078
英文名称: Deep Neural Approaches to Relation Triplets Extraction: A Comprehensive Survey
中文名称:
论文地址:
期刊/时间:
介绍
关系提取有两种不同的研究范式:开放式信息抽取(Open IE)和有监督的关系抽取。
开放式信息抽取:从开放的关系及句子中提取关系三元组。使用基于规则的方法,从名词短语中提取实体,从句子中的动词短语中提取关系。这些模型将句子中的任何动词短语都提取为关系,因此产生了太多的无信息的三元组。一种关系可以用不同的表面形式在句子中表达,而开放IE将它们作为不同的关系处理,导致三元组的重复出现。
Open IE的问题可以用监督关系提取来解决。在监督关系提取中,我们考虑的是一个固定的关系集,因此不需要对提取的关系做任何规范化处理。这种方法需要大量的文本和关系三元组的平行语料库进行训练。
创建带注释的语料库是很困难的,而且很耗时,所以用这种方式创建的数据集规模相对较小。另一方面,可以利用远距离监督的方法来自动创建一个大型的训练语料库,但是这些数据集包含大量的噪声标签。这些远距离监督的数据集中的噪声标签会以消极的方式影响模型的性能。在过去的十年中,一些基于特征的模型和基于深度神经网络的模型被提出用于关系提取
任务描述
基于管道的关系提取方法将任务分为两个子任务:
- 实体识别
-
关系分类。
- 在第一个子任务中,所有的候选实体在一个句子中被识别。
- 在第二个子任务中,确定每个可能的候选实体的有序配对之间的关系–这种关系可能不存在(None)。
相比之下,联合提取方法是联合寻找实体和关系。联合模型只提取有效的关系三元组,它们不需要提取None三元组。关系三元组之间可能共享一个或两个实体,这种实体的重叠使这项任务具有挑战性。
