004
英文名称:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
中文名称:基于联合学习对齐和翻译的神经机器翻译
论文地址: http://arxiv.org/abs/1409.0473
期刊/时间:ICLR 2015
相关工作
最早将注意力机制引入机器翻译的论文
机器翻译: 利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。
发展历史:
- 基于规则的机器翻译,按照翻译方式分为:
- 直接基于词的翻译
- 结构转换的翻译
- 中间语的翻译
- 基于统计的机器翻译
- 通过对大量的平行语料进行统计分析,构建统计翻译模型,进而使用此模型进行翻译
- 核心问题:为翻译过程建立概率模型
- 大致流程:输入->基于词的翻译->查询语料库->统计概率->输出
- 基于神经网络的机器翻译
- 通过学习大量成对的语料让神经网络自己学习语言的特征,找到输入与输出之间的关系
- 核心思想:端到端(End-to-End)。Encoder-Decoder,Sequence2Sequence
基于神经网络的机器翻译 基本思想:利用神经网络实现自然语言的映射 核心思想:条件概率建模
\(P\left(y_n \mid x, y_{<n} ; \theta\right)\) $y_n$ 当前目标语言词 $x$ 源语言句子 $y_{<n}$ 已经生成的目标语言句子
如何对条件概率进行建模
\(\begin{aligned} & P\left(\mathbf{y}_n \mid \mathbf{x}, \mathbf{y}_{<n} ; \boldsymbol{\theta}\right) \\ =& \frac{\left.\exp ( \varphi\left(\mathbf{y}_n, \mathbf{x}, \mathbf{y}_{\leq n}, \boldsymbol{\theta}\right)\right)}{\sum_{y \in \mathcal{Y}} \exp \left(\varphi\left(y, \mathbf{x}, \mathbf{y}_{<n}, \boldsymbol{\theta}\right)\right)} \\ =& \frac{\exp \left(\varphi\left(\mathbf{v}_{\mathbf{y}_n}, \mathbf{c}_s, \mathbf{c}_t, \boldsymbol{\theta}\right)\right)}{\sum_{y \in \mathcal{Y}} \exp \left(\varphi\left(\mathbf{v}_y, \mathbf{c}_s, \mathbf{c}_t, \boldsymbol{\theta}\right)\right)} \end{aligned}\) $\mathbf{v}_y$ 目标语言词向量
$\mathcal{Y}$ 目标语言词汇 $\mathbf{c}_S$ 源语言上下文向量
$\mathbf{c}_t$ 目标语言上下文向量
从概率的角度来看,翻译相当于找到一个目标句y,在给定源句x的情况下,使y的条件概率最大化。
- 大多数提出的翻译模型都是encoder-decoders结构的
- Encoder神经网络读取和encode源句子,编程一个固定长度的vector
- Decoder从编码的vector中输出翻译结果
- Encoder和Decoder联合训练,最大限度地提高正确翻译的概率
RNN:
- 对于RNN的激活函数,使用门控隐藏单元(gated hidden unit),用于替换传统的简单单元,如tanh
