030
英文名称: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
中文名称:
论文地址: https://arxiv.org/abs/1810.04805
期刊/时间: NAACL 2019
前置知识
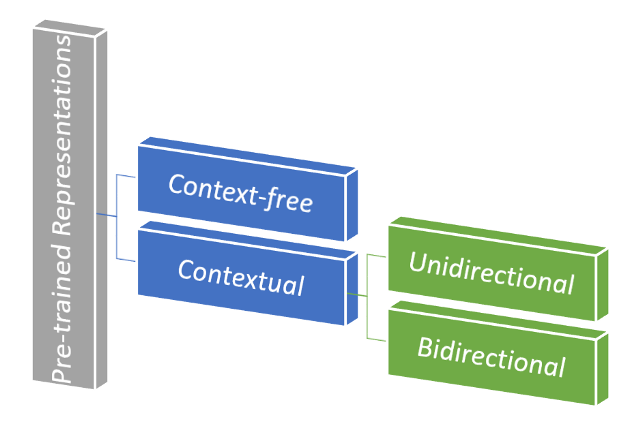
预训练的表示包含如下两种类型:
- 上下文无关(Context-free)。上下文无关模型为词汇表中的每个单词生成一个单词嵌入表示。例如,单词和bank中将具有相同的上下文无关向量表示。上下文无关模型的示例是word2vec、 GloVe等
- 上下文(Contextual)。上下文模型基于句子中的其他单词生成每个单词的表示。上下文表示进一步分类为:
- 单向:单向模型通过以句子中前面的单词为条件预测每个单词来有效地训练。
- 双向。然而,像 BERT 这样的双向上下文模型是通过根据句子中的前一个和下一个上下文词来预测每个词来训练的。因此,使其深度双向。
如何将这些表示应用于下游任务?
将预训练的语言表示应用于下游任务有两种现有策略:
- 基于特征:基于特征的方法使用特定于任务的架构,该架构由预先训练的表示作为附加特征组成。例如,ELMo 等。
- 微调:微调方法引入了最少的任务特定参数,并通过仅微调所有预训练参数来对下游任务进行训练。例如,生成式预训练变压器(OpenAI GPT)等
摘要
- 问题是什么?
- 我们要做什么?
- 大概怎么做的
- 实验效果
- 引入了一种新的语言表示模型BERT,它由transformer的双向编码器组成。不像最近的语言表示模型,BERT旨在通过联合条件所有层中的上下文,预训练无标记文本的深度双向表示。只需要一个额外的输出层,就可以对预先训练的BERT模型进行微调,为广泛的任务创建最先进的模型,例如问题回答和语言推断,而无需对特定于任务的体系结构进行大量修改。
- 在实验集上表现SOTA。
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 首先引出预训练模型。语言模型预训练已被证明对许多自然语言处理任务的改进是有效的。
- 这包括句子级别的任务,如自然语言推理和释义,目的是通过对句子进行整体分析来预测句子之间的关系,以及标记级任务,如命名实体识别和问题回答,其中模型需要在token级产生细粒度的输出
- 承。相关工作
- 将预先训练好的语言表示应用到下游任务有两种现有策略:基于特征(feature-based)和微调(fine-tuning)。
- 基于特征的方法:ELMo。使用特定任务的架构,将预训练的表示作为附加功能。
- 微调的方法:OpenAI GPT。引入最小的特定任务参数,并通过简单地微调所有预训练的参数对下游任务进行训练。
- 这两种方法在预训练过程中共享相同的目标函数,它们使用单向语言模型学习一般的语言表示。
- 转。相关工作的不足和转机
