论文阅读笔记
001
英文名称: Efficient Estimation of Word Representations in Vector Space
中文名称: 向量空间中词表示的有效估计
期刊/时间:2013
论文地址: https://arxiv.org/abs/1301.3781
痛点及现状
- 简单的技术在很多任务中都具有限制。
- 专注于神经网络学习的单词的分布式表示,因为之前已经证明它们在保持单词之间的线性规律性方面的表现明显优于LSA,此外,LDA 在大型数据集上的计算成本非常高。
- 神经网络语言模型可以通过两步成功训练:首先,使用简单模型学习连续词向量,然后在这些分布式词的表示之上训练N-gram。
方法与创新
- 尝试通过开发新的模型架构来最大限度地提高这些向量运算的准确性,以保持单词之间的线性规律。提出了两种新颖的模型架构,用于从非常大的数据集中计算单词的连续向量表示。
- CBOW
- 类似于前馈 NNLM,其中去除了非线性隐藏层,所有单词共享投影层(不仅仅是投影矩阵);因此,所有单词都被投影到相同的位置(它们的向量被平均)。
- Skip-gram
- 中心词预测输出上下文
- 类似于 CBOW,但它不是根据上下文预测当前单词,而是尝试根据同一句子中的另一个单词最大化对单词的分类。
- CBOW
- 设计了一个新的综合测试集来测量句法和语义规则,并表明可以以高精度学习许多这样的规则。
- 讨论了词向量的维度和训练数据的数量对训练时间和准确性的影响。
实验及结论
- 我们观察到以更低的计算成本显着提高了准确性,即从 16 亿个单词数据集中学习高质量的单词向量只需不到一天的时间
- 我们证明这些向量在我们的测试集上提供了最先进的性能,用于测量句法和语义词的相似性。
- 有些问题可以通过对单词向量表示的代数运算来回答,训练得到的向量可以回答词之间微妙的语义关系。
数据集:
- 定义了一个包含五种语义问题和九种句法问题的综合测试集。总体而言,有 8869 个语义问题和 10675 个句法问题。
- SemEval-2012 Task 2
002
英文名称: Distributed Representations of Words and Phrases and their Compositionality
中文名称: 词和短语的分布式表示及其组合性
期刊/时间:2013
论文地址: https://proceedings.neurips.cc/paper/2013/hash/9aa42b31882ec039965f3c4923ce901b-Abstract.html
痛点及现状
词表示容易受到限制,因为他们不能通过简单词的组合的方式来表示某个单词的惯用短语。
方法与创新
- Skip-gram可以通过对词向量表示,使用基本的数学运算来获得不明显的语言理解程度。
- 对频繁词二次采样,获得了显著的加速和更加规则的词表示。
- 描述了一种称为负采样的方法,用于替换分层Softmax。
- 提出了一种在文本中查找短语的简单方法,并表明学习数百万个短语的良好向量表示是可能的。
实验及结论
- 另一个贡献是负采样算法,这是一种极其简单的训练方法,可以学习准确的表示,尤其是对于频繁出现的单词。
003
英文名称: Distributed representations of sentences and docments
中文名称: 句子和文档的分布式表示
论文地址: http://arxiv.org/abs/1405.4053
代码地址: https://github.com/JonathanRaiman/PVDM
痛点及现状
- BOW存在数据稀疏性和高维性的问题,有两个主要缺点:
- 丢失了词的顺序
- 忽略了词的语义,或者单词之间的距离
之前学习向量表示的方法存在缺陷:
- 词向量的加权平均,它以与标准词袋模型相同的方式丢失词序。
- 使用解析树组合词向量,已被证明仅适用于句子,因为它依赖于解析。
方法与创新
- 虽然段落向量在段落之间是唯一的,但词向量是共享的。在预测时,通过固定词向量并训练新的段落向量直到收敛来推断段落向量。
- 与之前的一些方法不同,它是通用的并且适用于任何长度的文本:句子、段落和文档。它不需要对词权函数进行特定于任务的调整,也不依赖于解析树。
