基础知识
偏差&方差
在统计学中,一个模型好坏,是根据偏差和方差来衡量的,所以我们先来普及一下偏差和方差:
偏差
描述的是预测值(估计值)的期望E'与真实值Y之间的差距。偏差越大,越偏离真实数据。
\[Bias[\hat{f}(x)] = E[\hat{f}(x)] -f(x)\]方差
描述的是预测值P的变化范围,离散程度,是预测值的方差,也就是离其期望值E的距离。方差越大,数据的分布越分散。
\[Var[\hat{f}(x)] = E[(\hat{f}(x) - E[\hat{f}(x)])^2 ]\]模型的真实误差是两者之和,如下:
\[E[(y - \hat{f}(x))^2] = Bias[\hat{f}(x)]^2 + Var[\hat{f}(x)] + \sigma^2\]偏差和方差与模型复杂度的关系使用下图更加明了:
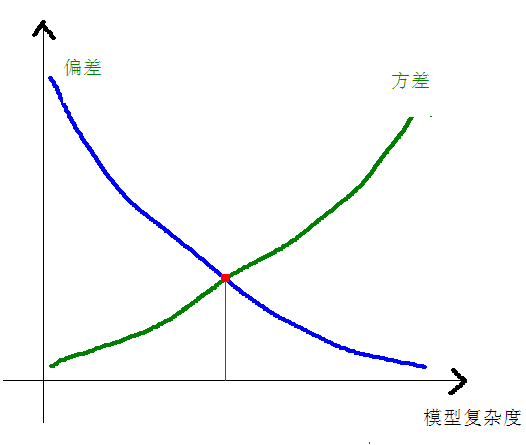
当模型复杂度上升的时候,偏差会逐渐变小,而方差会逐渐变大。
总体来说,偏差关系到数据被忽略的程度,而方差则关系到模型和数据的依赖程度。在所有的建模过程中,偏差和方差之间永远存在着一个权衡问题,并且需要我们针对实际情况找到一个最佳的平衡点。偏差和方差这两个概念可应用于任何从简单到复杂的模型算法,对于数据科学家来说,它们至关重要。
过拟合
在数据科学学科中,过拟合(overfit)模型被解释为一个从训练集(training set)中得到了高方差(variance)和低偏差(bias),导致其在测试数据中得到低泛化的模型。为了更好地理解这个复杂的定义,我们试着将它理解为去尝试学习英语的过程。我们要构建的这一模型代表了如何用英语交流。把莎士比亚的所有作品作为训练数据,把在纽约的对话作为测试集(testing set)。如果我们把社会认可程度来衡量这一模型的表现的话,那么事实表明我们的模型将不能够有效推广到测试集上。
欠拟合
刚才我们了解到了过拟合的模型具有高方差、低偏差的特点。那么相反的情况:低方差、高偏差的模型被称作欠拟合。相较于之前与训练数据紧密贴合的模型,一个欠拟合模型忽视了从训练数据中获得的信息,进而使其无法找到输入和输出数据之间的内在联系。让我们用之前尝试学习英语的例子来解释它,这一次我们试着去对之前我们用到的模型做出一些假设,并且我们改成使用《老友记》全集作为这一次学习英语的训练数据。为了避免我们之前犯过的错误,这次我们提前作出假设:只有那些以最常用的词:the, be, to, of, and, a为开头的句子才是重要的。当学习的时候,我们不去考虑别的句子,并且我们相信这能够构建更有效的模型。
经过了漫长的训练后,我们又再一次站在了纽约的大街上。这一次,我们的表现相对好了一点点,但是别人依然无法听懂我们,最后,我们还是以失败告终。尽管我们学习到了一些英语知识,并且能够组织一些数量有限的句子,由于从训练数据上造成的高偏差,我们无法从中学到英语的基础结构和语法。虽然这个模型没有受到高方差带来的影响,但是相对于之前的尝试来说,显得又太矫枉过正,拟合不充分!
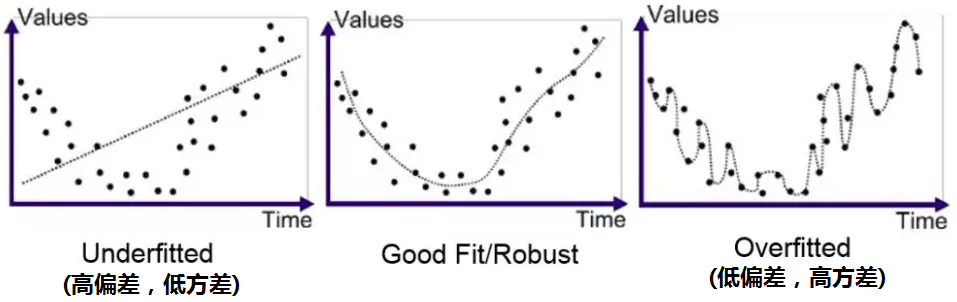
对数据的过度关注会导致过度拟合,对数据的忽视又会导致欠拟合,那么我们到底该怎么办呢?一定有一个能找到最佳平衡点的办法!值得庆幸的是,在数据科学中,有一个很好的解决方案,叫作"验证(Validation)"。用上面的例子来说,我们只使用了一个训练集和一个测试集。这意味着我们无法在实战前知道我们的模型的好坏。最理想的情况是,我们能够用一个模拟测试集去对模型进行评估,并在真实测试之前对模型进行改进。这个模拟测试集被称作验证集(validation set),是模型研发工作中非常关键的部分。
两次失败的英语学习过后,我们学聪明了,这一次我们决定使用一个测试集。我们这次同时使用Shakespeare的作品和《老友记》,因为我们从过去的经验中认识到越多的数据总是能够改善这个模型。不同的是,在这次训练结束以后,我们不直接走到街上,我们先找到一群朋友,每周和他们相聚,并以用英语来和他们交谈的形式来评估我们的模型。刚开始的第一周,由于我们的英语水平还很差,我们很难融入到对话当中。然而这一切仅仅是被模拟成一个验证集,每当我们意识到错误后,就能够调整我们的模型。最后,当我们能够适应并掌控与朋友们的对话练习时,我们相信已经是准备好面对测试集的时候了。于是,我们再一次大胆的走了出去,这一次我们成功了!我们非常适应在真实的情况下和别人交谈,这得益于一个非常关键的因素:验证集,是它改善并优化了我们的模型。
英语学习只是一个相对简易的例子。在众多真实的数据科学模型中,考虑到在一个验证集上出现过拟合的可能性,通常会使用到非常多的验证集!这样的解决办法称之为交叉验证(corss-validation),这个方法要求我们将训练集拆分成多个不同的子集,或者在数据足够多的条件下来使用多个验证集。交叉验证法这一个概念涵盖着问题的方方面面。现在当你碰到一个和过度拟合vs欠拟合,偏差vs方差这几个概念有关的问题的时候,你脑海中将会浮现出一个概念框架,这个框架将有助于你去理解并且解决这个问题!
数据科学看似复杂,但它其实都是通过一系列基础的模块搭建而成的。其中的一些概念已经在这篇文章中提到过,它们是:
- 过拟合:过度依赖于训练数据
- 欠拟合:无法获取训练数据中的存在的关系
- 高方差:一个模型基于训练数据产生了剧烈的变化
- 高偏差:一个忽视了训练数据的模型假设
- 过度拟合和欠拟合造成对测试集的低泛化性
- 使用验证集对模型进行校正可以避免实际过程中造成的欠拟合和过度拟合