031
英文名称: Deep Residual Learning for Image Recongnition
中文名称:
论文地址: https://arxiv.org/pdf/1512.03385.pdf
期刊/时间:
问题及挑战
问题1:神经网络叠的越深,则学习出的效果就一定会越好吗?
但其中一个障碍是常见的梯度消失/爆炸问题,它从一开始就阻碍了收敛。这个问题已经通过归一化初始化和中间归一化层得到了很大程度的解决,例如SGD可以使具有数十层的网络开始收敛,
问题2:随着网络深度的增加,准确性变得饱和,然后迅速下降。这种退化并不是由过拟合引起的,在适当深度的模型中增加更多的层数会导致更高的训练误差。
针对问题2的解决方法1:添加的层是身份映射(identity mapping),其他层是从学习到的浅模型复制。这种构造解的存在表明,较深的模型应该不会产生比较浅的模型更高的训练误差,但是实验表明现有的专家无法找到更好的解决方案。
方法
针对问题2,引入深度残差学习框架解决退化问题,我们不希望几个堆叠的层直接fit底层映射,而是显式地让这些层fit残差映射。
实验
讨论与总结
ResNet 解决的问题就一件事:怎样在添加更多的layers的同时,确保不会让现在的网络更糟糕?
更准确的说,要确保你的新函数(添加了新层级的神经网络)至少得包含住原来的旧函数。
怎样添加新层而不"损坏"原来的架构?
resnet给的答案是 把上一层的输出,复制一遍, 走两条道。
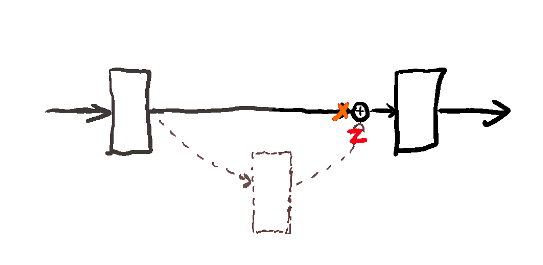
一般的图是把residual(残余"学习"层)放到中心的地方,所以可能会比较让人困惑。这里把residual放到一旁,以虚线表示, 因为就是表示"残余"。residual 残余层一般以 f(x) - x 表示; f(x) 其实就是最后往下一层的输出, 在我这里是 x+z; 所以 f(x) - x = z; z 就是这个残余层的输出。如果这个额外添加的残余层没用的话,那么z就往0靠,或者说x+z还是会往 x靠。
为什么这样可行?因为f(x) = x 这个identity函数很容易学, 只需要让残余层接近0,或者说让残余层的参数都调成0 就可以。 有了residual layer(残余层), 就可以有非常非常deep的神经网络了。100个层基本上随便加; 以前的话,100 个层,你梯度会很快消失,根本无法学习。
参考链接
- https://arxiv.org/pdf/1512.03385.pdf
- https://www.zhihu.com/question/64494691/answer/2093262951