091
论文名称: Large Language Models are Zero-Shot Reasoners 作者: Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa 发表刊物/会议: NeurIPS 发表年份: 2022 论文地址: https://arxiv.org/abs/2205.11916 代码地址: https://github.com/kojima-takeshi188/zero_shot_cot
前置知识
摘要
- 问题是什么?
- 我们要做什么?
- 大概怎么做的
- 实验效果
- 预训练大型语言模型(LLMs)被广泛应用于自然语言处理(NLP)的许多子领域,通常被称为具有特定任务示例的优秀小样本学习者。值得注意的是,最近的一种通过逐步回答示例来引出复杂的多步推理的技术——思维链(CoT)提示,在算术和符号推理方面取得了最先进的表现,这些困难的系统-2任务不遵循LLMs的标准缩放定律。虽然这些成功通常归因于llm的小样本学习能力,但我们通过在每个答案之前添加"让我们一步一步地思考"来证明llm是出色的零样本推理者。实验结果表明,我们的零样本cot,使用相同的单个提示模板,在不同的基准推理任务上,包括算术(MultiArith, GSM8K, AQUA-RA T, SV AMP),符号推理(最后一个字母,硬币投掷)和其他逻辑推理任务(日期理解,跟踪shuffling对象),显著优于零样本LLM的表现,在没有任何手工制作的少样本示例中,例如,使用大规模InstructGPT模型(text-davinci002)将MultiArith的准确度从17.7%提高到78.7%,将GSM8K的准确度从10.4%提高到40.7%,以及使用另一个现成的大型模型540B参数PaLM进行类似的改进。这一单一提示在非常多样化的推理任务中的通用性,暗示了llm尚未开发和未被充分研究的基本零样本能力,这表明简单的提示可以提取高级的、多任务的广泛认知能力。我们希望我们的工作不仅可以作为具有挑战性的推理基准的最小最强零样本目标基线,而且还强调了在制作微调数据集或少数目标示例之前,仔细探索和分析隐藏在llm内部的大量零目标知识的重要性。
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 承。相关工作
- 转。相关工作的不足和转机
- 合。本文工作
扩大语言模型的规模是最近自然语言处理(NLP)革命的关键因素[V aswani等人,2017年,Devlin等人,2019年,Raffel等人,2020年,Brown等人,2020年,Thoppilan等人,2022年,Rae等人,2021年,Chowdhery等人,2022年]。大型语言模型(LLMs)的成功通常归因于(上下文中)少样本或零样本学习。它可以通过简单地将模型设置在一些示例(few-shot)或描述任务的指令(zero-shot)上来解决各种任务。调节语言模型的方法被称为"提示"[Liu et al, 2021b],手动设计提示[Schick and Schütze, 2021, Reynolds and McDonell, 2021]或自动设计提示[Gao et al, 2021, Shin et al, 2020]已成为NLP的热门话题。
与llm在直觉和单步系统-1 (Stanovich和West, 2000)任务中具有特定任务的少样本或零样本提示的出色表现相比[Liu等人,2021b],即使是100B或更多参数规模的语言模型在需要缓慢和多步推理的系统-2任务中也表现不佳[Rae等人,2021]。为了解决这一缺点,Wei等人[2022],Wang等人[2022]提出了思维链提示(CoT),它向LLMs提供逐步推理示例,而不是标准的问答示例(见图1-a)。

这样的思维链演示有助于模型生成推理路径,将复杂的推理分解为多个更简单的步骤。特别是CoT,推理性能更好地满足缩放定律,并随着语言模型的大小而上升。例如,当与540B参数PaLM模型结合时[Chowdhery等人,2022],在几个基准推理任务(例如GSM8K)中,思维链提示显著提高了标准少样本提示的性能(17.9%→58.1%)。
