注意力机制
什么是注意力机制?
Transformer、BERT等模型在NLP领域取得了突破,其模型主要依赖了注意力机制(Attention Mechanism)。注意力Attention机制被应用到越来越多的地方,那么注意力Attention机制的原理和本质到底是什么?
发展历史
Attention的发展主要经历了两个阶段:
一、2017年前,Attention开始被广泛应用在各类NLP任务上。各种各样的花式Attention被提出,比如用在机器翻译上的Bahdanau Attention等。这一阶段的Attention常常和RNN、CNN结合。
二、2017年之后是Transformer的时代。2017年,Transformer模型被提出,Transformer完全抛弃了RNN结构,突破了RNN无法并行化的缺点。之后BERT使用了Transformer中的Encoder部分。
基本原理
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。从"Attention"这个名字可以读出,Attention机制主要是对注意力的捕捉。Attention的原理与大脑处理信息有一些相似。比如看到下面这张图,短时间内大脑可能只对图片中的"锦江饭店"有印象,即注意力集中在了"锦江饭店"处。短时间内,大脑可能并没有注意到锦江饭店上面有一串电话号码,下面有几个行人,后面还有"喜运来大酒家"等信息。

所以,大脑在短时间内处理信息时,主要将图片中最吸引人注意力的部分读出来了,类似下面。

Attention机制
Attention的输入由三部分构成:Query、Key和Value。其中,(Key, Value)是具有相互关联的KV对,Query是输入的"问题",Attention可以将Query转化为与Query最相关的向量表示。
Attention的计算主要分3步,如下图所示。
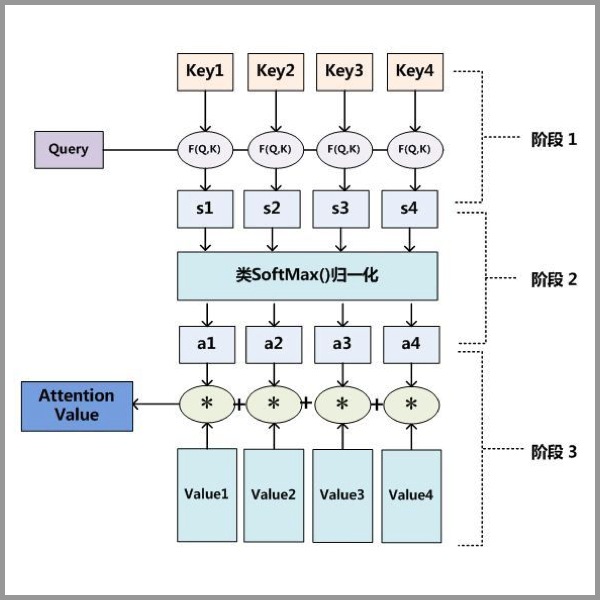
第一步:Query和Key进行相似度计算,得到Attention Score;
第二步:对Attention Score进行Softmax归一化,得到权值矩阵;
第三步:权重矩阵与Value进行加权求和计算。
Query、Key和 Value 的含义是什么呢?我们以刚才大脑读图为例。Value 可以理解为人眼视网膜对整张图片信息的原始捕捉,不受"注意力"所影响。我们可以将 Value 理解为像素级别的信息,那么假设只要一张图片呈现在人眼面前,图片中的像素都会被视网膜捕捉到。Key 与Value 相关联,Key 是图片原始信息所对应的关键性提示信息,比如"锦江饭店"部分是将图片中的原始像素信息抽象为中文文字和牌匾的提示信息。一个中文读者看到这张图片时,读者大脑有意识地向图片获取信息,即发起了一次 Query,Query 中包含了读者的意图等信息。在一次读图过程中,Query 与 Key 之间计算出 Attention Score,得到最具有吸引力的部分,并只对具有吸引力的Value信息进行提取,反馈到大脑中。就像上面的例子中,经过大脑的注意力机制的筛选,一次 Query 后,大脑只关注"锦江饭店"的牌匾部分。
再以一个搜索引擎的检索为例。使用某个Query去搜索引擎里搜索,搜索引擎里面有好多文章,每个文章的全文可以被理解成Value;文章的关键性信息是标题,可以将标题认为是Key。搜索引擎用Query和那些文章们的标题(Key)进行匹配,看看相似度(计算Attention Score)。我们想得到跟Query相关的知识,于是用这些相似度将检索的文章Value做一个加权和,那么就得到了一个新的信息,新的信息融合了相关性强的文章们,而相关性弱的文章可能被过滤掉。
Attention的优点
之所以要引入 Attention 机制,主要是3个原因:
- 参数少
- 模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快
- Attention 解决了 RNN 不能并行计算的问题。Attention 机制每一步计算不依赖于上一步的计算结果,因此可以和 CNN 一样并行处理。
- 效果好
- 在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention分类
总的来说,一种是软注意力(soft attention),另一种则是强注意力(hard attention)。以及被用来做文本处理的NLP领域的自注意力机制。
软注意力机制。可分为基于输入项的软注意力(Item-wise Soft Attention)和基于位置的软注意力(Location-wise Soft Attention) 强注意力机制。可分为基于输入项的强注意力(Item-wise Hard Attention)和基于位置的强注意力(Location-wise Hard Attention)。 自注意力机制。是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
对于基于项的注意力和基于位置的注意力,它们的输入形式是不同的。基于项的注意力的输入需要是包含明确的项的序列,或者需要额外的预处理步骤来生成包含明确的项的序列(这里的项可以是一个向量、矩阵,甚至一个特征图)。而基于位置的注意力则是针对输入为一个单独的特征图设计的,所有的目标可以通过位置指定。
软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
强注意力与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的
最近准备做一个注意力机制的专题,下一篇文章将介绍 Transformer,敬请期待!
参考链接
- https://easyaitech.medium.com/%E4%B8%80%E6%96%87%E7%9C%8B%E6%87%82-attention-%E6%9C%AC%E8%B4%A8%E5%8E%9F%E7%90%86-3%E5%A4%A7%E4%BC%98%E7%82%B9-5%E5%A4%A7%E7%B1%BB%E5%9E%8B-e4fbe4b6d030
- https://lulaoshi.info/machine-learning/attention
- https://blog.csdn.net/hpulfc/article/details/80448570?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-80448570-blog-78422216.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-80448570-blog-78422216.pc_relevant_default&utm_relevant_index=1