088
英文名称: ZEROGEN: Efficient Zero-shot Learning via Dataset Generation
中文名称: 基于数据集生成的高效零样本学习
论文地址: https://arxiv.org/abs/2202.07922
期刊/时间: 2022
代码地址: https://github.com/jiacheng-ye/ZeroGen
前置知识
摘要
- 问题是什么?
- 最近,由于大型预训练语言模型(PLM)的卓越生成能力,人们对数据集的生成越来越感兴趣。
- 本文要做什么?
- 在本文中,本文研究了一种灵活、高效的零样本学习方法–ZEROGEN。
- 大概怎么做的
- 给定一个零样本任务,本文首先以无监督的方式用PLMs从头生成一个数据集。然后,本文在合成的数据集的监督下训练一个微小的任务模型(如LSTM)。这种方法允许高效的推理,因为最终的任务模型与PLM(如GPT2-XL)相比,参数只少了几个数量级。除了无注释和高效之外,本文认为ZEROGEN还可以从无数据的模型诊断知识提炼和无参考文献的文本生成评估的角度提供有用的见解。
- 实验效果
- 在不同的NLP任务(即文本分类、问题回答和自然语言推理)上进行的实验和分析表明了ZEROGEN的有效性。
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 承。相关工作
- 转。相关工作的不足和转机
- 合。本文工作
虽然用语言模型生成训练数据对自然语言处理来说并不新鲜(Anaby-Tavor等人,2020;Puri等人,2020;Kumar等人,2020),但由于大规模预训练语言模型(PLM)的卓越生成能力,它最近获得了巨大的兴趣。
通过数据增强程序,以这种方式创建的训练实例在各种情况下被发现是有效的(Lee等人,2021;Schick和Schütze,2021;Wang等人,2021;Meng等人,2022,等等)。
在本文中,我们研究了这种方法的一个极端情况,即ZEROGEN。给定一个下游任务,我们首先使用一个强大的PLM从头开始生成其训练数据,其生成由精心设计的特定任务提示引导。其次,我们在综合训练数据的监督下训练一个微小的任务模型(TAM),它的参数比PLM少几个数量级。TAM可以有任何选择(例如,对数线或神经),允许高效推理和部署。机器生成的文本是连接PLM和最终任务模型的唯一媒介,在整个过程中不需要人工注释。
除了免注释和高效之外,我们对ZEROGEN感兴趣的原因还有以下几点。
- 首先,ZEROGEN可以被看作是知识蒸馏(KD;Hinton等人(2015))的一个变种,它提供了一些令人兴奋的新功能。与传统的KD不同,ZEROGEN在蒸馏过程中不需要任何人类注释。此外,ZEROGEN对学生模型的架构选择不做任何假设,因此我们可以方便地将任何特定任务的归纳偏见纳入学生模型的设计中。
- 第二,ZEROGEN可以作为文本生成的无参考评价方法(Guan和Huang,2020;Pillutla等人,2021):下游任务的表现由合成文本的质量主导,因此可以作为生成模型和算法的间接测量。