综述范围
我们主要关注关于个人、组织和地点的关系三元组。
只关注英语语言的关系提取。
数据集标注的挑战
现有的知识库,如Freebase、Wikidata和DBpedia,都是人工建立的,这需要花费很多精力和时间。然而,这些知识库仍然有大量的缺失链接。另一方面,我们可以在自由文本中找到大量的关系三元组的证据。
手工创建这样一个语料库是一项艰巨的任务。一个可能的方法是确定文本中的实体,然后对于所有可能的实体对,从预先定义的关系集中确定关系,如果这个关系集中没有任何关系在这个文本中成立,则确定为None。识别文本中的实体相对比较容易,但是从一个集合中识别关系的难度会随着关系集的大小而增长。在大型关系集的情况下,标记无关系是比较困难的,因为标注者必须确保在文本中的两个实体之间没有一个关系集成立。
为了克服数据集的注释问题,Mintz等人(2009年);Riedel等人(2010年);Hoffmann等人(2011年)提出了远距离监督的想法,以自动获得文本-三元组映射,而不需要任何人工努力。在远程监督中,来自现有知识库的三元组被映射到自由文本语料库,如维基百科文章或新闻文章(如纽约时报)。远程监督的理念是,如果一个句子包含一个知识库中的三个实体,那么这个句子可以被认为是这个知识库三元组的来源。
另一方面,如果一个句子包含来自知识库的两个实体,而这两个实体在知识库中没有关系,那么这个句子就被认为是这两个实体之间的None三元组的来源。这些 "None"的样本是有用的,因为远程监督模型只考虑有限的正面关系集。这个集合之外的任何关系都被认为是None关系。这种方法可以给我们提供大量的三元组到文本的映射,这些映射可以用来为这个任务建立监督模型。这种远程监督的想法可以很容易地扩展到单文档或多文档的关系提取。