虽然CoT提示的成功[Wei等人,2022],以及许多其他特定于任务的提示工作[Gao等人,2021年,Schick和Schütze, 2021年,Liu等人,2021b],通常归因于LLMs的少次学习能力[Brown等人,2020年],但我们通过添加一个简单的提示来证明LLMs是不错的零次推理者,让我们一步一步地思考,以促进在回答每个问题之前的一步一步地思考(见图1)。我们的零概率cot成功地以零概率的方式生成了一条合理的推理路径,并在标准零概率方法失败的问题上得到了正确答案。重要的是,我们的zero-shot - cot是通用的和任务不确定的,不像以前大多数以示例(少数样本)或模板(零样本)形式出现的特定于任务的提示工程[Liu等人,2021b]:它可以促进各种推理任务的逐步回答,包括算术(MultiArith [Roy和Roth, 2015], GSM8K [Cobbe等人,2021],AQUA-RA T [Ling等人,2017],和SV AMP [Patel等人,2021]),符号推理(最后一个字母和硬币投掷),常识推理(CommonSenseQA [Talmor等人,2019]和策略QA [Geva等人,2021]),以及其他逻辑推理任务(日期理解和跟踪大平台上的shuffle对象[Srivastava等人,2015],2022]),无需修改每个任务的提示符。
我们对表2中的其他提示基线进行了实证评估。虽然我们的zero-shot - cot在精心制作和任务特定的逐步示例中表现不如小样本,但与零样本基线相比,zero-shot-cot取得了巨大的分数增长,例如,使用大规模InstructGPTMultiArith从17.7%提高到78.7%,GSM8K从10.4%提高到40.7%。我们还使用另一种现成的大型模型540B参数PaLM对zero -shot cot进行了评估,结果显示MultiArith和GSM8K有类似的改进。
重要的是,在我们的单一固定提示下,零样本llm与小样本CoT基线相比具有更好的缩放曲线。我们还表明,除了Few-shot-CoT需要人工工程的多步推理提示外,如果提示示例问题类型和任务问题类型不匹配,它们的性能会下降,这表明对每个任务提示设计具有高度敏感性。相比之下,在不同的推理任务中,这一单一提示的多功能性暗示了llm尚未开发和未被充分研究的零概率基本能力,例如更高级别的广义认知能力,如通用逻辑推理[Chollet, 2019]。虽然充满活力的llm领域始于优秀的少数样本学习者的前提[Brown et al, 2020],但我们希望我们的工作鼓励更多的研究,以揭示隐藏在这些模型中的高级和多任务零样本能力。
相关工作
主要介绍背景知识。
我们简要回顾了构成这项工作基础的两个核心初步概念:大型语言模型(LLMs)和提示的出现,以及用于多步推理的思维链(CoT)提示。
大语言模型和提示
语言模型(LM)是一种用于估计文本的概率分布的模型。最近,通过更大的模型规模(从几百万[Merity等人,2016]到数亿[Devlin等人,2019]到数千亿[Brown等人,2020]参数)和更大的数据(例如web文本语料库[Gao等人,2020])的缩放改进,使预训练的大型语言模型(LLMs)能够非常熟练地完成许多下游NLP任务。除了经典的"预训练和微调"范式[Liu等人,2021b]外,通过上下文学习,缩放到100B+参数的模型显示出有利于少次学习的属性[Brown等人,2020],在上下文学习中,人们可以使用被称为提示的文本或模板来强烈引导生成输出所需任务的答案,从而开启了"预训练和提示"的时代[Liu等人,2021a]。在实际工作中,我们将这种对少数任务示例具有显式条件反射的提示称为"少样本提示",将其他仅模板的提示称为"零样本提示"。
思维链提示
多步算术和逻辑推理基准测试特别挑战了大型语言模型的缩放定律[Rae等人,2021年]。思维链(CoT)提示[Wei等人,2022]是一个少次提示的实例,通过将少次示例中的答案修改为逐步回答,提出了一个简单的解决方案,并在这些困难的基准测试中实现了显著的性能提升,特别是在与PaLM等大型语言模型结合使用时[Chowdhery等人,2022]。图1的第一行显示了标准的少样本提示和(少样本)CoT提示。值得注意的是,少射学习被视为解决此类困难任务的既定条件,在原始工作中甚至没有报告零射基线性能[Wei et al, 2022]。为了区别于我们的方法,我们将Wei et al[2022]在这项工作中称为Few-shot-CoT。
方法
- 简要地重复问题
- 解决思路
- 必要的形式化定义
- 具体模型
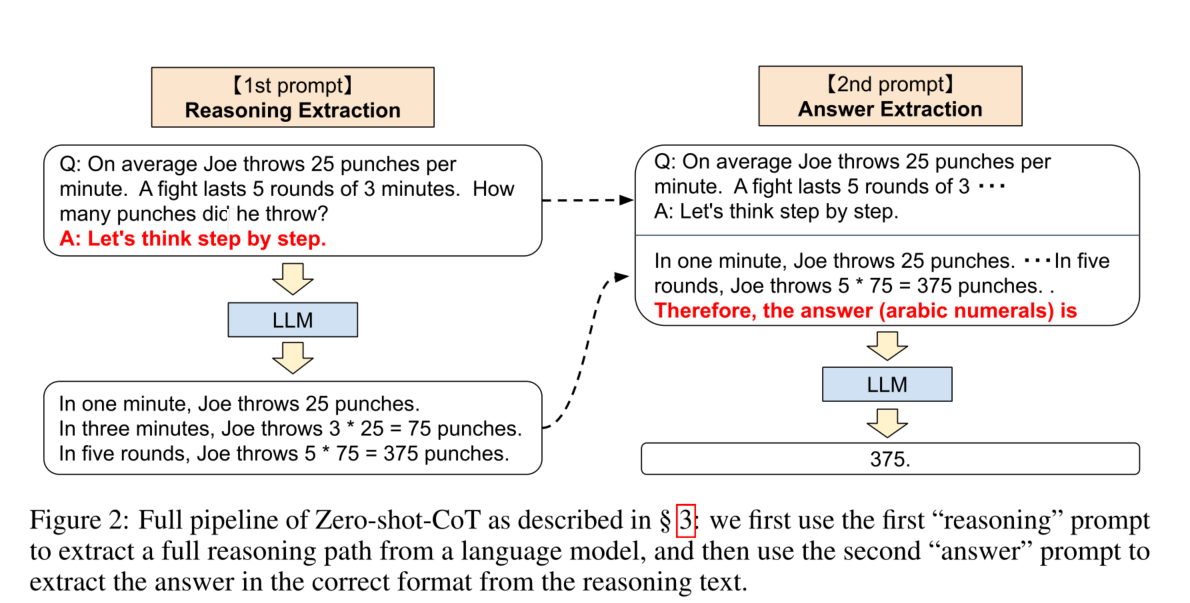
虽然Zero-shot-CoT在概念上很简单,但它使用了两次提示来提取推理和答案,如图2所示。与此相反,零点基线(参见图1的左下角)已经使用了"答案是"形式的提示,以正确的格式提取答案。
少样本提示,标准或CoT,通过显式地设计少样本示例答案以这种格式结束来避免需要这种答案提取提示
实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析