- 与word2vec不同,将paragraph和word平均或结合来预测下个词
- Paragraph向量解决了词袋模型的缺点。
- 继续了word2vec的重要特性:词的语义
- 将词的顺序考虑在内
- 之前的方法受限于句子,我们的方法不需要解析,可以生成包含很多句子的长文档表示,相比更加通用。
实验及结论
分别从两方面进行实验验证:
- Sentiment Analysis
- 在Stanford sentiment treebank数据集和IMDB上表现SOTA
- Information Retrieval
- 在新建数据集上表现SOTA
004
英文名称:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
中文名称:基于联合学习对齐和翻译的神经机器翻译
论文地址: http://arxiv.org/abs/1409.0473
期刊/时间:ICLR 2015
痛点及现状
编码器-解码器方法的一个潜在问题是神经网络需要能够将源句子的所有必要信息压缩到一个固定长度的向量。,使得神经网络难以处理长句子,随着输入句子长度的增加,编码器-解码器的性能会逐渐下降。
方法与创新
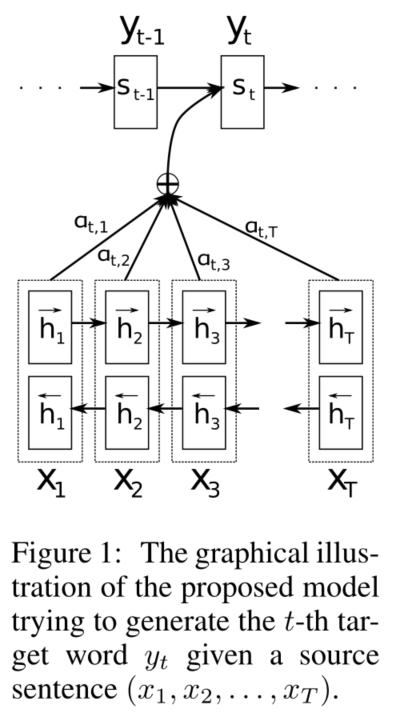
- 没有将输入编码到固定维度向量,将输入的句子编码成变长向量序列
- 提出了一种模型RNNsearch,包括一个双向RNN作为编码器和一个解码器
- 使用BiRNN结构同时对当前单词的前面和后面的信息进行编码
- 解码器中引入注意机制,对输入的隐藏状态求权重,使得解码器可以相应地有选择地检索。
实验及结论
数据集: ACL WMT '14
- RNNsearch比传统的encoder-decoder模型表现更好,在长句子上更具有鲁棒性。
- 翻译性能与现有的基于短语的统计机器翻译能力相当。
005
英文名称: Attention Is All You Need
中文名称: Attention Is All You Need
论文地址: http://arxiv.org/abs/1706.03762
期刊/时间: NIPS 2017
痛点及现状
- 递归模型固有的顺序性使得模型只能串行计算
- 固定长度的上下文向量无法对长语句做有效编码,会遇到信息瓶颈,产生信息丢失的情况
方法与创新
- 提出一种新的序列模型:完全基于注意力机制
- 在标准的WMT翻译数据集上达到了state-of-the-art的结果
- 模型很快:并行的矩阵乘法
实验及结论
- 做了消融实验
- Machine Translation
- 在数据集WMT 2014上表现SOTA
- English Constituency Parsing
- 在数据集WSJ 23上表现SOTA
006
英文名称: GloVe: Global Vectors for Word Representation
中文名称: 基于全局共现信息的词表示
论文地址: https://aclanthology.org/D14-1162.pdf
期刊/时间: EMNLP 2014
痛点及现状
第一类方法是基于统计并且依赖矩阵分解 (例如LSA,HAL) 。虽然这类方法有效地利用了全局的信息,它们主要用于捕获单词的相似性,但是对例如单词类比的任务上表现不好。
第二类方法是基于浅层窗口 (例如,Skip-Gram和CBOW 模型) ,这类模型通过在局部上下文窗口通过预测来学习词向量。
方法与创新
Glove利用全局统计量,以最小二乘为目标,预测单词 $j$ 出现在单词 $i$ 上下文中的概率。
- 提出了一种新的词表示方法
- 考虑全局信息
- 理论可解释
- 加入了一种权重函数来衡量高频词
- 首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。
实验及结论
- 最近的词类比任务中的表现达到了75%,同时在相似性任务和命名实体识别任务上表现SOTA。

007
英文名称: Skip-Thought Vectors
中文名称: 跳跃思维句表示
论文地址: http://arxiv.org/abs/1506.06726
期刊/时间: NIPS 2015
痛点及现状
- 在一段话中,句子与其上下句总是存在某种语义关系的,能否通过一个句子预测上下文的句子?