但是,远程监督的数据可能包含许多嘈杂的样本。有时,一个句子可能包含一个正三元组的两个实体,但该句子可能没有表达它们之间的任何关系。这类句子和实体对被认为是有噪声的正样本。另一组噪声样本来自于无关系的样本的创建方式。如果一个句子包含知识库中的两个实体,而这两个实体在知识库中没有任何关系,那么这个句子和实体对就被认为是无关系的样本。但是,知识库往往是不完整的,知识库中许多实体之间的有效关系是缺失的。因此,该句子有可能包含这两个实体之间的某些积极关系的信息,但由于该关系在知识库中并不存在,因此该句子和实体对被错误地认为是无关系的样本。这类句子和实体对被认为是有噪声的负面样本。
尽管存在嘈杂的样本,在远程监督数据上训练的关系提取模型已被证明在关系提取方面是成功的。这些模型可以通过从自由文本中自动寻找三元组来填补知识库中缺失的事实。它可以为完成一个现有的知识库节省大量的人工努力。
关系抽取数据集
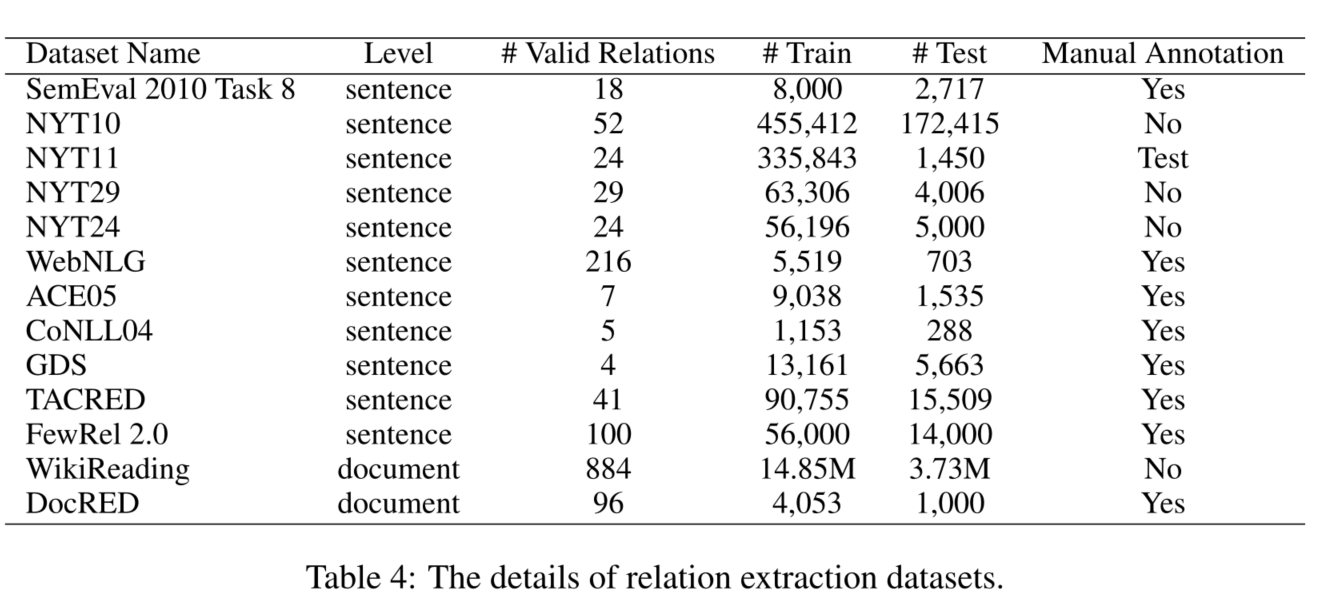
评估指标
在管道方法中,假设实体已经被识别,模型需要对实体对之间的关系或无关系(None)进行分类。有两种方法可以衡量模型的性能。
- sentence-lenvel
- 每一个带有实体对的句子都被认为是一个测试实例。
- bag-level
- 其中每个句子必须包含相同的实体对,被认为是一个测试实例。
在这两种方式中,模型都是在去除None标签后用精度、召回率和F1分数来评估的。一个置信度阈值被用来决定一个测试实例的关系是属于关系集R还是None。
精确度-召回曲线是评价远程监督测试数据集的一个流行的自动指标。精度-召回曲线下的面积(AUC)表示模型的性能指标。Precision@K是另一个用于评估此类测试数据集的指标,但它需要手工操作。
