033
英文名称: Distilling the knowledge in a neural network.
中文名称: 神经网络中的知识蒸馏
论文地址: https://arxiv.org/pdf/1503.02531.pdf
期刊/时间: NIPS 2014
前置知识
Knowledge Distill是一种简单弥补分类问题监督信号不足的办法。传统的分类问题,模型的目标是将输入的特征映射到输出空间的一个点上,例如在著名的Imagenet比赛中,就是要将所有可能的输入图片映射到输出空间的1000个点上。这么做的话这1000个点中的每一个点是一个one hot编码的类别信息。这样一个label能提供的监督信息只有log(class)这么多bit。然而在KD中,我们可以使用teacher model对于每个样本输出一个连续的label分布,这样可以利用的监督信息就远比one hot的多了。另外一个角度的理解,大家可以想象如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了。然而使用teacher model的输出可以恢复出这方面的信息。具体的举例就像是paper中讲的, 猫和狗的距离比猫和桌子要近,同时如果一个动物确实长得像猫又像狗,那么它是可以给两类都提供监督。综上所述,KD的核心思想在于"打散"原来压缩到了一个点的监督信息,让student模型的输出尽量match teacher模型的输出分布。其实要达到这个目标其实不一定使用teacher model,在数据标注或者采集的时候本身保留的不确定信息也可以帮助模型的训练。
摘要
- 问题是什么?
- 提高几乎所有机器学习算法性能的一个非常简单的方法是在相同的数据上训练许多不同的模型,然后对其预测进行平均化。不幸的是,使用集成模型进行预测是很麻烦的,而且计算成本太高,不允许大规模部署,特别是如果单个模型是大型神经网络。
- 我们要做什么?
- Caruana和他的合作者已经表明,有可能将集合的知识压缩到一个单一的模型中,这样更容易部署,我们使用不同的压缩技术进一步发展这种方法。
- 大概怎么做的
- 实验效果
- 我们在MNIST上取得了一些令人惊讶的结果,我们表明,通过将模型集合中的知识提炼成一个单一的模型,我们可以显著改善一个大量使用的商业系统的声学模型。我们还介绍了一种由一个或多个完整模型和许多专家模型组成的新型集合体,这些模型学会了区分完整模型所混淆的细粒度的类别。与专家的混合模型不同,这些专家模型可以被快速和平行地训练。
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 承。相关工作
- 转。相关工作的不足和转机
- 合。本文工作
昆虫作为幼虫时擅于从环境中汲取能量,但是成长为成虫后确是擅于其他方面,比如迁徙和繁殖等。
同理,神经网络训练阶段从大量数据中获取网络模型,训练阶段可以利用大量的计算资源且不需要实时响应。然而到达使用阶段,神经网络需要面临更加严格的要求包括计算资源限制,计算速度要求等等。
一个复杂的网络结构模型是若干个单独模型组成的集合,或者是一些很强的约束条件下(比如dropout率很高)训练得到的一个很大的网络模型。一旦复杂网络模型训练完成,我们便可以用另一种训练方法:"蒸馏",把我们需要配置在应用端的缩小模型从复杂模型中提取出来。通过soft target的形式,增加模型的泛化性能。
