088
英文名称: Towards Zero-Label Language Learning 中文名称: 面向零标签的语言学习
论文地址: https://arxiv.org/abs/2109.09193
期刊/时间: 2021
代码地址:
前置知识
摘要
- 问题是什么?
- 本文要做什么?
- 大概怎么做的
- 实验效果
本文探讨了自然语言处理(NLP)中的零标签学习,即在训练期间任何地方都不使用人类注释的数据,模型纯粹是在合成数据上训练的。我们框架的核心是一种新的方法,以更好地利用强大的预训练语言模型。具体来说,受最近在GPT-3上进行的小样本推理的成功启发,我们提出了一个名为无监督数据生成(UDG)的训练数据创建程序,该程序利用小样本提示来合成高质量的训练数据,而无需真正的人类注释。我们的方法实现了零标签学习,因为我们只在合成的数据上训练特定的任务模型,但我们取得了比在人类标记数据上训练的强大基线模型更好或相当的结果。此外,当与标记数据混合时,我们的方法作为一个非常有效的数据增强程序,在SuperGLUE基准上取得了新的最先进的结果。
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 承。相关工作
- 转。相关工作的不足和转机
- 合。本文工作
众所周知,深度学习模型是数据驱动的。在自然语言处理中,语言模型预训练已经成为一种成功的迁移学习方法,以有效减少对特定任务标记数据的要求(Devlin等人,2018;Liu等人,2019;Y ang等人,2019;Radford等人,2019;Raffel等人,2019;Brown等人,2020)。通过在无监督的大规模文本语料库上的训练,双向语言模型,如BERT和XLNet,能够学习上下文的文本表征,然后可以在下游任务上以较小的训练数据量进行微调,这已经推动了各种自然语言理解基准的技术水平。
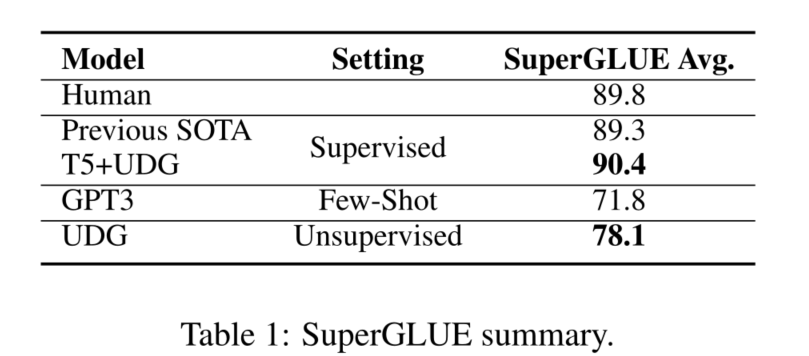
最近,巨大的语言模型(GLM),如GPT3(Brown等人,2020)已经被该模型被证明是有效的少量学习者。随着无监督训练语料库和模型规模的扩大,该模型能够根据手工制作的由任务描述和一些例子组成的输入提示,为一个未见过的NLP任务生成答案,并进行小样本推理。尽管没有涉及微调,但该语言模型在广泛的任务上与微调基线相比表现得很有竞争力,它的成功表明了NLP中转移学习的一个新范式。然而,在许多任务上,小样本推理和最先进的微调方法之间的差距仍然很大(例如,如表1所示,在SuperGLUE上比先前的最先进水平低17.5),敦促探索巨型语言模型在小样本推理之外的应用。
