作业1-1至1-8
作业1-1
类比牛顿第二定律的案例,在你的工作和生活中还有哪些问题可以用监督学习的框架来解决?模型假设和参数是什么?评价函数(损失)是什么?
购房时房屋面积x与房屋价格y。模型假设是m,参数是房屋面积x与房屋价格y,评价函数为均方误差。
\[\frac{1}{N} * \sum_{i=1}^n(y-Y)^2\]为什么说深度学习工程师有发展前景?怎样从经济学(市场供需)的角度做出解读?
个人思考:
深度学习其实是一个端到端学习的过程,不需要去了解太多的行业知识和经验,即(input,ouput),有时不需要额外构建特征,数据已经拥有了特征,问题得到了解决,而深度学习工程师所需要做的就是如何去构建这样一个学习的网络。
从市场供需来说,市场对深度学习工程师的需求大于供给,在市场里更受欢迎,在未来一段时间内,具有很好的发展前景。
来自ChatGPT的回答:
深度学习是一种强大的人工智能技术,其在各种领域中的应用正在不断增加,如自然语言处理、计算机视觉、语音识别和推荐系统等。深度学习工程师是能够设计、实现和优化深度学习模型的专业人士,他们在训练数据、模型选择、超参数调整和模型优化等方面具有深厚的专业知识和经验。因此,深度学习工程师在当前和未来的市场上都具有很高的价值。
从经济学的角度来看,市场的供需是影响行业就业和薪资的重要因素之一。当前,随着各行业对深度学习技术的需求不断增加,深度学习工程师的市场需求也在迅速增长。根据数据显示,深度学习工程师的需求已经超过供应,这意味着深度学习工程师是一个供不应求的职业,因此他们在市场上有更好的谈判空间和薪资水平。
此外,随着人工智能技术的不断发展和应用,深度学习工程师的市场需求还将继续增加。根据一些机构的预测,未来几年内,深度学习工程师的需求将会继续保持高速增长,因此这个职业具有非常明显的发展前景。
总之,从经济学的角度来看,深度学习工程师的市场需求不断增长,这意味着这个职业具有很好的发展前景和薪资水平。如果你对深度学习感兴趣,从事深度学习工程师这个职业将会是一个不错的选择。
作业1-2
样本归一化:预测时的样本数据同样也需要归一化,但使用训练样本的均值和极值计算,这是为什么?
个人思考:
目的是为了保证数据的一致性,一版在训练前就会进行数据样本的归一化,均值和极值反映了整个样本数据集的特征分布。
来自ChatGPT的回答:
在机器学习中,样本归一化通常是为了将特征缩放到相似的范围内,这有助于算法更好地收敛并提高模型的准确性。在训练阶段,我们使用训练数据的均值和标准差来进行归一化,因为这些值是从训练数据中计算得出的,可以用于将训练数据中的特征缩放到相似的范围内。
在预测阶段,我们需要对新的输入数据进行相同的归一化处理,以便将其缩放到与训练数据相同的范围内。然而,我们不能使用预测数据的均值和标准差来进行归一化,因为我们不知道这些值。相反,我们使用训练数据的均值和标准差来对新的输入数据进行归一化处理。这是因为,训练数据的均值和标准差反映了整个数据集的特征分布,因此可以应用于新的输入数据。
总之,使用训练数据的均值和极值计算样本归一化是为了保持一致性,并且因为这些值可以反映整个数据集的特征分布。
当部分参数的梯度计算为0(接近0)时,可能是什么情况?是否意味着完成训练?
个人思考:
- 局部最优,并未完成训练。
- 全局最优,可能已经完成了训练。
- 训练出现梯度消失问题,导致梯度为0.