关系抽取方法
管道抽取方法
一个管道方法有两个步骤。
- 首先,使用一个命名实体识别器来识别文本中的命名实体。
- 其次,一个分类模型被用来寻找一对实体之间的关系
第一步确定的命名实体被映射到KB实体
基于特征的模型
他们使用了词汇特征,如两个实体之间的词序和它们的语音部分(POS)标签,表示哪个实体先出现的标志,实体1左边的k个标记和实体2右边的k个标记,句法特征,如两个实体之间的依赖路径,和命名实体类型。
基于CNN的神经模型
作为词嵌入的分布式词表征已经改变了自然语言处理任务(如IE)的处理方式。
Word2V ec(Mikolov等人,2013年)和GloVe(Pennington等人,2014年)是两套公开的大型词嵌入,被用于许多NLP任务。大多数基于神经网络的信息提取模型都将词的分布式表示作为其核心组成部分。词语的高维分布式表示可以编码关于词语的重要语义信息,这对于识别句子中存在的实体之间的关系非常有帮助。最初,神经模型也遵循管道方法来解决这一任务。
基于Attention的神经模型
Shen和Huang(2016)提出了一个卷积神经网络模型和注意力网络的组合。首先,用最大集合的卷积操作来提取句子的全局特征。接下来,在两个实体的基础上分别对句子中的单词进行关注。使用词级注意力模型进行单实例句子级关系提取。一个实体的最后一个标记的单词嵌入与每个单词的嵌入相连接。这个串联的表征被传递到一个具有tanh激活的前馈层,然后是另一个具有softmax的前馈层,以获得该实体的每个词的标量注意力得分。词的嵌入根据注意力分数进行平均,以得到注意力特征向量。两个实体的全局特征向量和两个关注特征向量被连接起来,并传递给具有softmax的前馈层以确定关系