- 目前的技术限制了预训练表示的能力,标准语言模型的局限性是单向的,限制了在预训练期间架构的选择。
- 例如OpenAI GPT,使用了从左到右的体系结构,其中每个 token 只能在Transformer的自我注意层中关注前面的 token
- 这种限制对于句子级别的任务来说不是最优的,并且在将基于微调的方法应用于 token 级别的任务(如问题回答)时可能会非常harmful,因为在 token 级别的任务中,从两个方向整合上下文是至关重要的。
- MLM从输入中随机掩码一些token,其目的是基于内容预测掩码的原始词汇表id
- 与左右语言模型预训练不同,MLM目标允许表示融合左右上下文,这允许我们预训练深度双向Transformer。
- 合。本文工作
- BERT使用MLM支持预训练的深层双向表示
- 预训练的表示减少了很多繁重工程的特定任务架构,BERT是第一个基于表示的fine-tuning模型,在大量的sentence-level和token-level任务实现了SOTA的效果,优于很多特定任务的架构
- BERT在11个NLP任务表现SOTA
相关工作
主要介绍背景知识。
无监督基于特征的方法
ELMo
- 从不同的维度对传统的词嵌入研究进行了概括。利用从左到右和从右到左的语言模型中提取上下文敏感的特性。每个标记的上下文表示是从左到右和从右到左表示的串联。
无监督微调的方法
- 最近,生成上下文标记表示的句子或文档编码器已经从未标记的文本中进行预训练,并对有监督的下游任务进行微调
- 这种方法的优点:需要从头学习的参数很少
- OpenAI GPT在GLUE基准测试的许多句子级别任务上表现SOTA
从监督数据的迁移学习
有一些工作已经表明了基于大型数据集的监督任务的有效迁移。
方法
一般写作套路:
- 简要地重复问题
- 解决思路
- 必要的形式化定义
- 具体模型
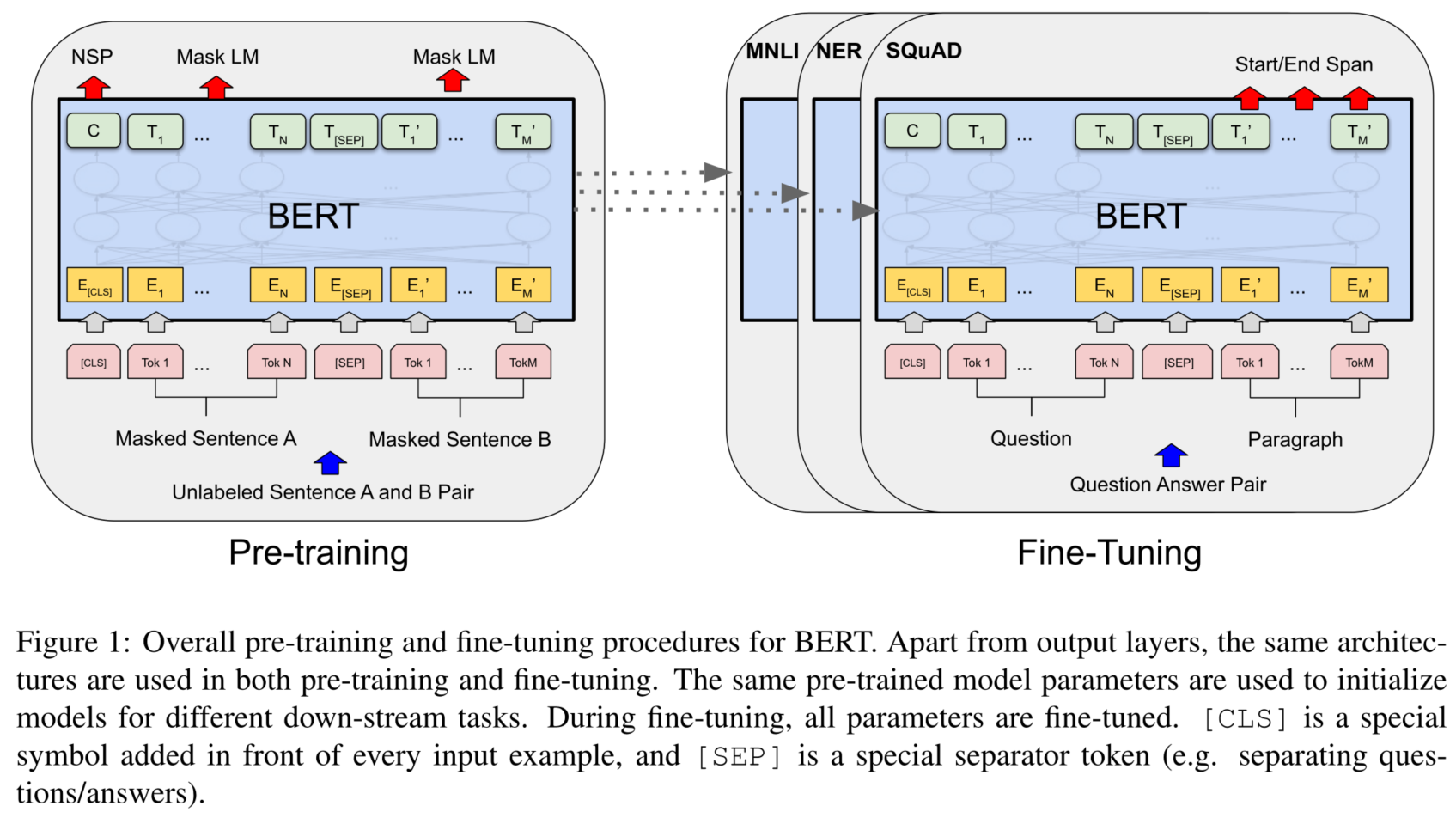
BERT包含两步:预训练和微调。
- 在预训练过程中,模型在不同的预训练任务上使用未标记的数据进行训练。
- 要进行微调,首先使用预先训练的参数初始化BERT模型,然后使用来自下游任务的标记数据微调所有参数。
- 每个下游任务都有单独的微调模型,即使它们是用相同的预训练参数初始化的。
为了训练深度双向表示,我们只需随机屏蔽一部分输入标记,然后预测那些被屏蔽的标记。在这种情况下,与掩码标记相对应的最终隐藏向量通过词汇表被输入到输出softmax中,就像在标准LM中一样
在训练语言模型时,定义预测目标是一个挑战。许多模型预测序列中的下一个单词(e.g. "The child came home from ___"),定向的方法固有地限制了上下文学习。为了克服这一挑战,BERT 使用了两种训练策略:
Masked LM (MLM)
在将单词序列输入 BERT 之前,每个序列中 15% 的单词被替换为 [MASK] 标记。然后,该模型尝试根据序列中其他非掩码单词提供的上下文来预测掩码单词的原始值。输出词的预测需要:
- 在编码器输出之上添加一个分类层。
- 将输出向量乘以嵌入矩阵,将它们转换为词汇维度。
- 用 softmax 计算词汇表中每个单词的概率。
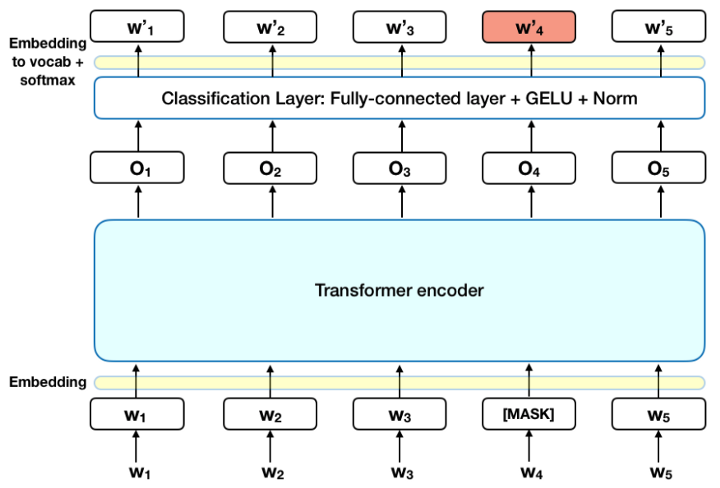
BERT 损失函数只考虑了对掩码值的预测,而忽略了对非掩码词的预测。因此,该模型的收敛速度比定向模型慢
Next Sentence Prediction (NSP)
在 BERT 训练过程中,模型接收成对的句子作为输入,并学习预测该对中的第二个句子是否是原始文档中的后续句子。在训练期间,50% 的输入是一对,其中第二个句子是原始文档中的后续句子,而在另外 50% 的输入中,从语料库中随机选择一个句子作为第二个句子。假设是随机句子将与第一句无联系。
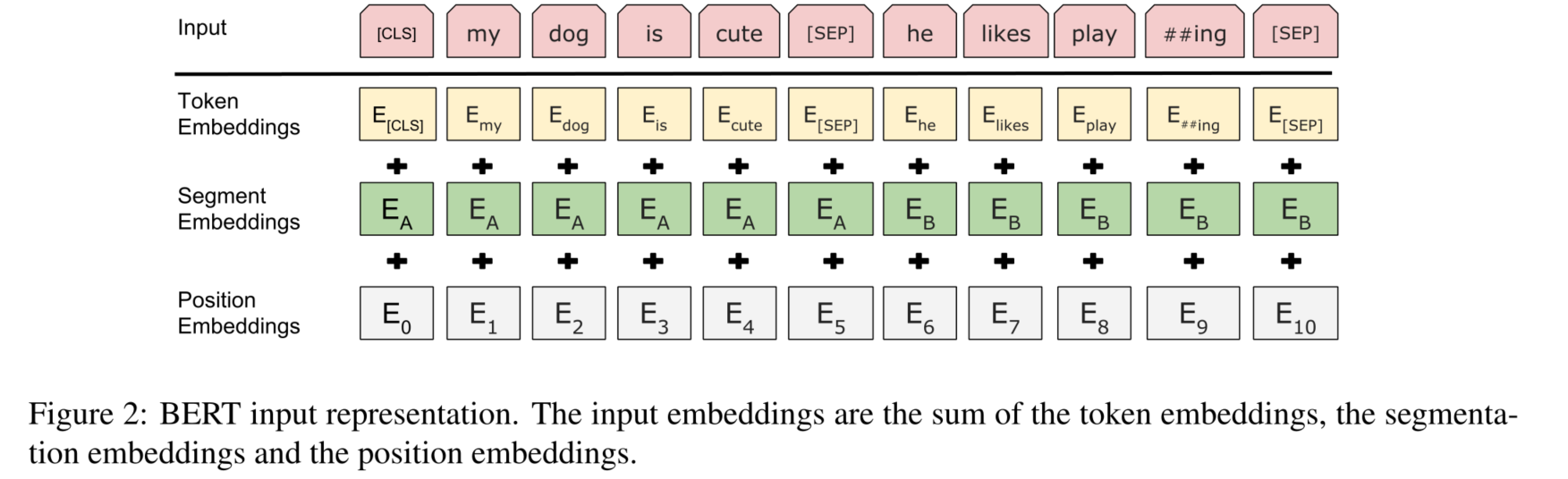
为了帮助模型在训练中区分两个句子,输入在进入模型之前按如下方式处理:
- 在第一句的开头插入一个 [CLS] 标记,在每个句子的结尾插入一个 [SEP] 标记。
- 将指示句子 A 或句子 B 的句子嵌入添加到每个标记中。句子嵌入在概念上类似于词汇表为 2 的标记嵌入。
- 位置嵌入被添加到每个标记以指示其在序列中的位置。
为了预测第二个句子是否确实与第一个句子相关,执行以下步骤:
- 整个输入序列通过 Transformer 模型。
- 使用简单的分类层(权重和偏差的学习矩阵)将 [CLS] 标记的输出转换为 2×1 形状的向量。
- 用 softmax 计算 IsNextSequence 的概率。
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 一起训练,目标是最小化这两种策略的组合损失函数。
Trick
在 BERT 中训练语言模型是通过预测输入中 15% 的标记来完成的,这些标记是随机挑选的。这些标记按如下方式进行预处理——80% 用"[MASK]"标记替换,10% 用随机词替换,10% 使用原始词。导致作者选择这种方法的直觉如下:
- 如果100%的比例使用 [MASK],模型不一定会为非屏蔽词生成良好的标记表示。非掩码标记仍用于上下文,但该模型针对预测掩码词进行了优化。
- 如果90%的比例使用 [MASK] 并另外10% 的比例使用随机词,这将告诉模型观察到的词永远不会正确。
- 如果90%的比例使用 [MASK] 并另外10% 的比例保持相同的单词,那么模型可以简单地复制非上下文嵌入。
对比 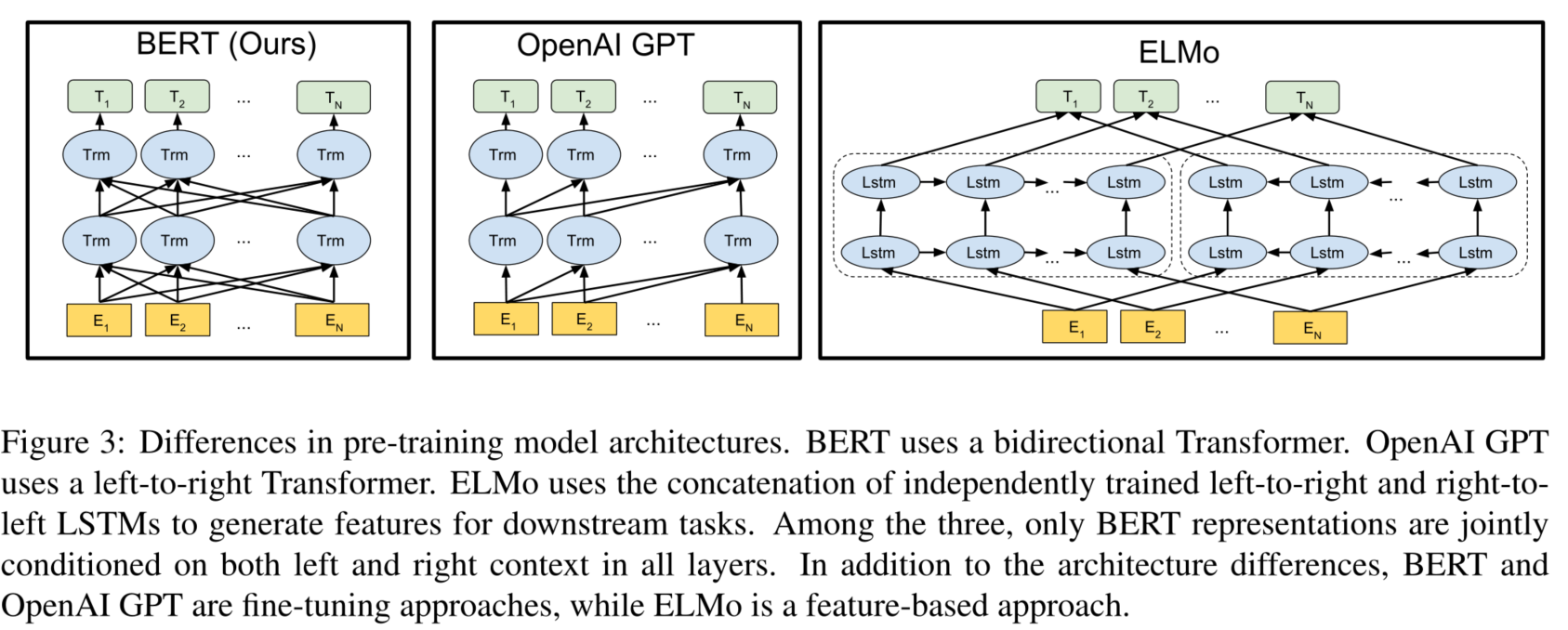
