AlexNet
选自论文ImageNet classification with deep convolutional neural networks,重点学习实验部分。
摘要

关键技术:Dropout和Relu
Relu优点:
- 可以使网络训练更快。相比于tanh,sigmod,导数更好求
- 增加网络的非线性。加入到神经网络中,可以是网络拟合非线性的映射。
- 防止梯度消失。当数值过大或过小时,sigmoid,tanh导数接近0,会导致反向传播时候梯度消失的问题,relu为非饱和激活函数,不存在此问题。
- 使网络更具有稀疏性。relu可以使一些神经元输出为0,因此可以增加网络的稀疏性。
Dropout:
作用:随机将一定比例的神经元置为0。对于一个有n个节点的神经网络,有了dropout后,可以看作是\(2^n\)个模型的集合,相当于机器学习中的ensemble
SoftMax作用:
将神经网络的输出变为概率分布
- 数据之和为1
- 负数变为正数
卷积
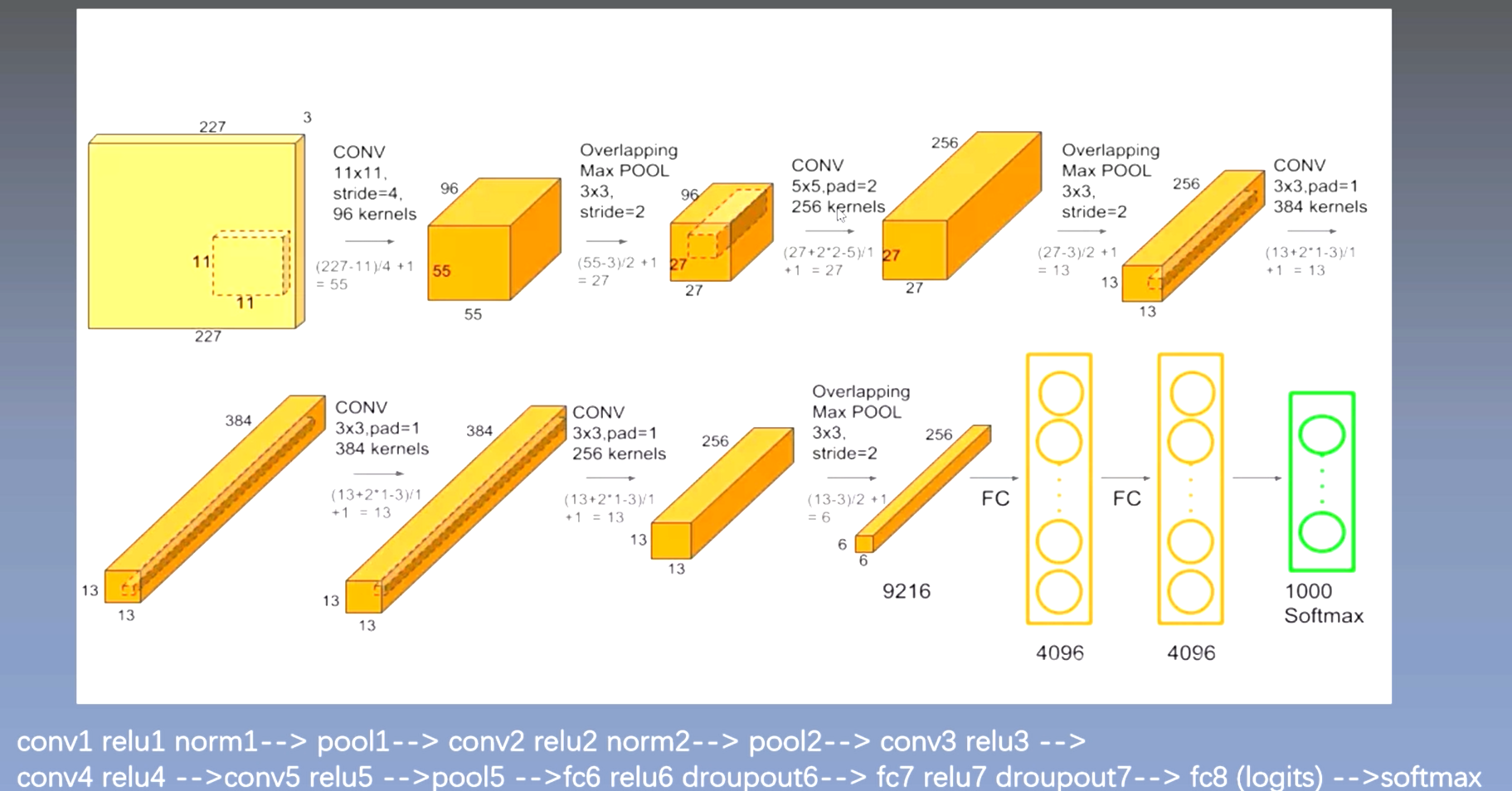
卷积的一些细节:
- 输入特征map的通道数是多少,卷积核的通道就是多少,这个数值一般情况是相等的;
- 有多少个卷积核就有多少个输出特征map。
网络参数及连接计算:
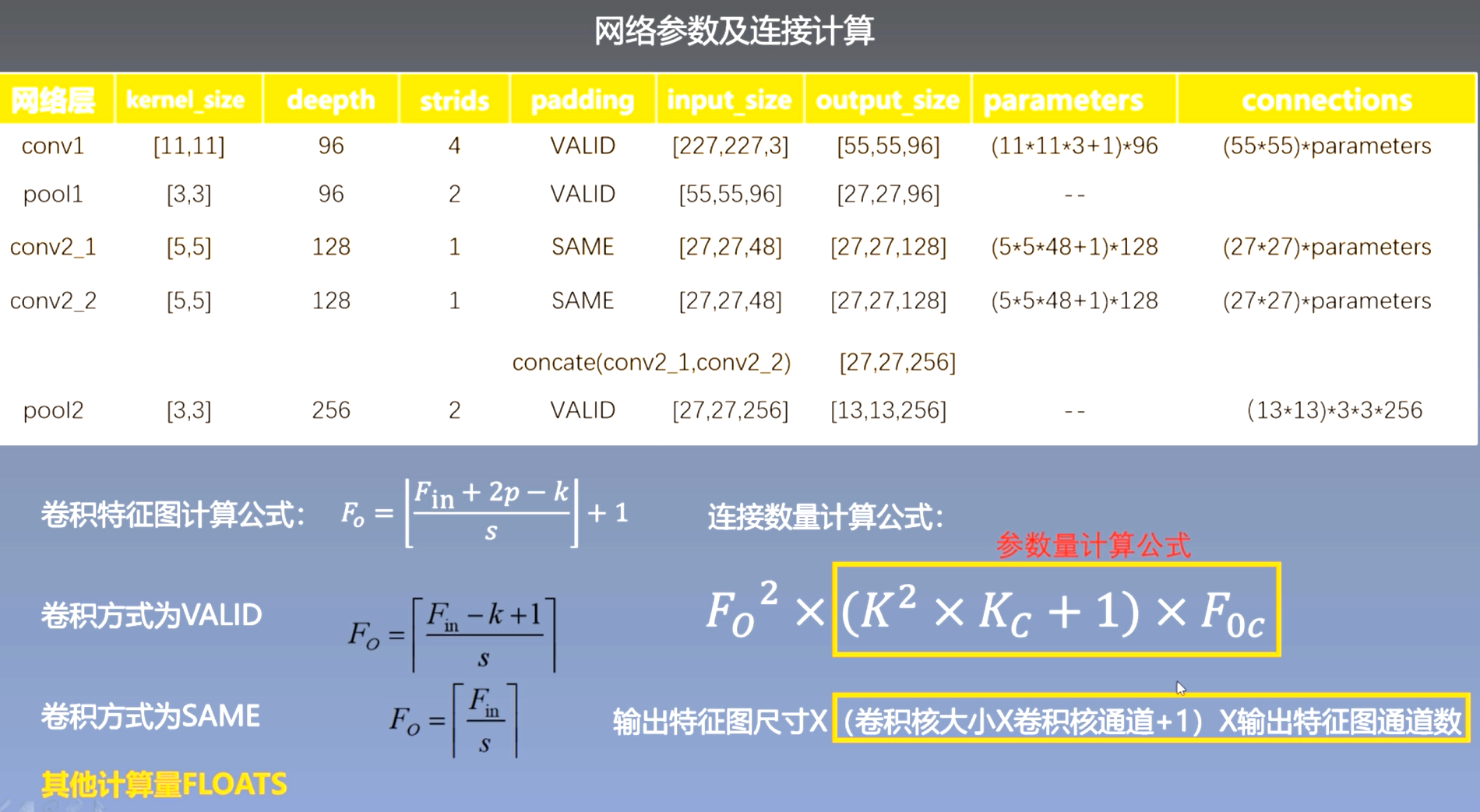
网络超参数及训练
训练数据
- 随机地从256256的原始图像中截取224224大小的区域(以及水平翻转及镜像),相当于增加了2*(256-224)^2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。
- 对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
- 进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。
基础知识
- datas numbers:数据量。训练使用的总数据量,比如数据一共包含64万图片那么总数据量就是64万 batchsize:批量大小。每次输入到网络的数据量,比如一次输入到网络64张图片batchsize=64
- steps:迭代次数。网络学习完所有数据需要的次数,比如batchsize=64,那么过完所有数据需要网络迭代一万次,steps=10000。即 数据量/批量大小=迭代次数
- epoch:轮数。网络学习一遍所有数据为一个epoch。
网络特点
- 成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
- 训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNe将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout.
- 在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。(后来的vgg证明这个作用不大)
- 使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。 AlexNet使用了两块GTX 580 GPU进行训练,同时AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
- 数据增强,随机地从256256的原始图像中截取224224大小的区域(以及水平翻转的镜像)对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。