处理器体系架构
Y86-64指令集体系结构
定义一个指令集体系结构包括定义各种状态单元、指令集和他们的编码、一组编码规范和异常事件处理。
程序员可见的状态
程序员可见的状态:Y86-64程序中每条指令都会读取或修改处理器状态的某些部分。 在这里我们说的程序员不仅指真的程序员,还包括产生机器级代码的编译器。
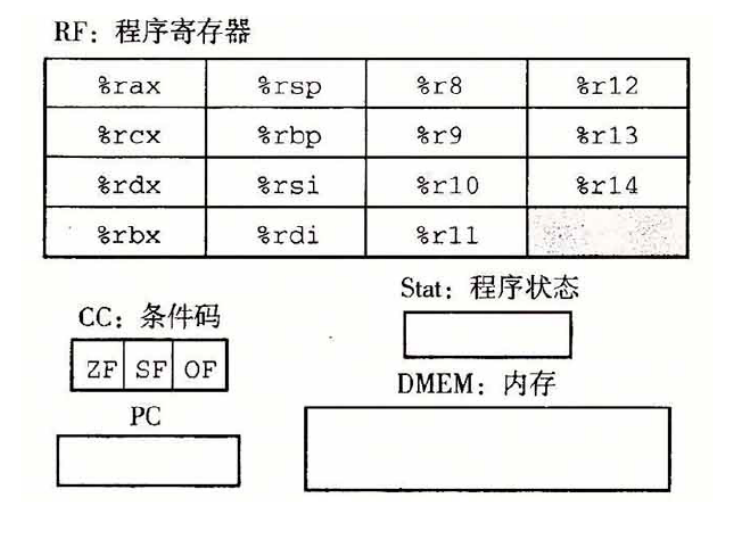
我们定义了 15 个64 位的程序寄存器。相比于 x86,省略了%r15 以简化指令的编码。和 x86 一样,寄存器%rsp 被定义为栈指针,其他 14 个寄存器无固定含义。 此外,我们只保留了 x86 中的零标志(ZF)、符号标志(SF)和溢出标志(OF)。
寄存器%rsp被入栈、出栈、调用和返回指令作为栈指针。程序计数器 PC 用来存放当前正在执行的指令的地址,状态码 Stat 用来表示程序的执行状态。
Y86-64指令
为了简化 x86-64 的指令集,我们将 x86-64 中的 movq 指令分成了 rrmovq、irmovq、rmmovq 和 mrmovq 四种。movq 前面的两个祖母分别表示了源和目的的格式,例如irmovq 的源操作数是立即数(Immediate),目的操作数是寄存器(Register)
指令编码
对于整数的操作,我们定义了四条整数操作指令。和 x86-64 不同,我们定义的指令只允许对寄存器中的数据进行操作
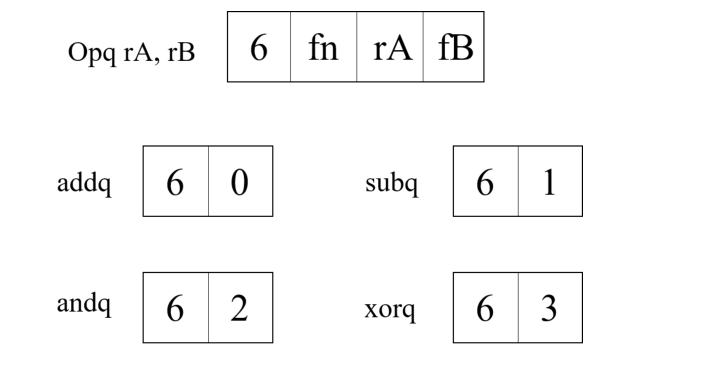
以上四条指令属于同一类型,因此指令代码是一样的,不同的是指令的功能。
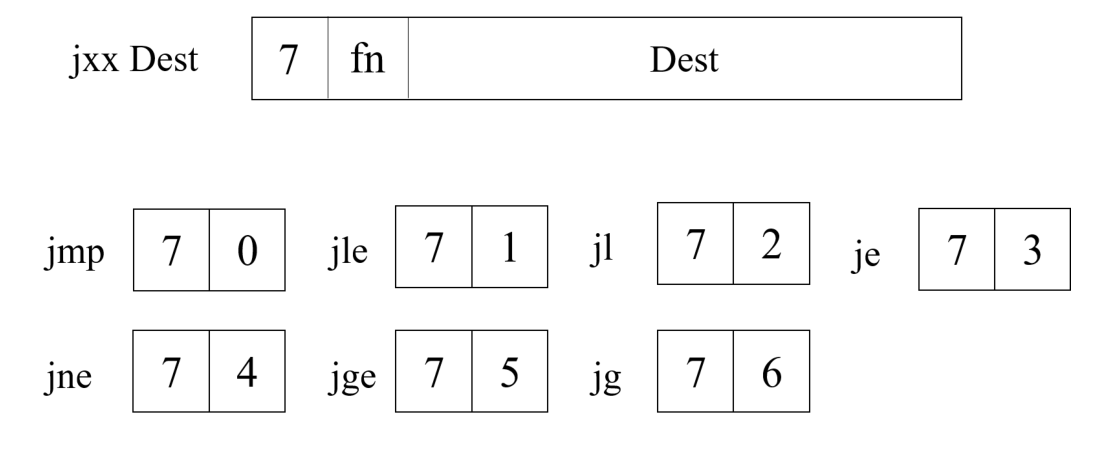