方法与创新
- 提出了一种新的句表示方法
- 考虑了句子之间的关系
- 利用无监督语料
- 证明了一次训练多次使用的可能性
- 以词向量学习为灵感,提出了一个目标函数,将 skip-gram 模型抽象到句子层面。也就是说,我们不是用一个词来预测它周围的语境,而是对一个句子进行编码来预测它周围的句子。因此,任何组合运算符都可以被替换为句子编码器,只有目标函数会被修改

模型方法:
- 模型使用编码器解码器架构。使用了一个带有GRU激活的RNN编码器和一个带有条件GRU的RNN解码器
- 一个编码器将单词映射到一个句子矢量,一个解码器用来生成周围的句子。
- 损失函数:
- 通过前(后)句子中t前面的词计算t位置的词。 \(\sum_t \log P\left(w_{i+1}^t \mid w_{i+1}^{<t}, \mathbf{h}_i\right)+\sum_t \log P\left(w_{i-1}^t \mid w_{i-1}^{<t}, \mathbf{h}_i\right)\)
实验及结论
数据集:
- 语句相关性:SemEval 2014
- 释义检测(给出两句话,判断是否被改写):Microsoft Research Paraphrase Corpus
- 图像句子排序:Microsoft COCO
- 分类基准数据集:电影评论的情感(MR)、客户产品的评论(CR)、主客观分类(SUBJ)、意见分类(MPQA)和问题类型分类(TREC)
在8个任务上表现SOTA。
008
英文名称: Convolutional Neural Networks for Sentence Classification
中文名称: 基于卷积神经网络的句子分类
论文地址: http://arxiv.org/abs/1408.5882
期刊/时间: EMNLP 2014
痛点及现状
方法与创新
实验及结论
030
英文名称: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
中文名称: 用于语言理解的深度双向变换器的预训练
论文地址: https://arxiv.org/abs/1810.04805
期刊/时间: NAACL 2019
痛点及现状
- 将预先训练好的语言表示应用到下游任务有两种现有策略:基于特征(feature-based)和微调(fine-tuning)。
- 基于特征的方法:ELMo。使用特定任务的架构,将预训练的表示作为附加功能。
- 微调的方法:OpenAI GPT。引入最小的特定任务参数,并通过简单地微调所有预训练的参数对下游任务进行训练。
- 这两种方法在预训练过程中共享相同的目标函数,它们使用单向语言模型学习一般的语言表示。
- 目前的技术限制了预训练表示的能力,标准语言模型的局限性是单向的,限制了在预训练期间架构的选择。
方法与创新
- 针对单向transformer难以捕捉句子中逆序词对的联系的问题,提出了Masked LM,也就是双向transformer,通过Mask词两边的词预测Mask词;
- 针对sentence-level的NLP问题,提出了NSP (Next Sentence Prediction),把上下文句子对关系进行训练
实验及结论
在11个NLP任务上表现SOTA。
031
英文名称: Deep Residual Learning for Image Recongnition
中文名称:
论文地址: https://arxiv.org/pdf/1512.03385.pdf
期刊/时间:
痛点及现状
深度神经网络很难训练 问题1:神经网络叠的越深,则学习出的效果就一定会越好吗?