方法
- 简要地重复问题
- 解决思路
- 必要的形式化定义
- 具体模型
复杂模型学习区分大量的类,通常的训练目标是最大化正确答案的平均log概率,这么做有一个副作用就是训练模型同时也会给所有的错误答案分配概率,即使这个概率很小,而有一些概率会比其它的大很多。错误答案的相对概率体现了复杂模型的泛化能力。
举个例子,宝马的图像被错认为垃圾箱的概率很低,但是这被个错认为垃圾桶的概率相比于被错认为胡萝卜的概率来说,是很大的。(可以认为模型不止学到了训练集中的宝马图像特征,还学到了一些别的特征,比如和垃圾桶共有的一些特征,这样就可能捕捉到在新的测试集上的宝马出现这些的特征,这就是泛化能力的体现)。
原始的softmax函数:
\[q_i=\frac{\exp \left(z_i\right)}{\sum_j \exp \left(z_j\right)}\]但要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用处。
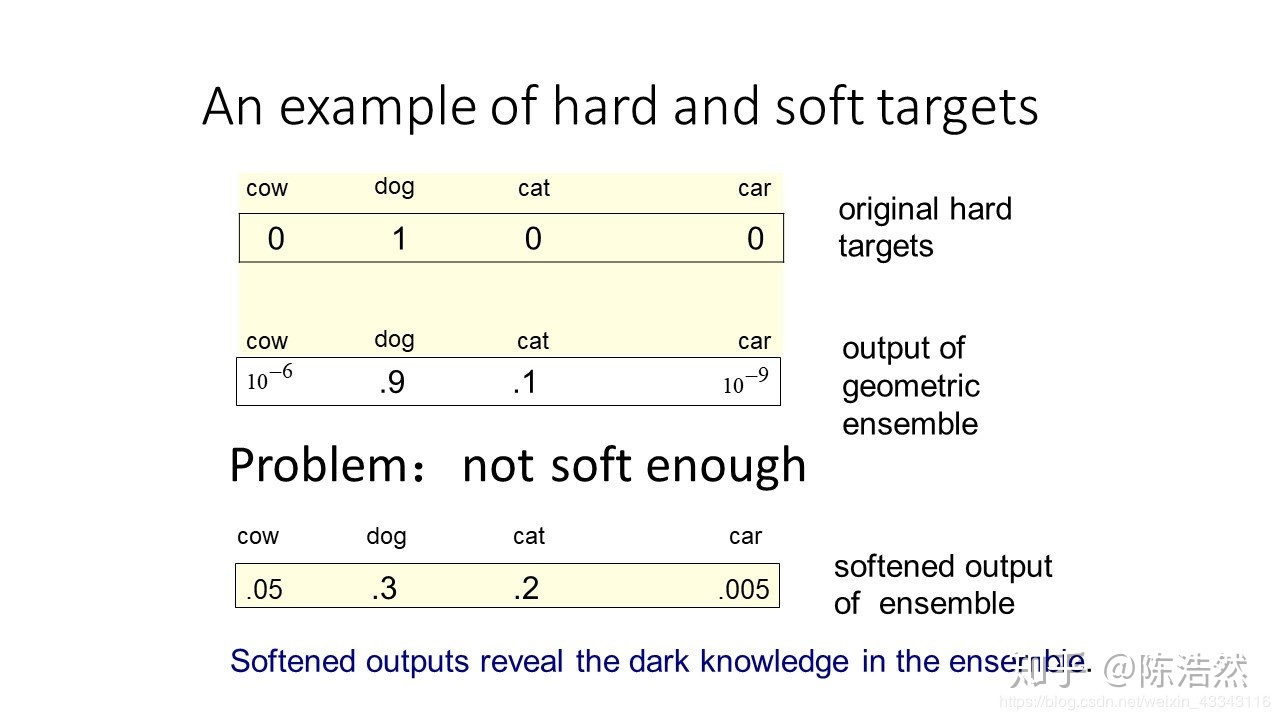
这里$T$是超参数,文中说是‘温度',经过该参数之后的softmax会更加平滑,分布更加均匀而大小关系不变。T参数在设置为1的时候就是平常的softmax函数。
在知识转换阶段,设置复杂网络与简易网络相同的T参数。在此之后再重新将T设置为1
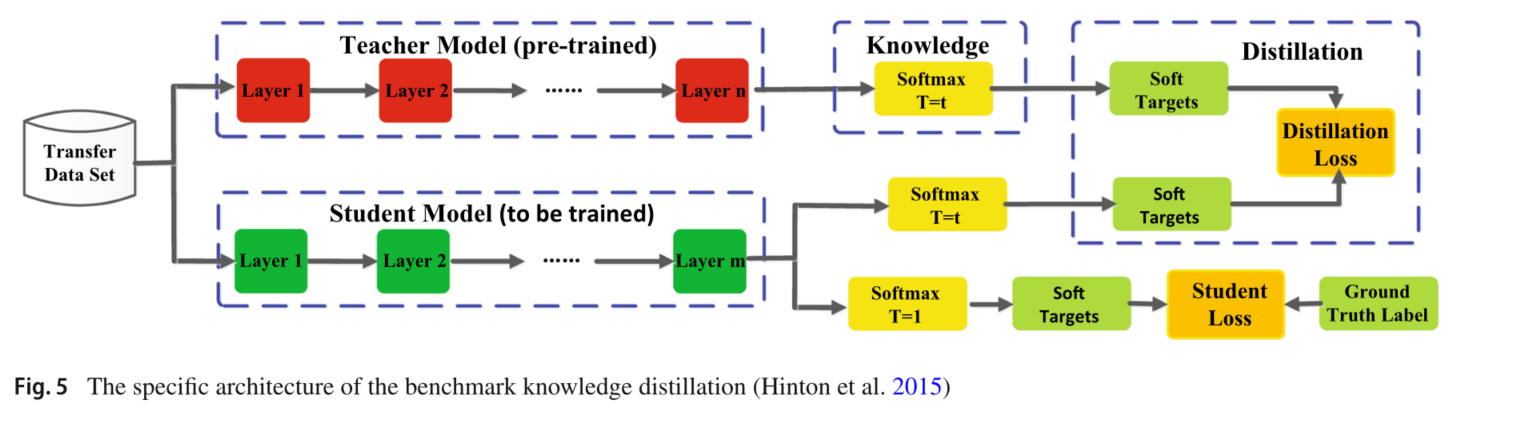
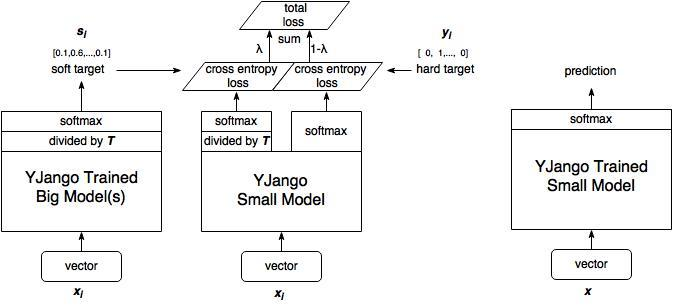
- 训练大模型:先用hard target,也就是正常的label训练大模型。
- 计算soft target:利用训练好的大模型来计算soft target。也就是大模型"软化后"再经过softmax的output。
- 训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
- 预测时,将训练好的小模型按常规方式(右图)使用。
实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析
Hinton等人做了三组实验,其中两组都验证了知识蒸馏方法的有效性。在MNIST数据集上的实验表明,即便有部分类别的样本缺失,小模型也可以表现得很不错,只需要修改相应的偏置项,就可以与原模型表现相当。
在语音任务的实验也表明,蒸馏得到的模型比从头训练的模型捕捉了更多数据集中的有效信息,表现仅比集成模型低了0.3个百分点。总体来说知识蒸馏是一个简单而有效的模型压缩/训练方法。这大体上是因为原模型的softmax提供了比onehot标签更多的监督信号
讨论与总结
【KD的训练过程和传统的训练过程的对比】
传统training过程(hard targets): 对ground truth求极大似然
KD的training过程(soft targets): 用large model的class probabilities作为soft targets
【训练过程为什么有效?】
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给KD模型带来的信息量大于传统的训练方式。