- 第三,ZEROGEN为提示工程(Petroni等人,2019;Brown等人,2020)(即PLM中的提示设计)提供了新的启示。由于人工提示反映了我们对特定任务的基本知识,这里一个有趣的问题是,我们可以在多大程度上将人类知识或指令纳入这些提示中。
我们在三个不同的NLP任务中评估了ZEROGEN,即文本分类、问题回答和自然语言推理,涉及六个数据集。我们的主要研究结果总结如下。
- 在ZEROGEN框架中,TAM的零拍性能明显超过了其PLM的同类产品(在知识提炼的背景下,PLM经常作为教师模型),参数数量仅为0.4%∼0.2%
- 在一些低资源环境中,用合成数据训练的TAM甚至超过了用人类注释训练的相同模型,以完全监督的方式
- 已知模型和算法生成的文本的质量很好地反映在下游任务的表现上,鼓励更多多样性的解码策略也会导致更大的噪音(
- 提示工程是具有挑战性的–更具指导性或自然语言风格的提示的表现在不同的任务中是不同的
总之,我们认为ZEROGEN是一个可行的、有前途的方法,可以在NLP中实现灵活、高效的零样本学习。作为一种无数据模型的知识提炼和无参考文献的文本评估方法,它也有很大的潜力。
相关工作
主要介绍背景知识。
方法
- 简要地重复问题
- 解决思路
- 必要的形式化定义
- 具体模型
实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析
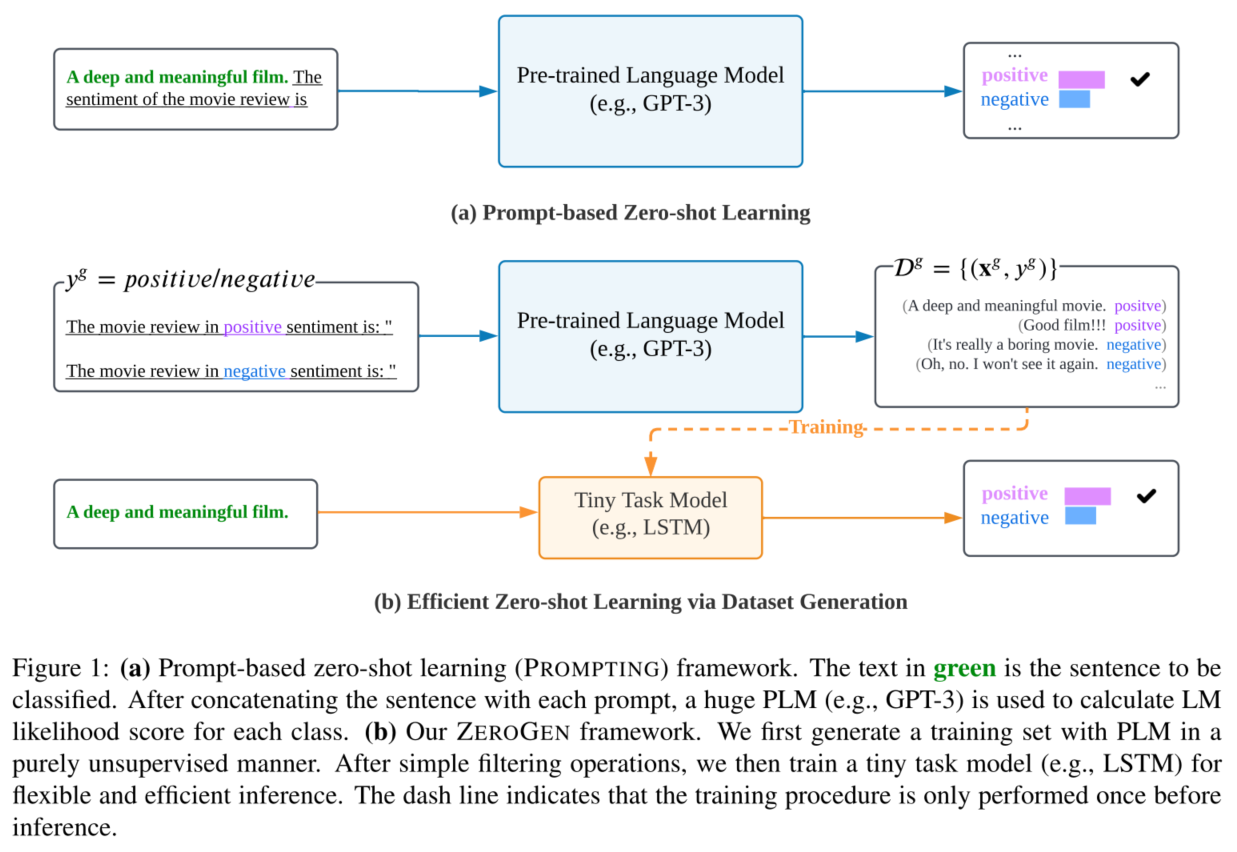
ZEROGEN框架分为三个阶段:
- 第一阶段的目标是利用PLM的生成能力来合成一个数据集,以解决下游的任务。通过精心设计的提示和强大的PLM,生成的数据集被认为包含了丰富的特定任务知识。
- 首先均匀采样类标签集合,然后使用PLM模型生成样本数据。
- 基于如上合成的伪数据集,然后本文训练一个微小的任务模型(TAM)来解决这个任务。TAM可以与任何特定任务的归纳偏见相结合,并且比PLM小一个数量级。
- 最后,本文使用训练好的模型对目标任务进行有效推理。在整个过程中,不涉及任何人为注释,因此评估设置是纯粹的零样本。
讨论与总结
在本文中,本文研究了一个通过PLMs生成数据集的极端实例,用于零样本学习。给定一个下游任务,本文首先用一个强大的PLMs在特定任务提示的指导下从头生成它的数据集。然后,用合成的数据集训练的微小任务模型被用来进行零样本推理。在没有任何人类注释的情况下,本文表明,一个单层LSTM可以超越其PLM对应的零样本性能(例如,GPT2-XL),甚至超过用人类注释训练的同一模型。
尽管已经证明了有效性,但基于零样本学习的数据集生成方面的研究仍处于早期阶段。本文讨论了本文在开发ZEROGEN时观察到的几个问题,并揭示了未来研究中的大量改进空间。
此外,本文在合成数据集中观察到了诸如NLI和QA等困难任务中的大量噪声实例,当采用更多的解码策略(如核子采样)时,这种情况会逐渐恶化。需要更好的可控解码方法来确保标签的正确性,同时保留数据集的多样性(Massarelli等人,2020)。此外,考虑到噪声数据集,从噪声标签中学习的方法可以被整合到微小任务模型的训练中(Song等人,2020)。
本文希望本文能够为进一步利用基于大型预训练语言模型的数据集生成的零样本学习提供贡献。