但其中一个障碍是常见的梯度消失/爆炸问题,它从一开始就阻碍了收敛。这个问题已经通过归一化初始化和中间归一化层得到了很大程度的解决,例如SGD可以使具有数十层的网络开始收敛,
问题2:随着网络深度的增加,准确性变得饱和,然后迅速下降。
这种退化并不是由过拟合引起的,在适当深度的模型中增加更多的层数会导致更高的训练误差。
方法与创新
- 提出了一个残差学习框架来简化网络的训练
实验及结论
032
英文名称: Informative Text Generation from Knowledge Triples
中文名称:
论文地址: https://arxiv.org/abs/2209.12733
期刊/时间:
痛点及现状
研究问题:将一组三元组转换为人类可读的句子。
定义了一种新问题:Informative Text Generation (ITG)
需要模型能检索从memory中自动检索相关知识,生成一些输入三元组并未传递的额外叙述的文本。
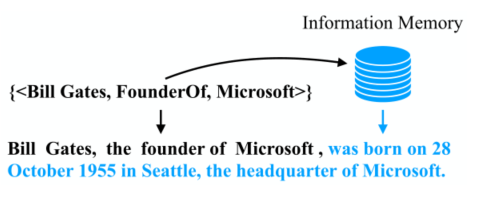
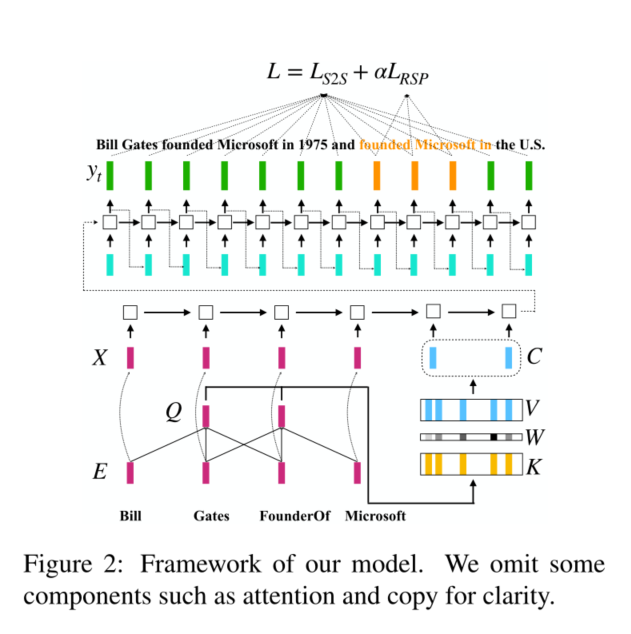
方法与创新
模型包含两个部分:信息memory 和 seq2seq
- 在信息memory中,在训练阶段随机丢弃部分输入三元组,使得目标句子包含比剩余输入三元组更多的信息。
- 设计一个查询器,根据剩余的输入三元组从memory中捕获相关信息
- 最后seq2seq网络根据上一步获取的循序和剩余的三元组生成输出句子
033
英文名称: Distilling the knowledge in a neural network.
中文名称: 神经网络中的知识蒸馏
论文地址: https://arxiv.org/pdf/1503.02531.pdf
期刊/时间: NIPS 2014
痛点及现状
- 使用集成模型进行预测是很麻烦的,而且计算成本太高,不允许大规模部署,特别是如果单个模型是大型神经网络。
方法与创新
实验及结论
034
