003
主要是基于word2vec方法的一种改进。基于word2vec提出了两个计算句子相似度的方法,一个是PV-DM,对应于word2vec中的CBOW算法,另一个是PV-DBOW,对应于word2vec中的Skip-gram算法。
英文名称: Distributed representations of sentences and docments
中文名称: 句子和文档的分布式表示
论文地址: http://arxiv.org/abs/1405.4053
代码地址: PVDM、 NLP_Paper_Projects
痛点及现状
- BOW存在数据稀疏性和高维性的问题,有两个主要缺点:
- 丢失了词的顺序
- 忽略了词的语义,或者单词之间的距离
之前学习向量表示的方法存在缺陷:
- 词向量的加权平均,它以与标准词袋模型相同的方式丢失词序。
- 使用解析树组合词向量,已被证明仅适用于句子,因为它依赖于解析。
方法与创新
- 虽然段落向量在段落之间是唯一的,但词向量是共享的。在预测时,通过固定词向量并训练新的段落向量直到收敛来推断段落向量。
- 与之前的一些方法不同,它是通用的并且适用于任何长度的文本:句子、段落和文档。它不需要对词权函数进行特定于任务的调整,也不依赖于解析树。
- 与word2vec不同,将paragraph和word平均或结合来预测下个词
- Paragraph向量解决了词袋模型的缺点。
- 继承了word2vec的重要特性:词的语义
- 将词的顺序考虑在内
- 之前的方法受限于句子,我们的方法不需要解析,可以生成包含很多句子的长文档表示,相比更加通用。
模型架构
PV-DM
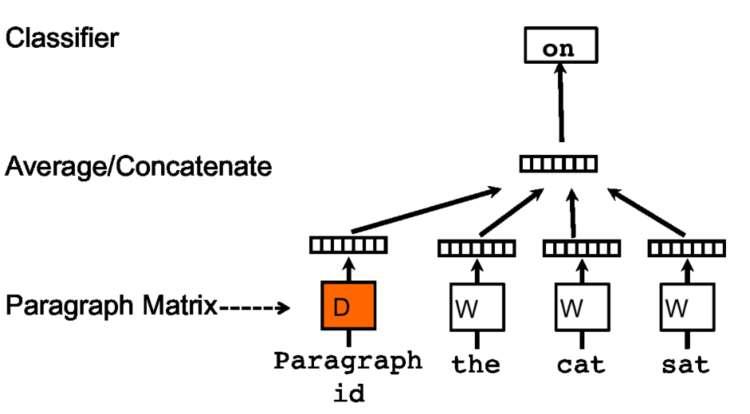
上下文信息是按照固定长度在段落上根据滑动窗口不断采样,段落向量会被该段落产生的所有上下文窗口所共同拥有,但是不跨越段落,也就是说,不同段落的段落向量是不同的。但是不同段落的词向量是相同的。
PV-DBOW
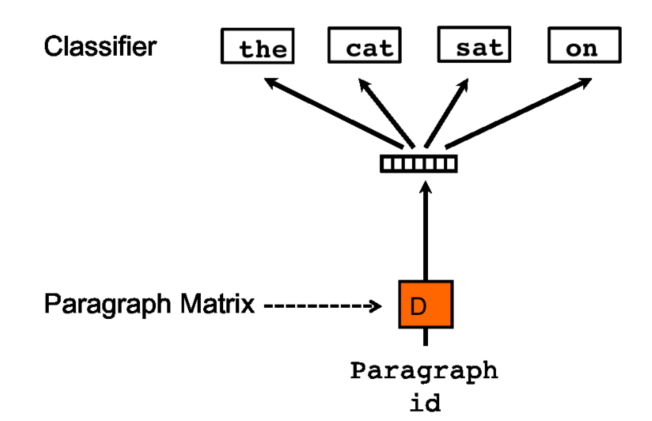
PV-DBOW方法是在输入中忽略上下文单词,但是在输出中强制模型对段落中随机采样的单词进行预测。事实上,SGD的每一次迭代中,我们都会随机选择一个文本窗口,然后从这个文本窗口中随机采样一个单词并且构建一个基于段落向量的分类任务。 为了计算简单,仅仅需要存储Softmax的权重参数,而不是之前模型的词向量和Softmax的权重参数。
实验及结论
分别从两方面进行实验验证:
- Sentiment Analysis
- 在Stanford sentiment treebank数据集和IMDB上表现SOTA
- Information Retrieval
- 在新建数据集上表现SOTA