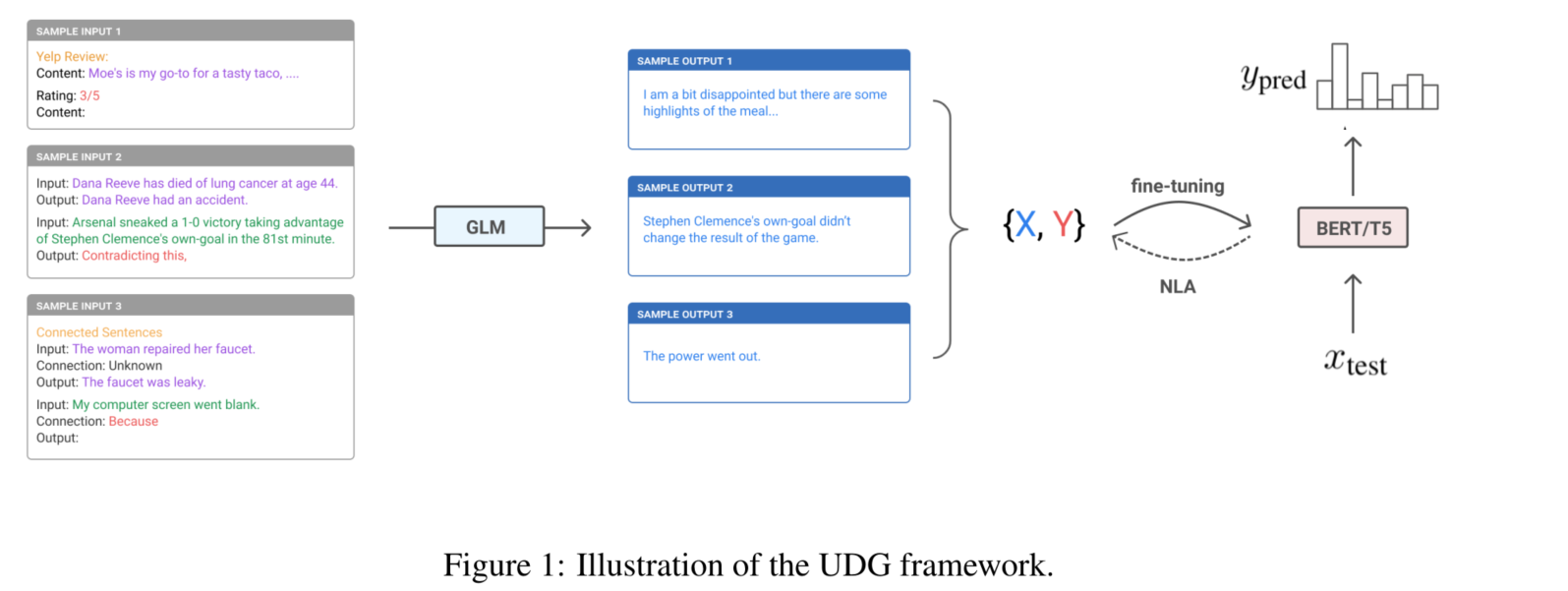
受GPT3的小样本学习能力的启发,本文将重点转移到利用GLMs来创建例子,而不是直接推理,并发现语言模型也是优秀的几率生成器。与少量推理范式类似,本文通过提示几个例子和对所需标签的描述来查询模型,模型会生成与标签相一致的例子,同时与给定的样本相类似。有趣的是,本文发现高质量的数据创建不需要监督,因此本文只需要在提示中使用未标记的例子。然后,由模型创建的数据集可以用来微调任何现成的模型。因此,这种方法可以被视为一种零样本学习程序,在整个过程中不需要人类的标签。不同于无监督程序,下游模型仍然需要用合成数据进行训练,然而训练实例的创建不需要人力。
按照这个程序,我们能够建立一个只使用无标签训练数据的系统,因此我们把它称为无监督数据生成(UDG)。实验表明,我们的无监督系统与强大的监督基线相比表现得很有竞争力,并在文本分类和SuperGLUE语言理解基准上取得了新的最先进的少数学习结果。合成的数据可以进一步用于数据增强的目的。当与现有的标记数据相结合时,我们能够实现第一个超人类的SuperGLUE分数。 这些结果表明,用强大的语言模型创建少量的训练数据是一种很有前途的替代方法,可用于少样本推理。
相关工作
主要介绍背景知识。
数据增强历来是NLP模型质量改进的一种流行技术,尤其是在低资源环境下(Y u等人。2018;Wei和Zou,2019)虽然传统上简单的启发式方法,如token级别的修改被应用于多样化的训练样本,但最近由于语言建模的进展,生成式数据增强得到了普及(Anaby-Tavor等人,2019;Papanikolaou和Pierleoni,2020;Juuti等人,2020;Lee等人,2021;Kumar等人,2021)。然而,他们往往需要标记的例子来微调生成模型,并进行大量的数据清理后处理。
另一方面,我们的方法以完全无监督的方式生成数据,无需对语言模型进行微调,展示了一种新的零标签学习范式。
我们的方法也与大型语言模型的知识检索密切相关。众所周知,这些模型善于从训练数据中记忆事实,并且能够作为开放的知识库来执行(Petroni等人,2019;Wang等人,2020;Roberts等人,2020;Carlini等人,2021)。我们的方法所创造的高质量的训练实例在很大程度上是由模型强大的知识检索能力所保证的,它减少了与所提供的标签无关的无规律的幻觉的机会。
方法
- 简要地重复问题
- 解决思路
- 必要的形式化定义
- 具体模型
实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析