英文名称: A Frustratingly Easy Approach for Entity and Relation Extraction
中文名称:
论文地址: https://arxiv.org/pdf/2010.12812.pdf
期刊/时间:
痛点及现状
方法与创新
实验及结论
035
英文名称: ZS-BERT: Towards Zero-Shot Relation Extraction with Attribute Representation Learning
中文名称:
论文地址: https://arxiv.org/abs/2104.04697
期刊/时间: NAACL 2021
痛点及现状
方法与创新
实验及结论
036
英文名称: Zero-Shot Relation Extraction via Reading Comprehension
中文名称:
论文地址: https://arxiv.org/abs/1706.04115
期刊/时间: CoNLL 2017
痛点及现状
方法与创新
实验及结论
086
英文名称: ZS-BERT: Towards Zero-Shot Relation Extraction with Attribute Representation Learning
中文名称: ZS-BERT:利用属性表征学习实现零样本关系提取
论文地址: https://arxiv.org/abs/2104.04697
期刊/时间: NAACL 2021
代码地址: https://github.com/dinobby/ZS-BERT
痛点及现状
- 预测在训练阶段无法观察到的未见关系工作较少
方法与创新
- 通过结合可见数据集与不可见关系的文本描述来解决零样本问题
- 通过损失函数,共同最小化输入句子和它们的关系描述组成的训练实例之间的距离,对看到的关系进行分类,将句子和关系描述投射到一个嵌入空间
实验及结论
在WikiZS和FewRel数据集上表现SOTA。
思考与想法
- 损失函数的设计值得参考。
- 解决零样本问题的方式值得借鉴。
087