基于依存关系的神经模型
以前的一些工作将句子的依存结构信息纳入他们的神经模型进行关系提取。Xu等人(2015)使用长短期记忆网络(LSTM)(Hochreiter和Schmidhuber,1997)沿着两个实体之间的最短依赖路径(SDP)来寻找它们之间的关系。沿着SDP的每个标记都用四个嵌入来表示–预训练的词向量、POS标签嵌入、标记与其在SDP中的子项之间的依赖关系嵌入,以及其WordNet(Fellbaum,2000)超词嵌入。他们将SDP分为两个子路径:(i)从实体1到共同祖先节点的左边SDP(ii)从实体2到共同祖先节点的右边SDP。这个共同祖先节点是依赖树中两个实体之间的最低共同祖先。沿着左边SDP和右边SDP的标记向量被分别传递到LSTM层。一个池化层被应用于隐藏的向量,从左SDP和右SDP中提取特征向量。这两个向量被连接起来,并传递给一个分类器以找到关系。
基于Graph的神经模型
基于图的模型在许多NLP任务中很受欢迎,因为它们在非线性结构上工作。Quirk和Poon(2017)提出了一个用于跨句子关系提取的基于图的模型。他们从句子中建立了一个图,每个词都被认为是图中的一个节点。边缘是根据词的相邻关系、依存树关系和话语关系来创建的。他们从图中提取所有的路径,从实体1开始到实体2。每条路径都由词汇标记、标记的词法、POS标记等特征表示。他们使用所有的路径特征来寻找两个实体之间的关系。
基于上下文嵌入的神经模型
基于上下文嵌入的模型能用于关系抽取。
- ELMo
- BERT
- SpanBERT
这些语言模型是在大型语料库上训练出来的,可以在其向量表示中捕捉到单词的上下文含义。所有被提出用于关系提取的神经模型在其单词嵌入层中使用单词表征,如Word2Vec或GloVe。在关系提取模型的嵌入层中可以添加上下文嵌入,以进一步提高其性能。
