机器学习和深度学习综述
人工智能、机器学习、深度学习的关系
三者的关系如 图1 所示,即:人工智能 > 机器学习 > 深度学习。

机器学习(Machine Learning,ML)是当前比较有效的一种实现人工智能的方式。深度学习(Deep Learning,DL)是机器学习算法中最热门的一个分支,近些年取得了显著的进展,并替代了大多数传统机器学习算法。
机器学习
机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。
机器学习的实现原理
机器学习的实现可以分成两步:训练和预测,类似于归纳和演绎:
- 归纳: 从具体案例中抽象一般规律,机器学习中的"训练"亦是如此
- 演绎: 从一般规律推导出具体案例的结果,机器学习中的"预测"亦是如此。
机器学习的实施方法
模型有效的基本条件是能够拟合已知的样本。
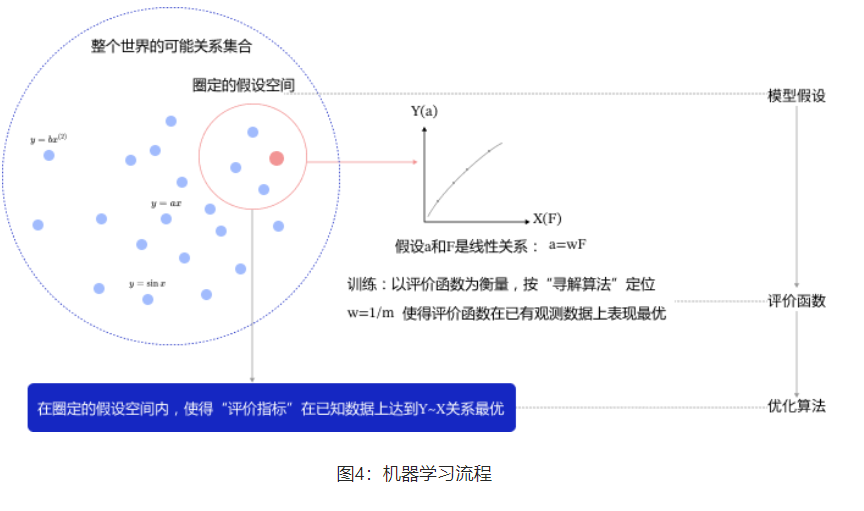
模型假设、评价函数(损失/优化目标)和优化算法是构成模型的三个关键要素。
- 模型假设。假设空间先圈定了一个模型能够表达的关系可能,如红色圆圈所示。机器还会进一步在假设圈定的圆圈内寻找最优的Y~X关系,即确定参数w。
- 评价函数:寻找最优之前,我们需要先定义什么是最优,即评价一个Y~X关系的好坏的指标。通常衡量该关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。
- 优化算法:设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小/最拟合已有观测样本)的Y~X关系找出来,这个寻找最优解的方法即为优化算法。
机器执行学习任务的框架体现了其学习的本质是"参数估计"(Learning is parameter estimation)。
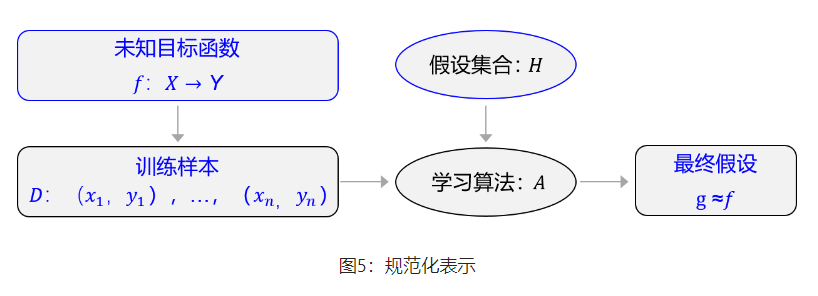
规范化表示如下图所示,末知目标函数 $f$ ,以训练样本 $\mathcal{D}=$ $\left(x_1, y_1\right), \ldots,\left(x_n, y_n\right)$ 为依据。从假设集合 $H$ 中,通过学习算法 $A$ 找到一个函数 $g$ 。如果 $g$ 能够最大程度的拟合训练样本 $\mathcal{D}$ ,那么可以认为函数 $g$ 就接近于目标函数 $f$ 。
深度学习
相比传统的机器学习算法,深度学习做出了哪些改进呢?其实两者在理论结构上是一致的,即:模型假设、评价函数和优化算法,其根本差别在于假设的复杂度。如 图6 第二个示例(图像识别)所示,对于对于美女照片,人脑可以接收到五颜六色的光学信号,能快速反应出这张图片是一位美女,而且是程序员喜欢的类型。但对计算机而言,只能接收到一个数字矩阵,对于美女这种高级的语义概念,从像素到高级语义概念中间要经历的信息变换的复杂性是难以想象。这种变换已经无法用数学公式表达,因此研究者们借鉴了人脑神经元的结构,设计出神经网络的模型,