英文名称: Prompt Consistency for Zero-Shot Task Generalization
中文名称: 零样本任务泛化的提示一致性
论文地址: https://arxiv.org/abs/2205.00049
期刊/时间: 2022
论文地址: https://github.com/violet-zct/swarm-distillation-zero-shot
代码地址: https://github.com/violet-zct/swarm-distillation-zero-shot?utm_source=catalyzex.com
痛点及现状
- 与使用少量特定任务标签数据训练的系统相比,零样本的性能往往仍然比较低。
- 零样本数据无验证数据集,训练停止条件设计困难。
- 模型会进入对所有输入,所有prompt都预测同一个标签的局部最优,来获得一个较高的一致性。
方法与创新
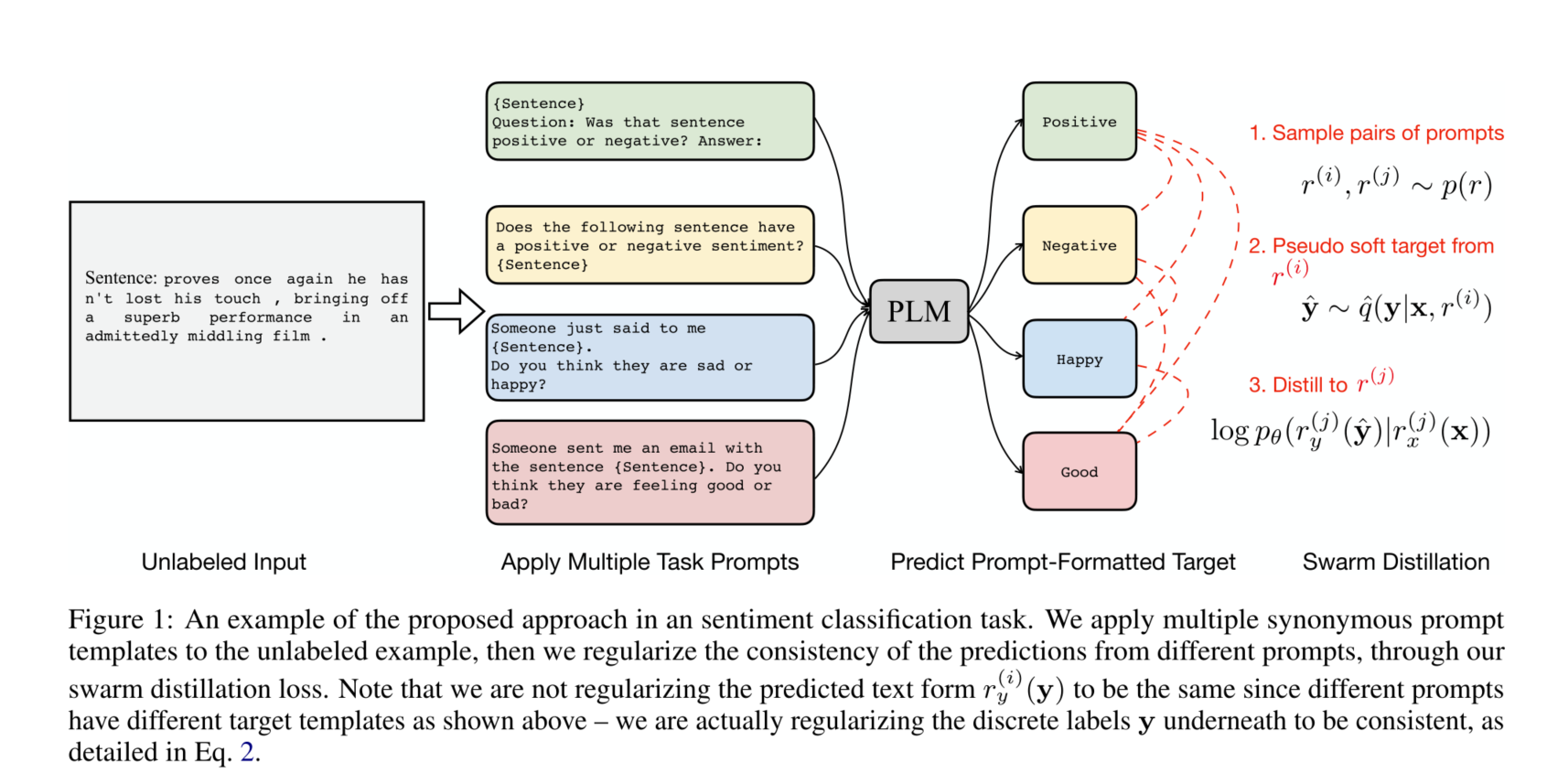
- 将多个同义的提示模板应用于未标记的例子,然后通过我们的Swarm Distillation损失,将不同提示的预测结果的一致性规范化。请注意,我们并没有将预测的文本形式规范化,因为不同的提示有不同的目标模板,如上图所示–我们实际上是将离散的标签y在下面规范化为一致的
- 对于同一数据,在不同prompt的预测结果中,增加prompt consistency,约束结果一致性。通过一致性地增强,来提高模型的zero-shot能力。
- 只更新少量的额外参数,通过固定原始PLM参数自然地缓解灾难性遗忘
- 在无验证集的情况下,提出一个无监督的标准,用于在模型落入崩溃的局部最优之前选择检查点
实验及结论
在数据集上表现SOTA。
思考与想法
- 损失函数的设计值得参考。
- 解决零样本问题的方式值得借鉴。
088
英文名称: ZEROGEN: Efficient Zero-shot Learning via Dataset Generation
中文名称: 基于数据集生成的高效零样本学习