远程监督的噪声缓解
远距离监督数据中存在的噪声样本对模型的性能产生了不利影响。研究人员在他们的模型中使用了不同的技术来减轻噪音样本的影响,使其更加稳健。
多实例关系提取是缓解噪声的流行方法之一。对于每个实体对,他们使用包含这两个实体的所有句子来寻找它们之间的关系。他们的目标是利用这种多实例设置来减少噪声样本的影响。他们使用不同类型的句子选择机制来重视包含特定关系关键词的句子,而忽略了嘈杂的句子。
零样本和小样本关系抽取
远距离监督数据集涵盖了知识库中的一小部分关系。现有的知识库如Freebase、Wikidata和DBpedia包含成千上万的关系。由于知识库和文本中实体的表面形式不匹配,远距离监督无法为知识库中的大多数关系找到足够的训练样本。这意味着远距离监督模型不能填补属于这些未发现的关系的缺失链接。Zero-shot 或 few-shot 关系提取可以解决这个问题。这些模型可以在一组关系上进行训练,并可用于推断另一组关系。
数据集:
- FewRel 2.0
联合抽取方法
通过共享参数和共同优化来拉近实体识别和关系识别任务。他们首先识别一个句子中的所有实体,然后找到所有已识别实体对之间的关系。尽管它们在同一网络中识别了实体和关系,但它们仍然先识别实体,然后再确定同一网络中所有可能的配对关系。所以这些模型错过了句子中存在的关系三联体之间的互动。这些方法在某种程度上类似于管道方法。
当前最先进的技术和趋势
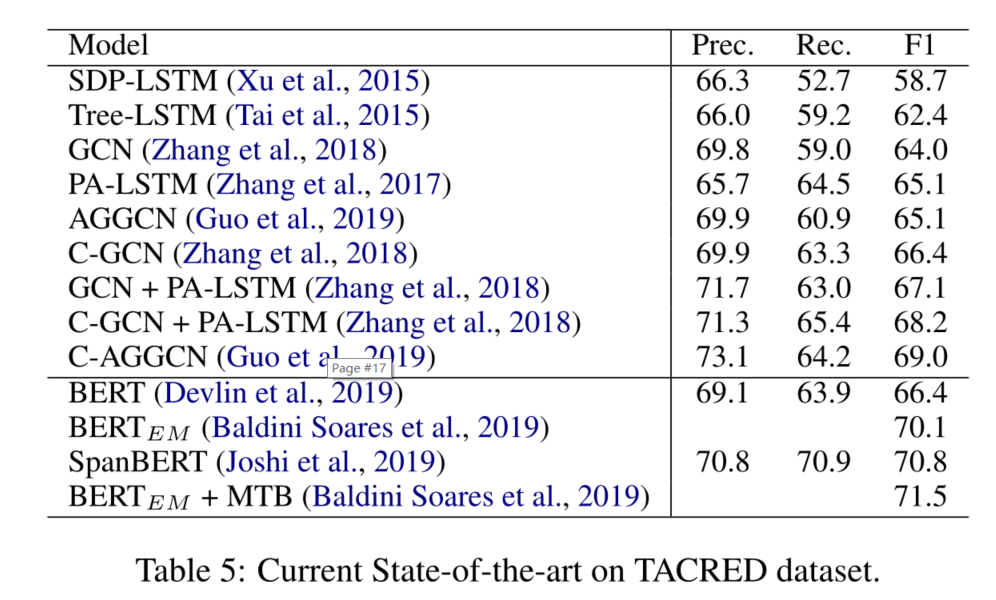
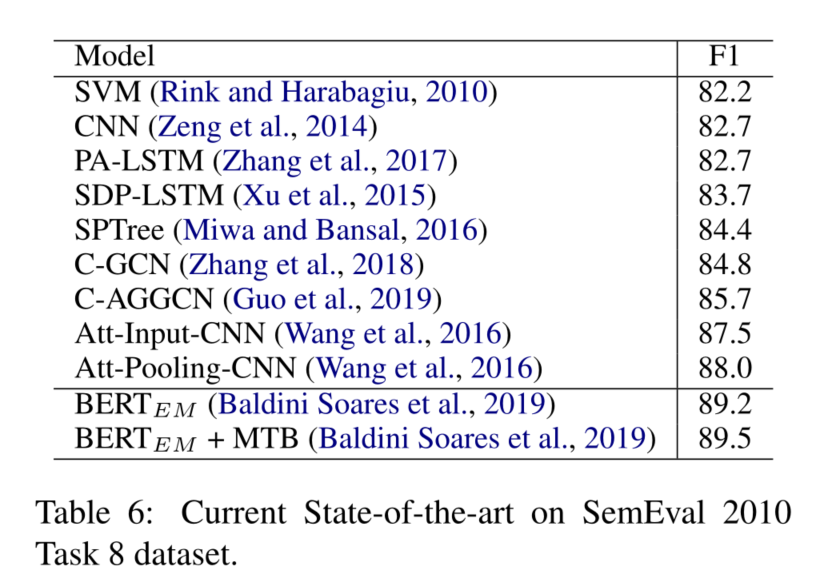