来自ChatGPT的回答:
当部分参数的梯度计算为0或接近0时,可能有以下几种情况:
参数已经收敛到最优值:在这种情况下,梯度为0可能表示该参数已经收敛到最优值。如果其他参数的梯度也为0,则整个模型可能已经完成了训练。
参数已经被限制:在某些情况下,参数可能会被设置为固定的值,例如通过L1或L2正则化。这可能会导致梯度为0。
梯度消失:当使用某些激活函数(例如Sigmoid)和深层神经网络时,可能会出现梯度消失的问题,即梯度在传递过程中逐渐变小,最终变为0。这种情况可能需要采用其他激活函数或调整网络结构。
无论是哪种情况,梯度为0并不意味着模型已经完成训练。模型可能仍然存在其他参数需要调整,以优化模型的性能。此外,梯度为0也可能是由于数值计算或其他错误导致的。因此,我们应该检查模型的性能和其他参数,以确保模型已经完成训练或发现任何问题并进行调整。
作业 1-3
随机梯度下降的batch size设置成多少合适?过小有什么问题?过大有什么问题?提示:过大以整个样本集合为例,过小以单个样本为例来思考。
个人思考:
根据实际情况而定,如果数据集比较大,则batch size设置大一些;
过小虽然对硬件要求不高,但是会增加训练的时间,而且噪声对于梯度的影响也会比较大。 过大会占用太多的资源。
来自ChatGPT的回答:
随机梯度下降(SGD)的batch size通常是一个超参数,需要根据数据集和模型的特性来选择。一般而言,batch size设置得越大,每次更新参数时使用的样本数量就越多,可以使更新方向更加准确和稳定,但也会带来一些问题。
过小的batch size,例如batch size为1,可能会导致随机梯度下降算法非常不稳定,因为每次更新的方向只基于单个样本的梯度,容易受到噪声的影响。此外,过小的batch size会增加计算时间,因为每个小批量的更新操作需要更多次迭代。
过大的batch size,例如batch size为整个数据集,可能会导致算法的收敛速度变慢,因为每次更新时计算的梯度方向可能不够准确,特别是当数据集非常大时。另外,过大的batch size也会占用更多的内存,因为需要在内存中保存更多的样本。
因此,通常建议将batch size设置在一个适当的范围内,一般在32到256之间,具体取决于数据集大小和模型的复杂性。如果数据集比较小或模型比较简单,可以使用较小的batch size;如果数据集非常大或模型非常复杂,可以考虑使用较大的batch size。同时,我们还可以采用学习率衰减策略来控制算法的稳定性和收敛速度。
一次训练使用的配置:5个epoch,1000个样本,batchsize=20,最内层循环执行多少轮?
5*1000/20 = 250
作业1-4
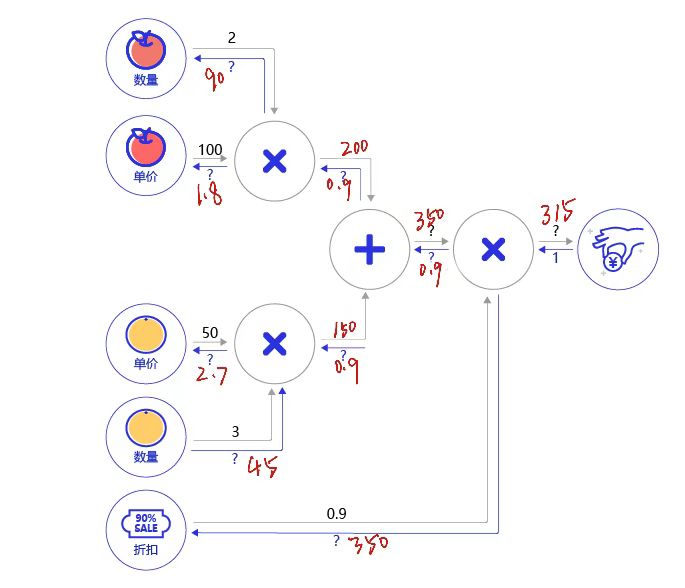
根据 图12 所示的乘法和加法的导数公式,完成 图13 购买苹果和橘子的梯度传播的题目。
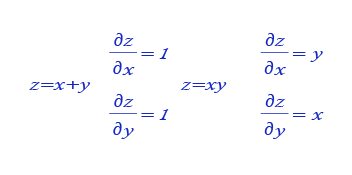
图12:乘法和加法的导数公式</br>
</br>
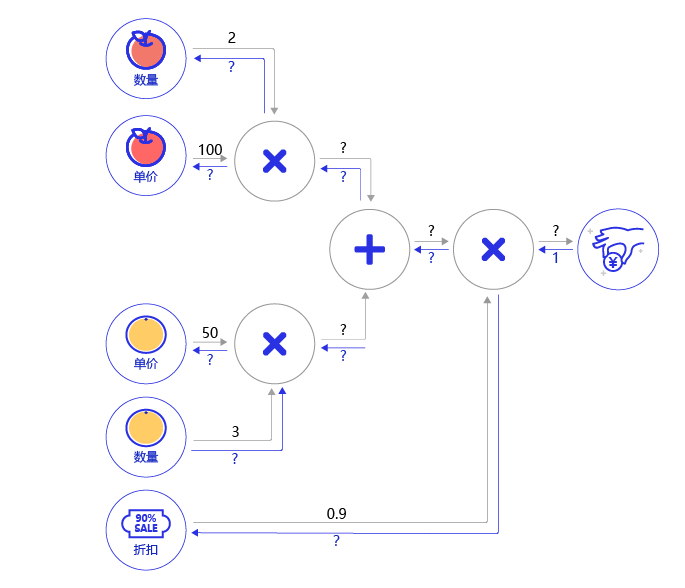
图13:购买苹果和橘子产生消费的计算图</br>
</br>
挑战题:用代码实现两层的神经网络的梯度传播,中间层的尺寸为13【房价预测案例】(教案当前的版本为一层的神经网络),如 图14 所示。
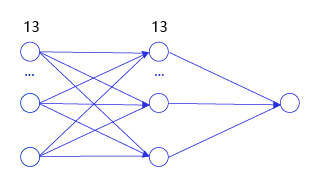
图14:两层的神经网络</br>
</br>
import numpy as np
class Network(object):
def __init__(self, num_of_weight, num_of_hidden=13):