论文地址: https://arxiv.org/abs/2202.07922
期刊/时间: 2022
代码地址: https://github.com/jiacheng-ye/ZeroGen
痛点及现状
方法与创新
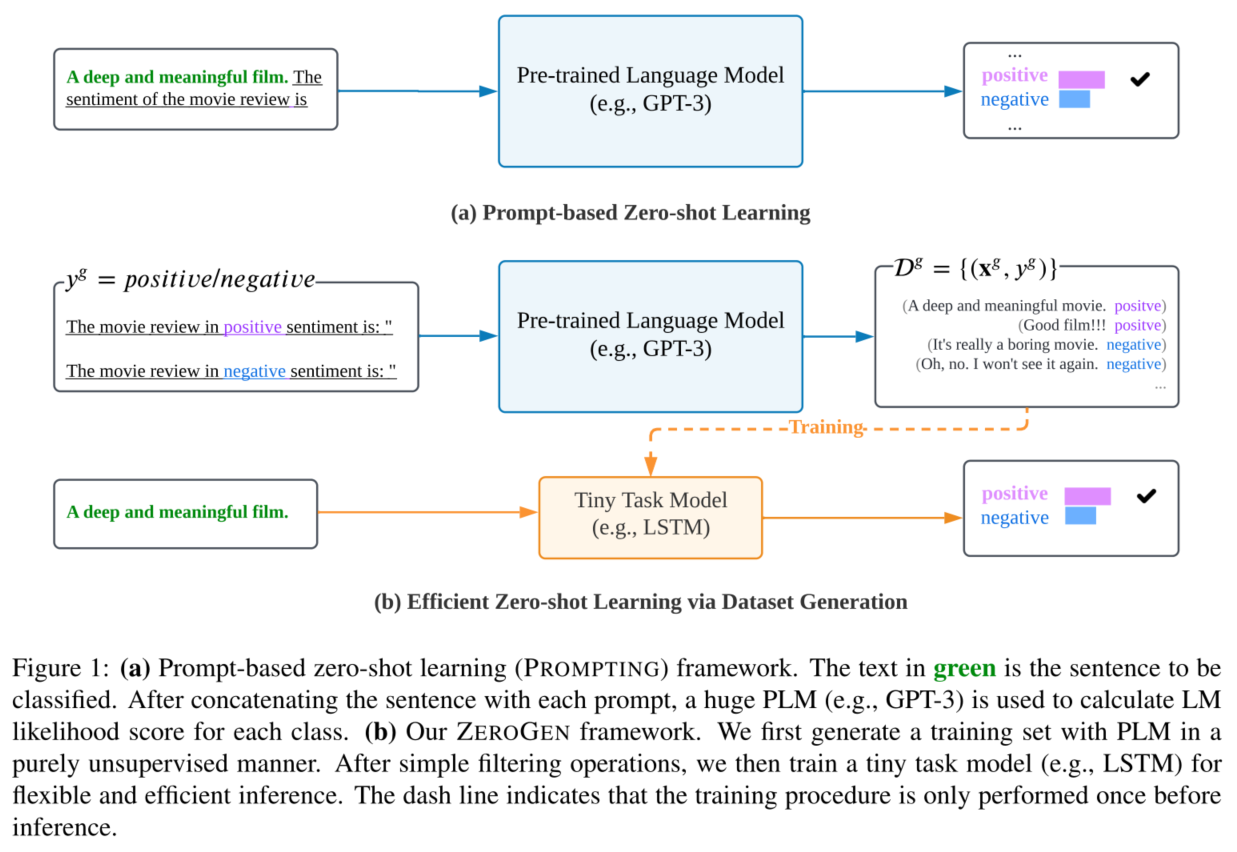
ZEROGEN框架分为三个阶段:
- 第一阶段的目标是利用PLM的生成能力来合成一个数据集,以解决下游的任务。通过精心设计的提示和强大的PLM,生成的数据集被认为包含了丰富的特定任务知识。
- 首先均匀采样类标签集合,然后使用PLM模型生成样本数据。
- 基于如上合成的伪数据集,然后本文训练一个微小的任务模型(TAM)来解决这个任务。TAM可以与任何特定任务的归纳偏见相结合,并且比PLM小一个数量级。
- 最后,本文使用训练好的模型对目标任务进行有效推理。在整个过程中,不涉及任何人为注释,因此评估设置是纯粹的零样本。
实验及结论
在数据集上表现SOTA。
思考与想法
- 解决零样本问题的方式值得借鉴。
- 实验对比的方式值得借鉴。
090
英文名称: InPars: Data Augmentation for Information Retrieval using Large Language Models
中文名称: InPars:使用大型语言模型进行信息检索的数据增强
论文地址: https://arxiv.org/abs/2202.05144
期刊/时间: 2022
代码地址: https://github.com/zetaalphavector/inpars
痛点及现状
- 现在的大多数方法都是使用大型LM直接用于信息检索。
方法与创新
- 本文没有在检索过程中直接使用大型LM,而是利用他们以小样本的方式为 IR 任务生成标记数据。
- 然后,本文在这些合成数据上微调检索模型,并使用模型对第一阶段检索系统的搜索结果进行重新排序。
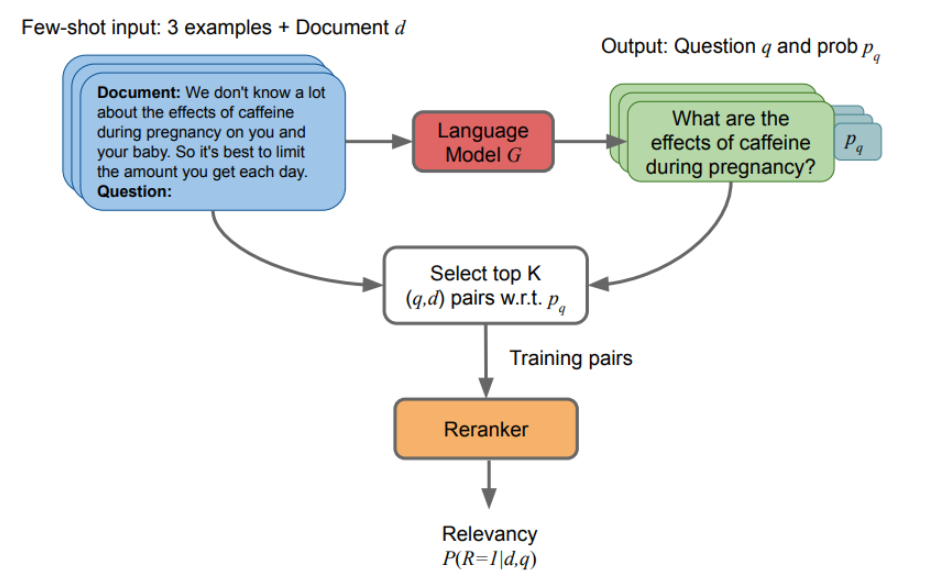
实验及结论
在数据集上表现SOTA。
思考与想法
使用了一种不同寻常的思路,值得借鉴。、