对于跳转,我们定义了 7 条跳转指令,它们的跳转条件和 x86-64 中的跳转指令相同,都是根据条件码的某种组合来判断是否进行跳转:
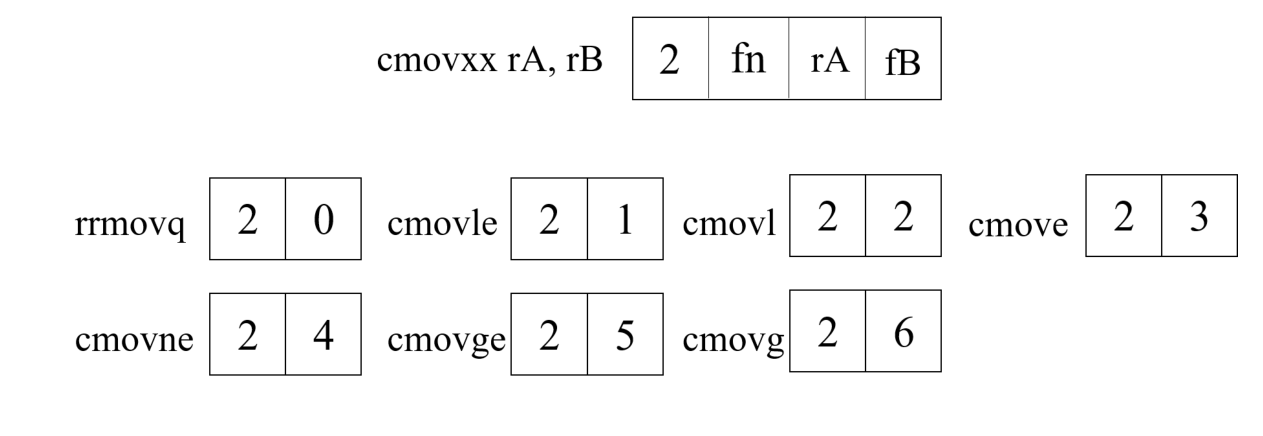
我们定义了 6 条传送指令,它们与数据传送指令 rrmovq 有相同的指令格式,只有条件码满足条件时才会更新目的寄存器的值。
操作指令:
- halt 指令停止指令的执行,执行该指令会导致处理器停止,并将状态码设为HLT。
- nop 指令表示一个空操作。
- call 和 ret 指令分别实现函数的调用和返回。
- push 和 pop 指令分别实现入栈和出栈的操作。
有了如上的指令编码,我们就可以将 Y86-64 的汇编代码翻译成二进制表示了,例如:
rmmovq %rsp, 0x123456789abcd(%rdx)
根据前面 rmmovq 指令的编码定义,该指令二进制表示中的第一个字节为 0x40;指令操作数部分的寄存器%rsp 对应的寄存器编号为 0x4,基址寄存器 rdx 对应的编号为 0x2,因此该指令二进制表示中的第二个字节为 0x42;指令编码中偏移量占 8 个字节,因此我们需要在该偏移量前面补 0 来凑齐 8 个字节。又由于我们采用小端法存储,因此还要对偏移量进行字节反序操作。最终我们得到该指令的二进制表示如下:
40 42 cd ab 89 67 45 23 01 00
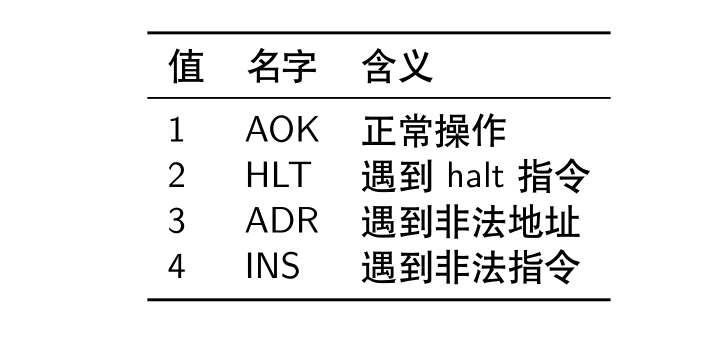
Y86-64 异常
最后,我们看看 Y86-64 中的状态码:
Y86-64的顺序实现
将处理组织成阶段
我们通过一段代码来展示 Y86-64 中 C 语言代码的汇编翻译

这段 C 语言代码的作用是计算一个数组的元素之和,其中指针 start 指向数组的起始位置,count 用于表示数组的长度。
