086
英文名称: ZS-BERT: Towards Zero-Shot Relation Extraction with Attribute Representation Learning
中文名称: ZS-BERT:利用属性表征学习实现零样本关系提取
论文地址: https://arxiv.org/abs/2104.04697
期刊/时间: NAACL 2021
代码地址: https://github.com/dinobby/ZS-BERT
前置知识
摘要
- 问题是什么?
- 虽然关系提取是知识获取和表示中的一项基本任务,而且新产生的关系在现实世界中很常见,但对于预测在训练阶段无法观察到的未见关系,人们做的努力较少。
- 我们要做什么?
- 在本文中,我们通过纳入看到的和未看到的关系的文本描述来制定零样本的关系提取问题。我们提出了一个新颖的多任务学习模型–零样本BERT(ZS-BERT),以直接预测未见过的关系,而不需要手工制作的属性标签和多次配对分类。
- 大概怎么做的
- 给定由输入句子和它们的关系描述组成的训练实例,ZS-BERT学习两个函数,通过共同最小化它们之间的距离和对看到的关系进行分类,将句子和关系描述投射到一个嵌入空间。通过在这两个函数的基础上生成未见过的关系和新来的句子的嵌入,我们使用近邻搜索来获得未见过的关系的预测。
- 实验效果
- 在两个常见的数据集上进行的实验表明,ZS-BERT可以超越现有的方法,在F1得分上至少提高13.54%。
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 关系提取是自然语言处理领域的一项重要任务,其目的是推断给定句子中一对实体之间的语义关系。
- 承。相关工作
- 有许多基于关系提取的应用,如扩展知识库(KB)(Lin等人,2015)和改善问题回答任务(Xu等人,2016)。然而,标签成本是一个相当大的困难。当把关系提取任务放在其他数据集(in the wild)时,现有的监督模型不能很好地识别训练数据中极其罕见甚至从未涉及的实例的关系。也就是说,在现实世界中,我们不应该假定新来的句子的关系/类别总是包含在训练数据中。因此,发明新的模型来预测事先没有定义或观察到的新类是至关重要的。这样的任务被称为Zeroshot学习(ZSL)(Norouzi等人,2013;Lampert等人,2014;Ba等人,2015;Kodirov等人,2017)。
- ZSL的想法是通过寻找中间的语义表征来连接已见和未见的类。与训练监督模型的常见方式不同,看到的和未看到的类在训练和测试阶段是不相干的。因此,ZSL模型需要在它们之间产生可转移的知识。有了ZSL关系提取模型,我们将被允许提取未观察到的关系,并处理新实体诞生后产生的新关系。
- 转。相关工作的不足和转机
- 现有的关于ZSL关系提取的研究很少,并且面临一些挑战。
- 首先,虽然典型的研究(Levy等人,2017)不能在不投入更多人力的情况下进行零样本关系分类,因为他们通过预先定义问题模板来解决这个问题。然而,在零样本设置下,手动创建新来未见的关系模板是不可行的,也是不实际的。我们希望有一个模型能够产生准确的零样本预测,而不需要手工制作标签。在这项工作中,我们利用了通常公开的关系描述来实现这一目标。
- 其次,虽然存在也利用关系描述的可及性的研究(Obamuyide和Vlachos,2018),但他们只是把零样本预测当作文本的包含任务,只输出一个二进制标签,表明输入句子中的实体是否可以被给定的关系描述所描绘。这样的问题构建需要在所有的关系描述上执行不切实际的多分类,并不能互相比较之间的关系。
- 合。本文工作
- 本文提出了一个新的模型–零样本BERT(ZS-BERT),为关系提取进行零样本学习,以应对上述挑战。ZS-BERT需要两个模型输入。一个是包含一对目标实体的输入句子,另一个是关系描述,即描述两个目标实体关系的文本。模型的输出是描述关系的属性向量。属性向量可以被认为是关系的语义表示,并将被用来生成未见过的关系的最终预测。
- 我们认为通过表征学习更好地利用关系描述比收集大量有标记关系的实例更有成本效益。因此,ZS-BERT的一个基本好处是免于繁重的众包或注释,即注释一个类有什么样的属性,这在零样本学习问题中是常用的(Lu等人,2018;Lampert等人,2009)。
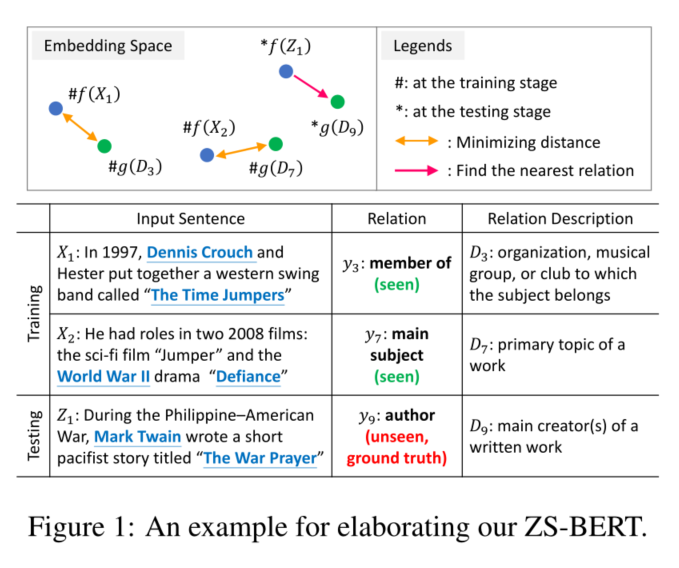
