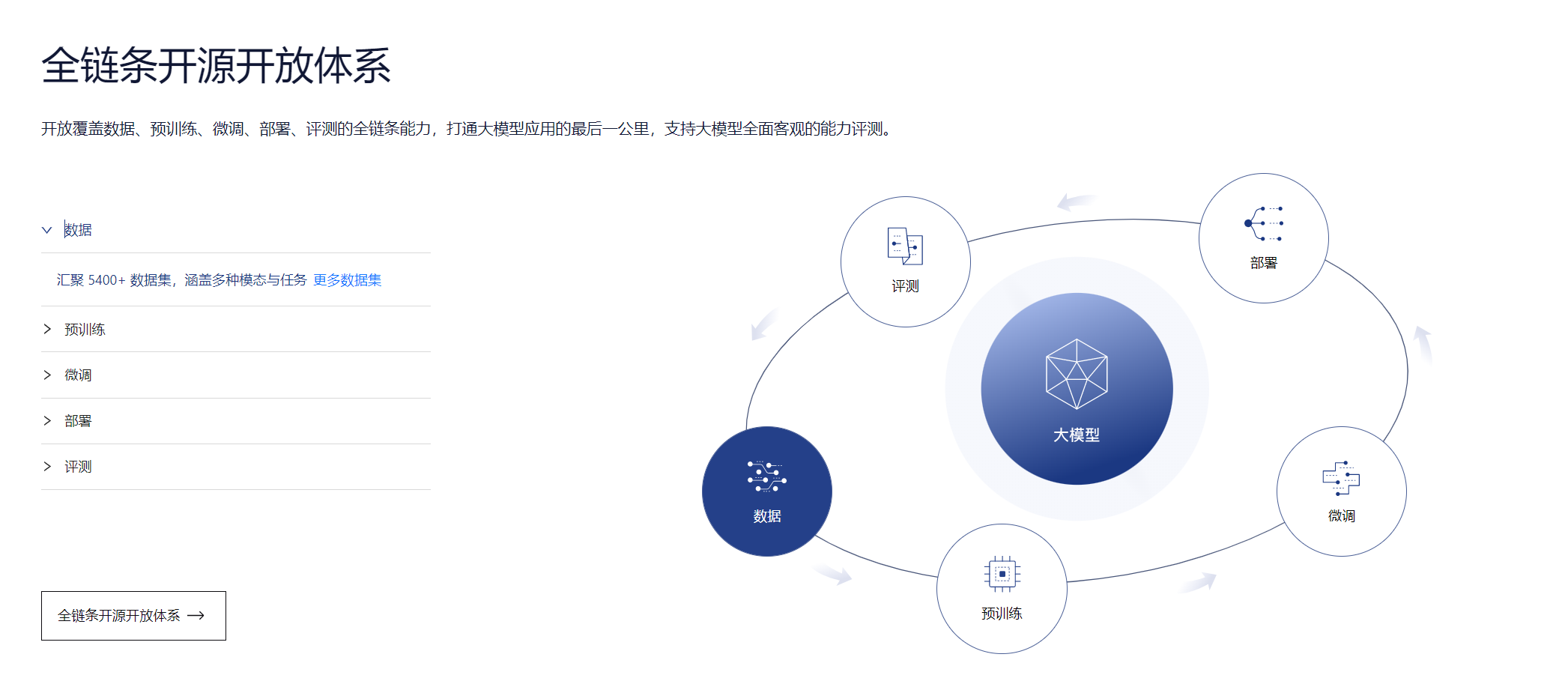
全链条开源开放体系|数据
书生·万卷1.0为书生·万卷多模态语料库的首个开源版本,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。基于大模型数据联盟构建的语料库,上海AI实验室对其中部分数据进行细粒度清洗、去重以及价值对齐,形成了书生·万卷1.0,具备多元融合、精细处理、价值对齐、易用高效等四大特征。
- 在多元融合方面,书生·万卷1.0包含文本、图文、视频等多模态数据,范围覆盖科技、文学、媒体、教育、法律等多个领域,在训练提升模型知识含量、逻辑推理和泛化能力方面具有显著效果。
- 在精细处理方面,书生·万卷1.0经历了语言甄别、正文抽取、格式标准化、基于规则及模型的数据过滤与清洗、多尺度去重、数据质量评估等精细化数据处理环节,因而能更好地适配后续的模型训练需求。
- 在价值对齐方面,研究人员在书生·万卷1.0的构建过程中,着眼于内容与中文主流价值观的对齐,通过算法与人工评估结合的方式,提升了语料的纯净度。
- 在易用高效方面,研究人员在书生·万卷1.0采用统一格式,并提供详细的字段说明和工具指导,使其兼顾了易用性和效率,可快速应用于语言、多模态等大模型训练。
目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
下载地址:https://opendatalab.org.cn/WanJuan1.0
全链条开源开放体系|预训练
InternLM 是一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。通过单一的代码库,它支持在拥有数千个 GPU 的大型集群上进行预训练,并在单个 GPU 上进行微调,同时实现了卓越的性能优化。在1024个 GPU 上训练时,InternLM 可以实现近90%的加速效率。
基于InternLM训练框架,已经发布了两个开源的预训练模型:InternLM-7B 和 InternLM-20B。
InternLM 深度整合了 Flash-Attention, Apex 等高性能模型算子,提高了训练效率。通过构建 Hybrid Zero 技术,实现计算和通信的高效重叠,大幅降低了训练过程中的跨节点通信流量。InternLM 支持 7B 模型从 8 卡扩展到 1024 卡,千卡规模下加速效率可高达 90%,训练吞吐超过 180TFLOPS,平均单卡每秒处理的 token 数量超过3600。
项目地址:https://github.com/InternLM/InternLM

全链条开源开放体系|微调
XTuner 是一个轻量级微调大语言模型的工具库,由 MMRazor 和 MMDeploy 团队联合开发。
- 轻量级: 支持在消费级显卡上微调大语言模型。对于 7B 参数量,微调所需的最小显存仅为 8GB,这使得用户可以使用几乎任何显卡(甚至免费资源,例如Colab)来微调获得自定义大语言模型助手。
- 多样性: 支持多种大语言模型(InternLM、Llama2、ChatGLM、Qwen、Baichuan2, …),数据集(MOSS_003_SFT, Alpaca, WizardLM, oasst1, Open-Platypus, Code Alpaca, Colorist, …)和微调算法(QLoRA、LoRA),支撑用户根据自身具体需求选择合适的解决方案。
- 兼容性: 兼容 DeepSpeed 🚀 和 HuggingFace 🤗 的训练流程,支撑用户无感式集成与使用。
- 轻量级:支持在消费级显卡上的参数大语言模型。对于7B参数量,所需所需的最小显存电流8GB,这使得用户可以使用几乎任何显卡(甚至免费)资源,例如Colab)来获得自定义大语言模型助手。 - 多样性:支持多种大语言模型(InternLM、 Llama2、ChatGLM、Qwen、Baichuan2, …),数据集(MOSS_003_SFT, 羊驼、WizardLM、oasst1, Colorist, …)和变形算法(QLoRA /2305.14314)、LoRA),支持用户根据自身具体需求选择合适的解决方案。 - 兼容性: 兼容 DeepSpeed 🚀 和 HuggingFace 🤗 的训练流程,支持用户无感集成方式与使用。