可以看到,除数据传送指令外,Y86-64 的指令与 x86-64 的指令相差不大。
处理器在执行单条指令时,往往也包含着很多操作。我们将 Y86-64 执行指令的过程组织成如下 6 个阶段:
- 取址:处理器执行所有的指令都需要取址。在 Y86-64 指令系统中,指令的长度不是固定的,因此取址阶段需要根据指令代码判断指令是否含有寄存器指示符、是否含有常数来计算当前的指令长度。
- 译码:在译码阶段中,处理器从寄存器文件中读取数据。寄存器文件有两个读端口,可以支持同时进行两个读操作。
- 执行:指令被正式执行的阶段。在该阶段中,算术逻辑单元(ALU)主要执行三类操作:执行算术逻辑运算、计算内存引用的有效地址、针对 push 和 pop指令的运算。
- 访存:顾名思义,对内存进行读写操作的阶段。
- 写回:将执行结果写回到寄存器文件中。
- 更新:将 PC 更新为下一条指令的地址。
subq 指令的各个阶段

如上图所示,
- 取址阶段,根据指令代码来计算指令长度。
- 译码阶段,根据寄存器指示符来读取寄存器的值。
- 执行阶段,ALU 根据译码阶段读取到的操作数以及指令来执行具体的运算,并设置条件码寄存器。
- 访存阶段,由于减法指令不需要读写内存,因此该阶段无操作。
- 写回阶段,将 ALU 的运算结果写回寄存器。
- 更新阶段,更新程序计数器。
irmovq 指令的各个阶段

如前图所示
- 取址阶段,该指令既含有寄存器指示符字节,也含有常数字段。
- 译码阶段,该指令不需要从寄存器中读取数据,译码阶段无操作。
- 执行阶段,虽然该指令仅仅传送数据,看似不需要 ALU,但由于 ALU 的输出端与寄存器的写入端相连,数据的传送还是需要经过 ALU,因此该指令将立即数加 0.