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连 接;就像单向RNN和双向RNN的区别,直觉上来讲效果会好一些。 对比ELMo,虽然都是 "双向",但目标函数其实是不同的。ELMo是分别以 $P\left(w_i \mid w_1, \ldots w_{i-1}\right)$ 和 $P\left(w_i \mid w_{i+1}, \ldots w_n\right)$ 作为目标函数,独立训练处两个representation然后拼接,而BERT则是 以 $P\left(w_i \mid w_1, \ldots, w_{i-1}, w_{i+1}, \ldots, w_n\right)$ 作为目标函数训练 $\mathrm{LM}$ 。
实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析
在11个NLP任务上表现SOTA。
讨论与总结
- 文中多次提到了双向(Bidirectional),什么是双向?与GPT的区别是什么?
- 首先在BERT的预训练模型中,预训练任务是一个mask LM ,通过随机的把句子中的单词替换成mask标签, 然后对单词进行预测。这里注意到,对于模型,输入的是一个被挖了空的句子, BERT使用Transformer-encoder来编码输入,encoder中的Self-attention机制在编码一个token的时候同时利用了其上下文的token,其中‘同时利用上下文'即为双向的体现,而并非想Bi-LSTM那样把句子倒序输入一遍。BERT并没有说将一个序列反向输入到网络中
- GPT同样使用Transformer作为基础架构,但使用 future mask 遮挡后面的信息,不让模型看到要预测的信息。
-
BERT 的输入和输出分别是什么? BERT 模型的主要输入是文本中各个字/词(或者称为 token)的原始词向量,该向量既可以随机初始化,也可以利用word2vec等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示。
模型输入除了字向量(英文中对应的是 Token Embeddings),还包含另外两个部分:
文本向量(英文中对应的是 Segment Embeddings):该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合 位置向量(英文中对应的是 Position Embeddings):由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:"我爱你"和"你爱我"),因此,BERT 模型对不同位置的字/词分别附加一个不同的向量以作区分 最后,BERT 模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的 BERT 模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将 playing 分割为 play 和##ing;此外,对于中文,目前作者未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