神经网络的基本概念
人工神经网络包括多个神经网络层,如:卷积层、全连接层、LSTM等,每一层又包括很多神经元,超过三层的非线性神经网络都可以被称为深度神经网络。通俗的讲,深度学习的模型可以视为是输入到输出的映射函数,如图像到高级语义(美女)的映射,足够深的神经网络理论上可以拟合任何复杂的函数。因此神经网络非常适合学习样本数据的内在规律和表示层次,对文字、图像和语音任务有很好的适用性。
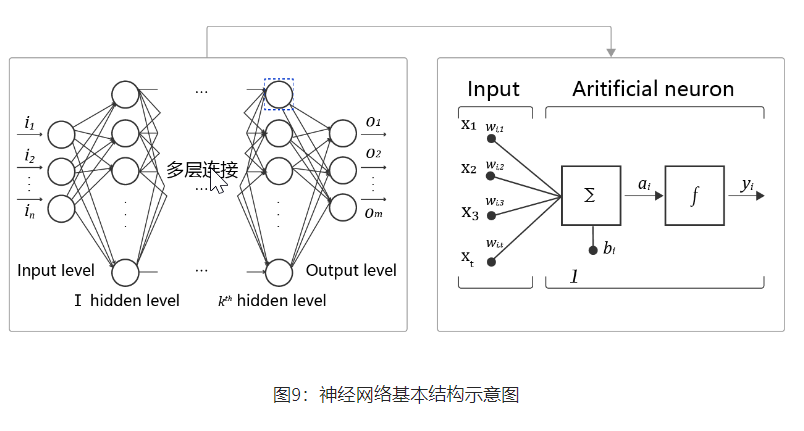
- 神经元: 神经网络中每个节点称为神经元,由两部分组成:
- 加权和:将所有输入加权求和。
- 非线性变换(激活函数):加权和的结果经过一个非线性函数变换,让神经元计算具备非线性的能力。
- 多层连接: 大量这样的节点按照不同的层次排布,形成多层的结构连接起来,即称为神经网络。
- 前向计算: 从输入计算输出的过程,顺序从网络前至后。
- 计算图: 以图形化的方式展现神经网络的计算逻辑又称为计算图,也可以将神经网络的计算图以公式的方式表达:
神经网络本质是一个含有很多参数的"大公式"。
深度学习改变了AI应用的研发模式
实现了端到端的学习
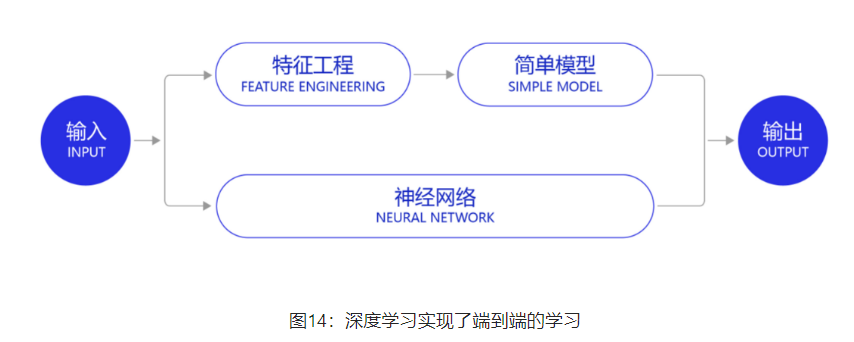
深度学习改变了很多领域算法的实现模式。在深度学习兴起之前,很多领域建模的思路是投入大量精力做特征工程,将专家对某个领域的"人工理解"沉淀成特征表达,然后使用简单模型完成任务(如分类或回归)。而在数据充足的情况下,深度学习模型可以实现端到端的学习,即不需要专门做特征工程,将原始的特征输入模型中,模型可同时完成特征提取和分类任务,如 图14 所示。
实现了深度学习框架标准化
除了应用广泛的特点外,深度学习还推动人工智能进入工业大生产阶段,算法的通用性导致标准化、自动化和模块化的框架产生,如 图15 所示。
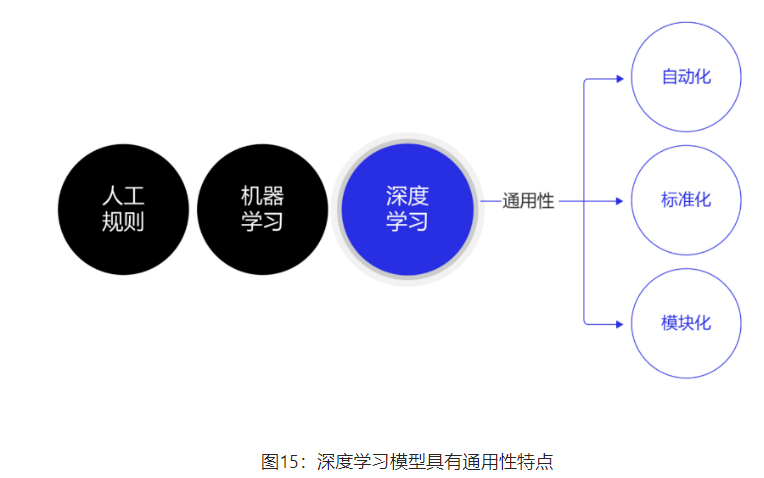
在此之前,不同流派的机器学习算法理论和实现均不同,导致每个算法均要独立实现,如随机森林和支撑向量机(SVM)。但在深度学习框架下,不同模型的算法结构有较大的通用性,如常用于计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),都可以分为组网模块、梯度下降的优化模块和预测模块等。这使得抽象出统一的框架成为了可能,并大大降低了编写建模代码的成本。一些相对通用的模块,如网络基础算子的实现、各种优化算法等都可以由框架实现。建模者只需要关注数据处理,配置组网的方式,以及用少量代码串起训练和预测的流程即可。
人工智能的职业发展空间广阔
哲学家们告诉我们,做我们所喜欢的,然后成功就会随之而来。 —— 沃伦 · 巴菲特 (全球著名的投资家)
人工智能岗位的市场需求旺盛
复合型人才成为市场刚需