- 访存阶段,该指令不需要读写内存,因此该阶段无操作。
- 写回阶段,将 ALU 的运算结果写回寄存器。
- 更新阶段,更新程序计数器。
rmmovq 指令的各个阶段

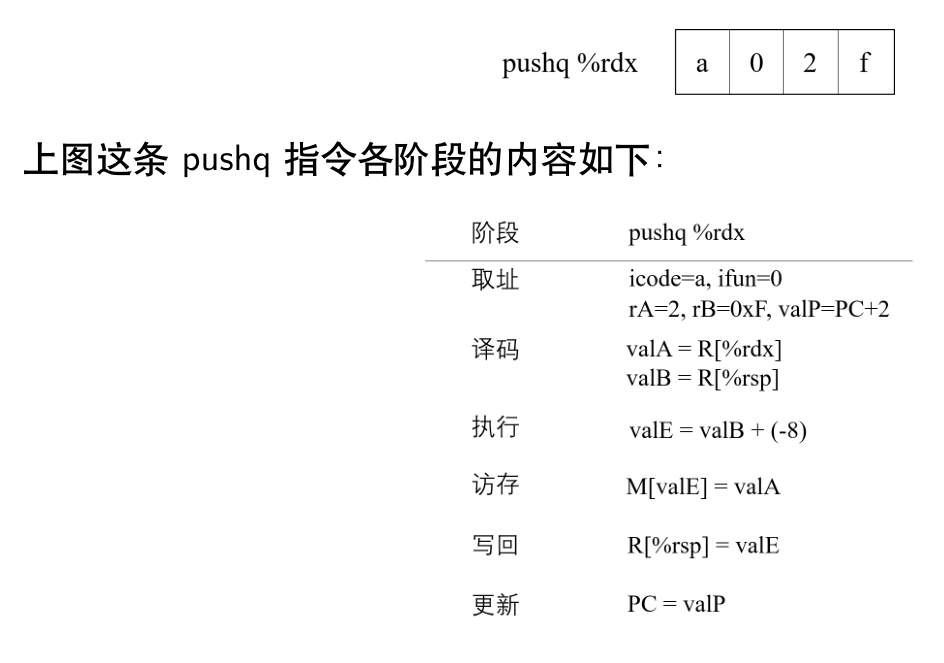
- 取址阶段,该指令既含有寄存器指示符字节,也含有常数字段。
- 译码阶段,从寄存器中读取数据。
- 执行阶段,ALU 根据偏移量和基址寄存器来计算访存地址。
- 访存阶段,将寄存器 rsp 的数值写入内存中。
- 写回阶段,由于内存地址由执行阶段得出并写入寄存器,因此写回阶段不需要进行操作。
- 更新阶段,更新程序计数器。
pushq 指令的各个阶段

je 指令的各个阶段
- 取址阶段,该指令含有常数字段,不含寄存器指示符字节,因此指令长度为 9字节。
- 译码阶段,不需要读取寄存器,无操作。
- 执行阶段,标号为 Cond 的硬件单元根据条件码和指令功能来判断是否执行跳转,该模块产生一个信号 Cnd,若 Cnd = 1,则执行跳转;Cnd = 0 则不执行跳转。
- 访存阶段,无操作。
- 写回阶段,无操作。
- 更新阶段,若 Cnd = 1,将 PC 的值设为 0x040;若 Cnd = 0,则将 PC 的值设为当前值加 9。
取址阶段的硬件设计
在取址阶段中,取址操作以程序计数器(PC)的值为起始地址。由于 Y86-64 指令集中最长的指令占 10 字节,为了保证每次取址操作至少能够获得一条完整的指令,取址操作每次从指令内存中读取 10 各字节。 接下来将这 10 字节分为两部分,第一部分占 1 字节,第二部分占 9 字节。例如编码为 30 f8 08 00 00 00 00 00 00 00 的指令,将被分成 30 和 f80800000000000000。
随后名为 Split 的硬件单元处理第一部分。它将这个字节又分成两部分,每部分占 4个比特位,使这个字节分为两个字段,分别为指令代码和指令功能,用 icode 和ifun 表示。 根据 icode 可以确定当前指令的状态信息,例如指令的合法性。如果 icode 在 0x0到 0xB 之间,那么它就是一条合法指令。此外,通过 icode 还可以判断当前指令是否包含寄存器指示符字节和常数字节。
取址阶段的硬件设计
通过前面说的判断结果,就可以计算出当前指令的长度。例如一个指令既含寄存器指示符字节,又含常数字节,那它的长度就是 10 字节;如果既不含寄存器指示符字节,又不含常数字节,那它的长度就是 1 字节。 与此同时,还可以通过将 PC 值加上当前的指令长度来计算内存中下一条指令的地址,用于后续的更新阶段。
在前面我们处理了一条指令中的头一个字节,对于剩下的 9 个字节,我们通过名为Align 的硬件单元来产生寄存器字段和常数字段。该硬件单元通过信号 need_regids来判断该指令是否包含寄存器指示符字节。若 need_regids = 1,说明该指令包含寄存器指示符字节,那么第一个字节将被分成两部分,每部分占 4 个比特位,然后分别装入寄存器指示符 rA 和 rB 中;若 need_regids = 0,说明该指令不包含寄存器指 示符字节,此时将 rA、rB 这两个字段设置为 0xF。