需要注意的是,上面只是简单介绍了单个句子输入 BERT 模型中的表示,实际上,在做 Next Sentence Prediction 任务时,在第一个句子的首部会加上一个[CLS] token,在两个句子中间以及最后一个句子的尾部会加上一个[SEP] token。
- BERT 的MASK方式的优缺点? 答:BERT的mask方式:在选择mask的15%的词当中,80%情况下使用mask掉这个词,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。
- 优点:1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
- 缺点:针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。
-
BERT分为哪两种任务,各自的作用是什么? BERT的常规工作流程分为两个阶段:预训练 pre-training 和微调 fine-tuning。其中预训练使用两个半监督任务:MLM模型和NSP模型,对于MLM模型而言,他主要的作用是预测被随机mask的输入token,对于NSP模型而言,主要的作用是用于,预测两个输入句子是否彼此相邻、是否为前后句关系。即用了MLM和NSP两种方法分别捕捉词语和句子级别的representation。相比预训练阶段,微调fine-tuning主要是针对下游应用,在fine-tuning时是通常需要一层或多层全连接层来添加到最终编码器层的顶部
-
BERT的三个Embedding为什么直接相加 答:Embedding的数学本质,就是以one hot为输入的单层全连接。 也就是说,世界上本没什么Embedding,有的只是one hot。
在这里想用一个简单的例子再尝试理解一下: 假设 token Embedding 矩阵维度是 [4,768];position Embedding 矩阵维度是 [3,768];segment Embedding 矩阵维度是 [2,768]。对于一个字,假设它的 token one-hot 是[1,0,0,0];它的 position one-hot 是[1,0,0];它的 segment one-hot 是[1,0]。那这个字最后的 word Embedding,就是上面三种 Embedding 的加和。 如此得到的 word Embedding,和concat后的特征:[1,0,0,0,1,0,0,1,0],再过维度为 [4+3+2,768] = [9, 768] 的全连接层,得到的向量其实就是一样的。
再换一个角度理解:
直接将三个one-hot 特征 concat 起来得到的 [1,0,0,0,1,0,0,1,0] 不再是one-hot了,但可以把它映射到三个one-hot 组成的特征空间,空间维度是 432=24 ,那在新的特征空间,这个字的one-hot就是[1,0,0,0,0…] (23个0)。