# 随机产生参数
# 隐藏层数量num_fo_hidden
self.w1 = np.random.randn(num_of_weight, num_of_hidden)
self.b1 = np.zeros((num_of_weight, 1))
self.w2 = np.random.randn(num_of_hidden, 1)
self.b2 = 0.
def forward(self, x):
z1 = np.dot(x, self.w1) + self.b1.T
z2 = np.dot(z1, self.w2) + self.b2
return z1, z2
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z1,z2 = self.forward(x)
N = x.shape[0]
gradient_w2 = (z2 - y) * z1
gradient_w2 = np.mean(gradient_w2, axis=0)
gradient_w2 = gradient_w2[:, np.newaxis]
gradient_b2 = (z2 - y)
gradient_b2 = np.mean(gradient_b2)
gradient_w1 = (z2 - y) * z1
gradient_w1 = np.mean(gradient_w1 * np.dot(x, self.w2), axis=0)
gradient_w1 = gradient_w1[:, np.newaxis]
gradient_b1 = (z2 - y)
gradient_b1 = np.mean(gradient_b2 * self.w2)
return gradient_w1, gradient_b1, gradient_w2, gradient_b2
def update(self, gradient_w1, gradient_b1, gradient_w2, gradient_b2, eta=0.01):
self.w1 = self.w1 - eta * gradient_w1
self.w2 = self.w2 - eta * gradient_w2
self.b1 = self.b1 - eta * gradient_b1
self.b2 = self.b2 - eta * gradient_b2
def train(self, training_data, num_epoches, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epoches):
# 在迭代开始之前将训练数据的顺序随机打乱
# 然后在按每次取batch_size条数据的方式取出
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个mini_batch包含batch_size条数据
mini_batches = [training_data[k : k + batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
x = mini_batch[:, : -1]
y = mini_batch[:, -1 :]
a1, a2 = self.forward(x)
loss = self.loss(a2, y)
gradient_w1, gradient_b1, gradient_w2, gradient_b2 = self.gradient(x, y)
self.update(gradient_w1, gradient_b1, gradient_w2, gradient_b2, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.format(epoch_id, iter_id, loss))