此外,若该指令含有常数,Align 单元还将产生常数字段 valC。当 need_regids = 1时,valC 被设为指令的第 2 ∼ 9 字节;当 need_regids = 0 时,valC 被设为指令的第 1 ∼ 8 字节。
译码阶段的硬件设计
译码阶段的操作是从寄存器文件中读取数据,在 Y86-64 处理器中寄存器文件有两个读端口,它支持同时进行两个读操作,两个读端口的地址输入为 srcA 和 srcB,从寄存器文件中读出的数值通过 valA 和 valB 输出。 读端口的 srcA 和 srcB 用于产生寄存器的 ID,这需要寄存器指示符 rA 及 rB。由于某些指令,例如 push 指令,该指令的寄存器指示符中只含有目的寄存器的 ID,但执行压栈操作时,还需要获得栈顶指针 rsp 的值。因此 srcA 和 srcB 不仅需要传入 rA 和 rB,还需要传入指令代码 icode。
执行阶段的硬件设计
执行阶段的核心部件 ALU 根据指令功能 ifun 来判断要对输入的操作数进行何种运算。每次运行时,ALU 都会产生三个与条件码相关的信号——零、符号、溢出。 我们只希望 ALU 在执行算术逻辑指令时才设置条件码,而计算内存引用地址以及栈操作时不要设置条件码。因此我们使用 Set_CC 信号根据指令代码 icode 来控制是否需要设置条件码。 此外,我们使用名为 Cond 的硬件单元来控制跳转操作。Cond 会根据指令功能和条件码寄存器来产生 Cnd 信号。对于跳转指令,如果 Cnd = 1,就执行跳转;如果Cnd = 0,则不执行跳转。
访存阶段的硬件设计
该阶段的硬件设计主要包含以下四个控制块:
- 读控制块,用于进行读操作。
- 写控制块,用于进行写操作。
- 内存地址控制块,用于产生内存地址。
- 数据输入控制块,用于输入数据。 除此之外,访存阶段的最后还将根据 icode 判断出的指令有效性以及内存状况产生instr_valid 和 imem_error 信号来计算状态码。
写回阶段的硬件设计
首先为寄存器文件系统添加 M 和 E,这两个写端口,对应的地址输入为 dstE 和dstM。需要注意的是,当执行条件传送指令 (cmov) 时,写入操作还要根据执行阶段计算出的 cnd 信号,当条件不满足条件时,以将目的寄存器设置为 0xF 来禁止写入寄存器文件。
更新阶段的硬件设计
在更新阶段,PC 的值有以下三种情况:
- 当前执行的指令是函数调用指令 call,此使将 PC 值设为 call 指令的常数字段。
- 当前执行的指令是函数返回指令 ret,此使将 PC 值设为 ret 指令在访存阶段从内存中读出的返回地址。
- 当前执行的指令是跳转指令 jxx,此使若满足跳转条件(cnd = 1),则新的 PC值等于跳转指令的常数字段;若不满足跳转条件(cnd = 0),则新的 PC 值等于当前 PC 值加上当前指令长度。
- 数据输入控制块,用于输入数据。