此时,Embedding 矩阵维度就是 [24,768],最后得到的 word Embedding 依然是和上面的等效,但是三个小 Embedding 矩阵的大小会远小于新特征空间对应的 Embedding 矩阵大小。
当然,在相同初始化方法前提下,两种方式得到的 word Embedding 可能方差会有差别,但是,BERT还有Layer Norm,会把 Embedding 结果统一到相同的分布。
BERT的三个Embedding相加,本质可以看作一个特征的融合,强大如 BERT 应该可以学到融合后特征的语义信息的。
- BERT中的NSP任务是否有必要? 答:在此后的研究(论文《Crosslingual language model pretraining》等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。这可能是由于Bert以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。
- BERT的优缺点分别是什么? 优点:
- 并行,解决长时依赖,双向特征表示,特征提取能力强,有效捕获上下文的全局信息,缓解梯度消失的问题等,BERT擅长解决NLU任务。
缺点:
- 生成任务表现不佳:预训练过程和生成过程的不一致,导致在生成任务上效果不佳;
- 采取独立性假设:没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计(不是密度估计);
- 输入噪声[MASK],造成预训练-精调两阶段之间的差异;
- 无法适用于文档级别的NLP任务,只适合于句子和段落级别的任务;
-
BERT深度双向的特点,深度体现在哪儿? 答:针对特征提取器,Transformer只用了self-attention,没有使用RNN、CNN,并且使用了残差连接有效防止了梯度消失
- 为什么BERT比ELMo效果好? 答:从网络结构以及最后的实验效果来看,BERT比ELMo效果好主要集中在以下几点原因:
- LSTM抽取特征的能力远弱于Transformer
- 即使是拼接双向特征,ELMo的特征融合能力仍然偏弱(没有具体实验验证,只是推测)
- BERT的训练数据以及模型参数均多于ELMo,这也是比较重要的一点
参考链接
- https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
- https://medium.com/analytics-vidhya/paper-summary-bert-pre-training-of-deep-bidirectional-transformers-for-language-understanding-861456fed1f9
- https://zhuanlan.zhihu.com/p/46652512
- https://ai.plainenglish.io/so-how-is-bert-different-ad43a42cab48