项目地址:https://github.com/InternLM/xtuner
全链条开源开放体系|评测
OpenCompass 是面向大模型评测的一站式平台。其主要特点如下:
开源可复现:提供公平、公开、可复现的大模型评测方案
全面的能力维度:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
丰富的模型支持:已支持 20+ HuggingFace 及 API 模型
分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
灵活化拓展:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
项目地址:https://github.com/open-compass/opencompass
全链条开源开放体系|部署
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能:
高效推理引擎 TurboMind:开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性,保障了 LLMs 推理时的高吞吐和低延时。
有状态推理:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
量化:LMDeploy 支持多种量化方式和高效的量化模型推理。在不同规模的模型上,验证了量化的可靠性。
项目地址:https://github.com/InternLM/lmdeploy
全链条开源开放体系|智能体
开源了两个Agent相关的框架,分别是Lagent和Agent Lego
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。
- 支持高性能推理 lmdeploy turbomind
- 实现了ReAct,AutoGPT 和 ReWoo 等多种类型的智能体
- 框架简单易拓展,支持 Python 解释器、API 调用和搜索三类常用典型工具
- 灵活支持多个大语言模型. 包括 InternLM、Llama-2 等开源模型和 GPT-4/3.5 等基于 API 的闭源模型
项目地址:https://github.com/InternLM/lagent
Agent Lego 是一个开源的多功能工具 API 库,用于扩展和增强基于大型语言模型(LLM)的智能体(Agent),具有以下突出特点:
- 丰富的多模态扩展工具集,包括视觉感知、图像生成和编辑、语音处理和视觉语言推理等
- 灵活的工具接口,允许用户轻松扩展具有任意类型参数和输出的自定义工具
- 与基于LLM的代理程序框架轻松集成,如 LangChain、Transformers Agent、Lagent
- 支持部署工具服务和远程访问
项目地址:https://github.com/InternLM/agentlego
总结
书生·浦语全链条开源开放体系提供大模型一站式解决方案,包含了数据集、预训练、微调、部署、评测和应用等开源框架:
- 数据(书生·万卷):2TB数据,涵盖多种模态与任务
- 预训练(InternLM-Train):并行训练,极致优化,速度达到 3600 tokens/sec/gpu
- 微调(XTuner):支持 全参数微调,支持LoRA等低成本微调
- 部署(LMDeploy):全链路部署,性能领先,每秒生成 2000+ tokens
- 评测(OpenCompass):全方位评测,性能可复现,80 套评测集,40 万道题目
- 应用(Lagent、AgentLego):支持多种智能体,支持代码解释器等多种工具