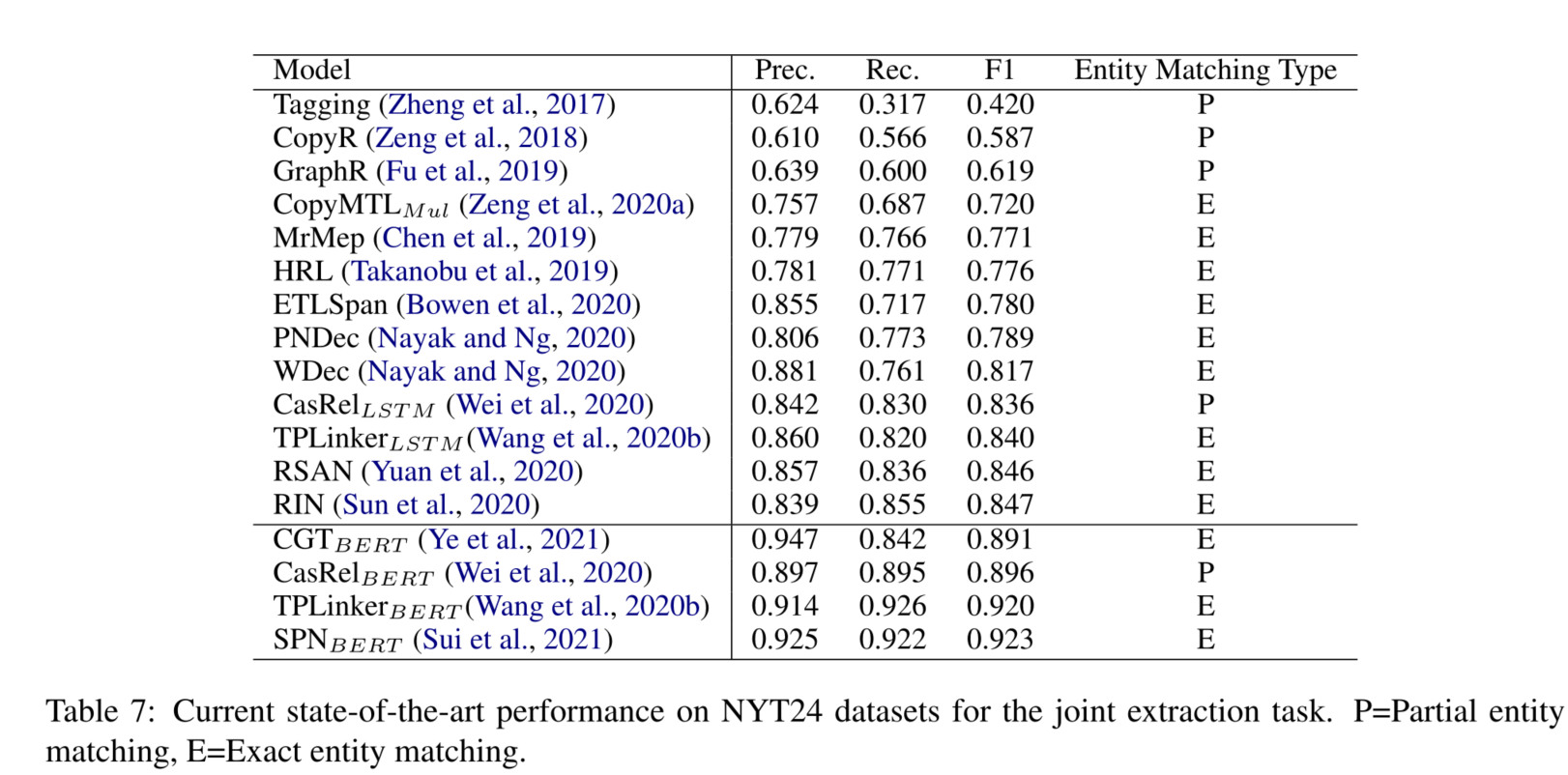
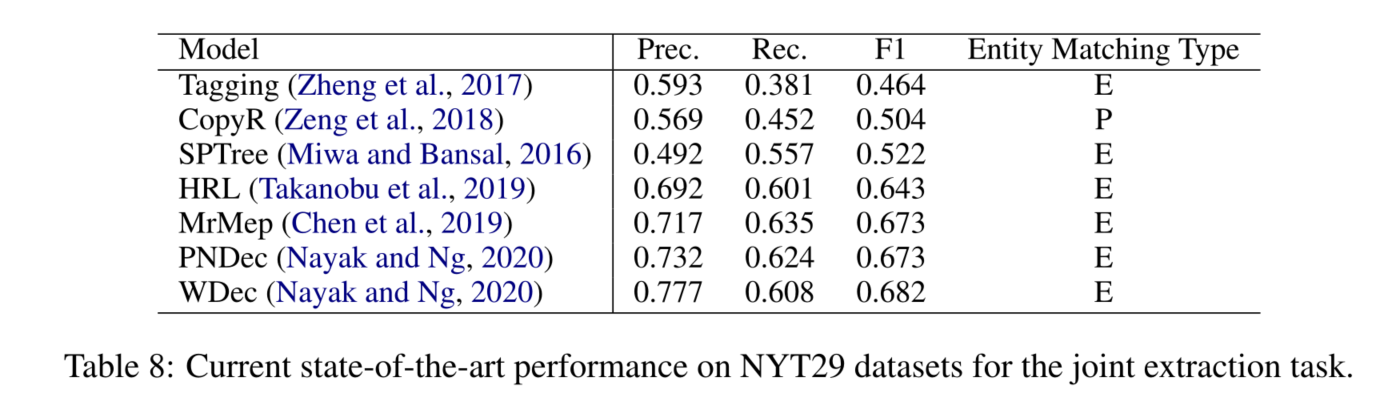
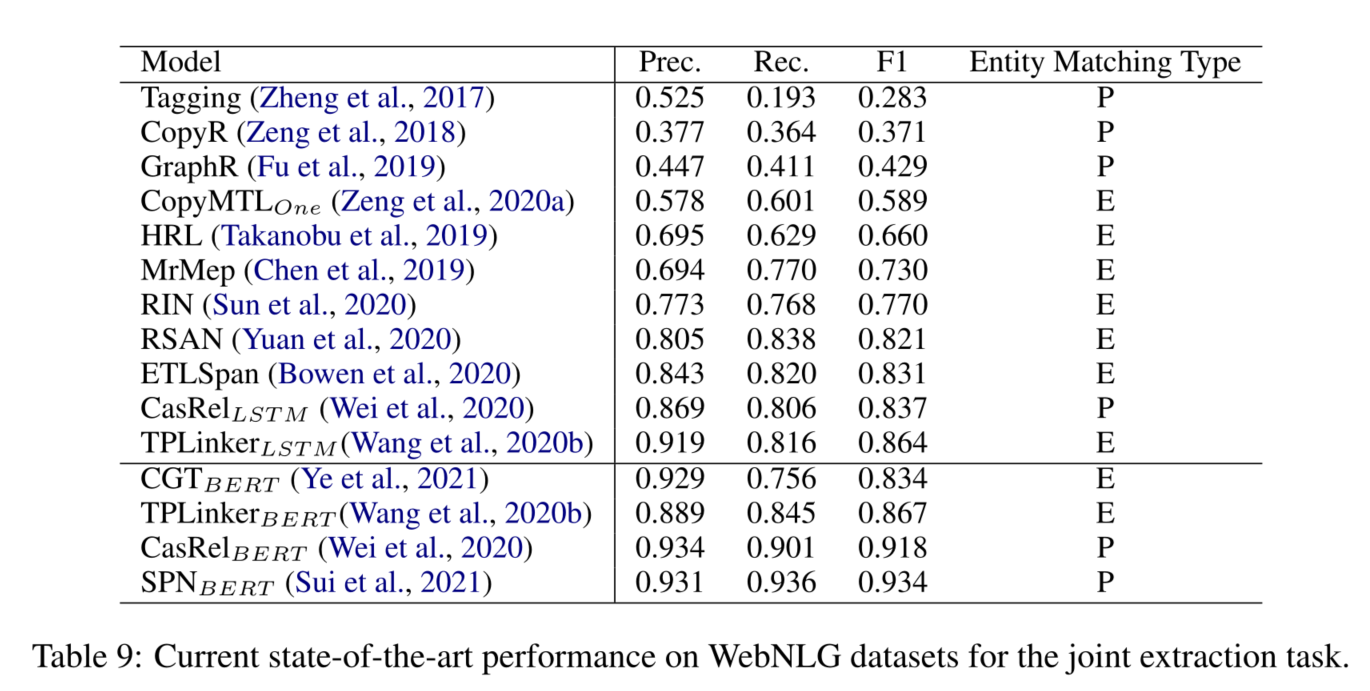
我们看到,大多数的研究集中在基于管道的句子级关系提取方法上。
我们还看到,在已发表的文章中,使用远距离监督的数据集和注释的数据集进行实验是均匀分布
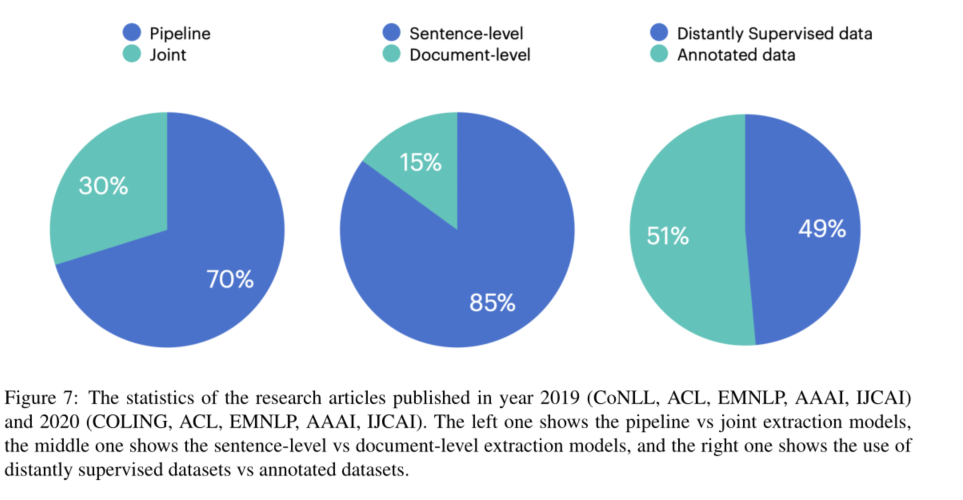
未来研究方向
在管道方法中,由于我们需要找到所有实体对之间的关系,可能会有非常多的None实例。这种None类的识别很有挑战性,因为它不是一个单一的关系,而是正向关系集之外的任何关系。对 "None"关系的错误检测降低了模型的精度,并会给知识库增加许多错误的三元组。为了建立一个更干净的知识库,模型必须在正确分类正面关系的同时,很好地检测None关系。
关于联合提取的方法,研究人员在训练或测试中不包括带有零三元组的句子。NYT24和NYT29数据集是在去除原始NYT11和NYT10数据集中的零三元组的句子后创建的。NYT11和NYT10数据集包含许多没有任何关系三元组的句子。因此,在未来,检测没有关系三元组的句子必须在联合提取方法中处理。
目前的关系提取模型处理的关系非常少,而现有的知识库有成千上万的关系。在未来,我们应该更多地关注文档级的关系提取,或者可能是跨文档的关系提取。按照Nayak(2020)提出的想法,我们应该把关系提取的任务扩展到N-hop,以涵盖更多的知识库中的关系。
然而,扩展任务可能并不容易,因为在链条中加入更多的文件可能会使数据更加嘈杂。我们需要探索小样本或零样本关系提取,以涵盖我们无法通过远距离监督获得足够训练数据的关系。