return losses
import matplotlib.pyplot as plt
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
#启动训练
losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
作业1-6
在AI Studio上阅读房价预测案例(两个版本)的代码,并运行观察效果。
在本机或服务器上安装Python、jupyter和PaddlePaddle,运行房价预测的案例(两个版本),并观察运行效果。
想一想:基于Python编写的模型和基于飞桨编写的模型在存在哪些异同?如程序结构,编写难易度,模型的预测效果,训练的耗时等等。
相同点:
- 数据处理过程一致,此步骤代码不依赖框架实现,飞浆与使用Python构建房价预测任务的代码相同;
- 模型设计——定义init函数:在类的初始化函数中声明每一层网络的实现函数。在房价预测模型中,只需要定义一层全连接层,模型结构和使用Python和Numpy构建神经网络模型保持一致;
- 训练过程总体逻辑一致,"前向计算输出、根据输出和真实值计算Loss、基于Loss和输入计算梯度、根据梯度更新参数值"四个部分反复执行,直到到损失函数最小。
不同点:
- 模型设计中,飞浆继承paddle.nn.Layer父类,并且在类中定义init函数和forward函数;
- 训练配置中,基于Python实现神经网络模型的案例中,为实现梯度下降编写了大量代码,而使用飞桨框架只需要定义SGD就可以实现优化器设置,大大简化了这个过程;
- 训练过程中,使用飞浆前向计算、计算损失和反向传播梯度,每个操作只需1-2行代码即可实现,框架内部会帮我们自动实现反向梯度计算和参数更新的过程。
作业1-7
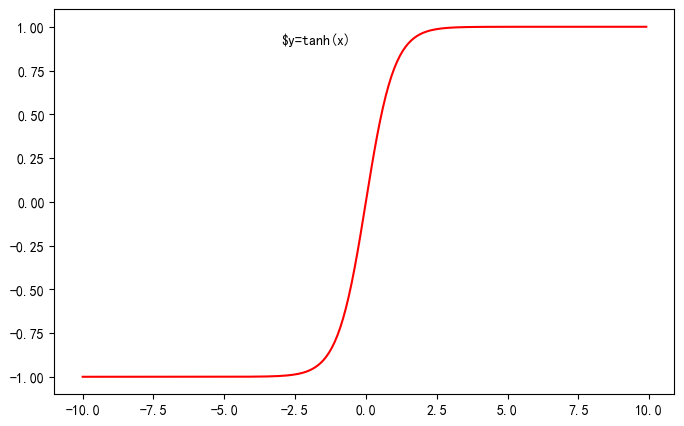
使用NumPy计算tanh激活函数
tanh是神经网络中常用的一种激活函数,其定义如下:
\[y = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}\]请参照讲义中Sigmoid激活函数的计算程序,用NumPy实现tanh函数的计算,并画出其函数曲线。
提交方式:请用NumPy写出计算程序,并画出tanh函数曲线图,$x$的取值范围设置为[-10., 10.]。
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.patches as patches
plt.figure(figsize=(8, 5))
x = np.arange(-10, 10, 0.1)
y=(np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
plt.plot(x,y, color='r')
plt.text(-3.0, 0.9, r'$y=tanh(x)')
plt.show()
作业1-8
统计随机生成矩阵中有多少个元素大于0?
假设使用np.random.randn生成了随机数构成的矩阵:
p = np.random.randn(10, 10)
请写一段程序统计其中有多少个元素大于0?
提示:可以试下使用 $q = (p > 0)$,观察$q$是什么的数据类型和元素的取值。
提交方式:提交计算的代码,能够直接运行输出统计出来的结果。
import numpy as np
p = np.random.randn(10, 10)
s = np.extract(p>0, p)
print(s.size)