机器翻译的核心在于不同语言信息之间的等价转换。传统使用离散表示。深度学习使用连续的表示,用数字进行信息的传递。
问题及挑战
编码器-解码器方法的一个潜在问题是神经网络需要能够将源句子的所有必要信息压缩到一个固定长度的向量中。使得神经网络难以处理长句子,随着输入句子长度的增加,编码器-解码器的性能会逐渐下降。
编码器-解码器框架优缺点:
- 优点:利用长短时记忆处理长距离依赖
- 缺点:任意长度的句子都编码为固定维度的向量
RNNenc与RNNsearch对比
RNNenc:
- 将整个输入语句编码成一个固定向量的长度
- 使用单向循环神经网络RNN
存在问题:
- 必须记住整个句子序列的语义信息
- 把无论长度多长的句子都编码成固定向量,这样限制了翻译过程中长句子的表示
- 与人类翻译时的习惯不同,人们不会再生成目标语言翻译时关注源语言句子的每一个单词
RNNsearch:
- 将输入的句子编码成变长向量序列
- 在解码器翻译时,自适应地选择这些向量的子集
- 使用双向循环神经网络Bi-RNN
贡献
- 提出的模型改善在较长的句子中更为明显,但在任何长度的句子中都可以观察到
- 在英法翻译任务中,该方法通过单一模型实现了与传统基于短语的翻译系统相当或接近的翻译性能。
- 定性分析表明,该模型在源句和对应目标句之间找到了一种语言上似是而非的(软)对齐。在数据集上,两种语言的位置关系虽然不同,但同样完成了翻译
方法
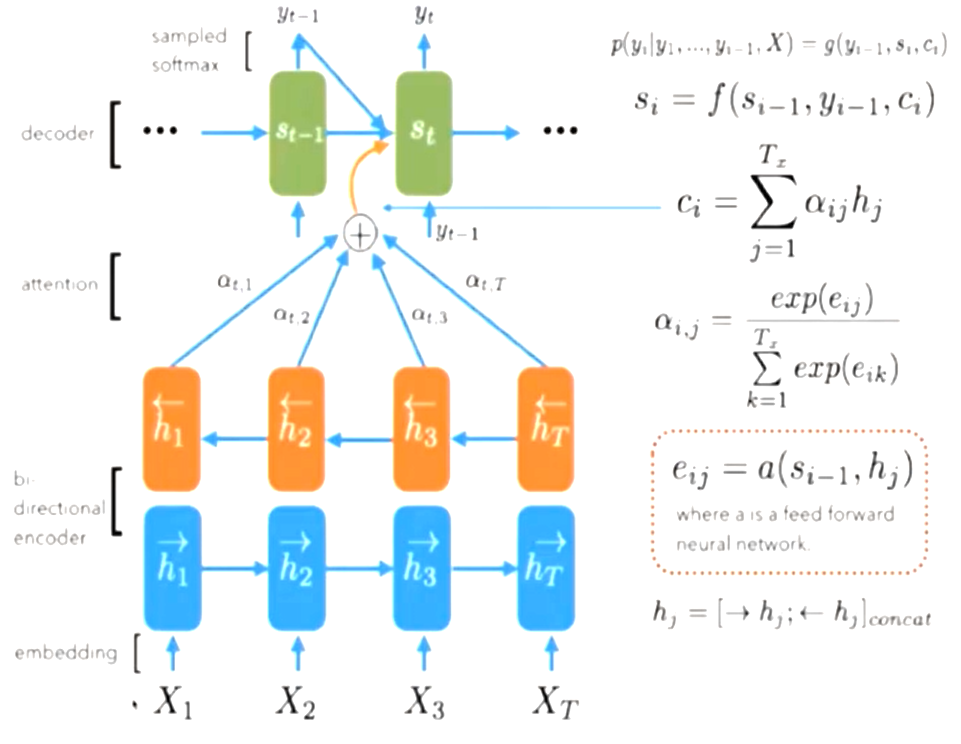
针对问题1,提出了一种扩展的encoder-decoder模型来联合学习对齐和翻译。每当提出的模型在翻译中生成一个单词时,它在源句中搜索最相关信息关注的位置。然后,该模型根据与这些源位置相关的上下文向量和之前生成的所有目标词预测一个目标词。它将输入语句编码为向量序列,并在decoder时自适应地选择这些向量的子集。这使得神经翻译模型不必将源句的所有信息(无论其长度)压缩到一个固定长度的向量中。实验证明模型能够更好地处理长句子。
RNNsearch包括一个双向RNN作为编码器和一个解码器,在解码翻译过程中模拟搜索源句。
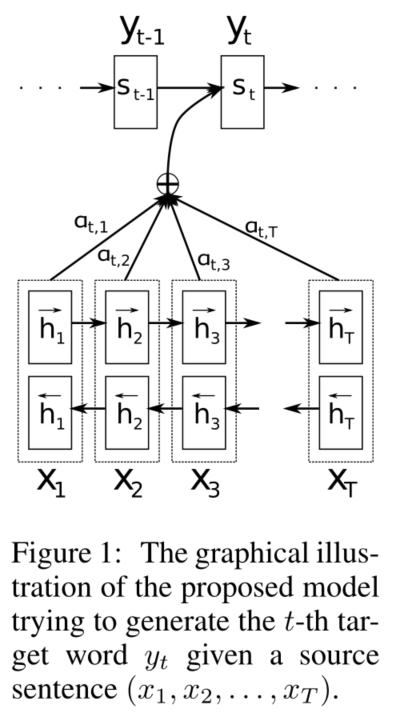
使用BiRNN结构使得每个单词的annotation不仅总结前面的词,而且总结后面的单词。
解码器决定源句需要注意的部分。通过让解码器有一个注意机制,我们减轻了编码器必须将源句子中的所有信息编码到一个固定长度的向量的负担。使用这种新方法,信息可以在annotations序列中传播,解码器可以相应地有选择地检索这些annotations。
与传统机器翻译不同,对齐不被认为是一个潜在变量,相反,对齐模型直接计算软对齐,这允许成本函数的梯度反向传播。 该梯度可以用来联合训练对齐模型和整个翻译模型。
实验
数据集: ACL WMT '14
评估标准
Bleu:一种文本评估算法,用来评估机器翻译与专业人工翻译之间的对应关系。
核心思想:机器翻译越接近专业人工翻译,质量就越好。
- RNNsearch比传统的encoder-decoder模型表现更好,在长句子上更具有鲁棒性。
- 翻译性能与现有的基于短语的统计机器翻译能力相当。
讨论与总结
注意力机制能够提升多少性能?
答:Luong等人证明使用不同注意力机制计算会导致不同的结果。
双向循环神经网络能够提升多少性能?
答:Luong等人证明使用单向LSTM和使用计算注意力分数具有同样的效果。
有其他注意力分数计算方法吗?
答:Luong等人证明提出其他的注意力分数计算方法。
问题的更多细节可参考文章"Effectivate Approaches to Attention based Neural Machine Translation(Luong,2015)"