- 图1描述了ZS-BERT的整体架构, 主要包含5个步骤。每个训练实例是一个输入句子对 $X_i$ 以及相关联的关系描述 $D_j$。 首先,我们学习一个投影函数 $f$ 将输入句子 $X_i$ 投影到相应的属性向量, 即句嵌入。然后, 我们学习一个 $g$ 编码关系描述 $D_j$ 到相应的属性向量, 该属性向量是 $D_j$的语义表征。 其次, 给定一个训练实例 $\left(X_i, D_j\right)$ , 我们通过在嵌入空间中挖掘属性向量 $f\left(X_i\right)$ 和 $g\left(D_j\right)$之间的距离来训练 ZS-BERT。其次, 利用学习到的$g\left(D_l\right)$,我们可以把未见过的关系的描述$D_l$投射到嵌入空间中,这样未见过的类就可以尽可能地分开,以便进行零样本预测。最后,给定一个新的输入句子 $f\left(Z_k\right)$,我们可以使用它的归属向量$f\left(Z_k\right)$ 来寻找嵌入空间中的最近邻居作为最终的预测。简而言之,ZS-BERT的主要思想是在训练阶段根据关系的描述来学习关系的表示,并将这些表示与输入句子对齐。此外,我们利用学习到的对齐投影函数$f$和$g$为新的句子生成未见过的关系预测,这样就可以实现零样本关系提取。我们的贡献可以总结为以下几点。
- 从概念上讲,我们通过利用看到的和未看到的关系的文本描述来制定零样本关系提取问题。据我们所知,我们是第一次尝试通过从关系描述中学习表征来直接预测零样本设置下的未见关系。
- 在技术上,我们提出了一个新的基于深度学习的模型,ZS-BERT2,来处理零星的关系提取任务。ZS-BERT学习投影函数,使输入句子与嵌入空间中的关系保持一致,因此能够预测在训练阶段没有看到的关系。
- 经验上,在两个常用的数据集上进行的实验表明,ZS-BERT在ZSL设置下预测未见过的关系时,可以大大超过最先进的方法。我们还表明,当有一小部分未见过的关系的标记数据时,ZS-BERT可以快速适应并推广到少数学习中。
相关工作
主要介绍背景知识。
基于BERT的关系抽取
R-BERT (Wu and He, 2019)利用BERT生成上下文化的词表示,以及实体信息来进行监督学习关系抽取,并已显示出良好的结果。
BERT- PAIR (Gao et al.,2019)利用训练前的BERT句子分类模型进行few-shot关系抽取。通过将每个查询句与支持集中的所有句子进行配对,通过预先训练的BERT得到句子之间的相似度,进而用few-shot实例对新类进行分类。
这些模型的目的是解决一般的关系抽取任务,这些任务或多或少具有ground truth,而不是在zero-shot设置下。
基于零样本的关系抽取
Levy等人(2017)将zero-shot关系提取作为问答任务。他们手工定义了10个问题模板来表示关系,并通过训练一个阅读理解模型来回答哪个关系满足给定的句子和问题,从而产生预测。但是,需要人为定义不可见的关系的问题模板,这样才能执行ZSL。通过领域知识进行这样的注解是不可行的——当更多看不见的关系出现时,在实际是不可能的。相反,ZS-BERT的数据需求相对较轻。对于每个关系,本文只需要一种描述来表达语义意义。关系的描述更容易收集,因为本文可以从开放资源中获取它们。在这种情况下,本文可以不必为注释付出额外的努力。
OObamuyide和Vlachos(2018)将ZSL关系提取定义为文本蕴涵任务(textual entailment),要求模型预测包含两个实体的输入句子是否匹配给定关系的描述。他们使用增强顺序推理模型(ESIM) (Chen et al., 2016)和条件推理模型(CIM) (Rocktäschel et al., 2015)作为其派生方法。通过将每个输入句子与每个关系描述配对,训练模型回答成对文本是矛盾还是蕴涵。这使得模型能够对输入语句和不可见的关系描述对进行推理,从而能够相应地预测不可见的关系。
方法
- 简要地重复问题
- 解决思路
-
必要的形式化定义
-
$Y s={y_s^1, \ldots, y_s^n}$ : 可见关系标签
-
$\mathrm{Yu}={y_u^1, \ldots, y_u^n}$ : 不可见关系标签
-
对于可见与不可见数据集中的每个标签,都分别有一个对应的属性向量$a^i_s$和$a^i_u$。
-
给定 $N$ 个样本的训练集,其中包含输入句子$X_i$,实体$ei1$和$ei2$,和对应可见关系$y_s^j$的描述$D_i$,表示为 \(\left\{S_i=\left(X_i, e_{i 1}, e_{i 2}, D_i, y_s^j\right)\right\}_{i=1}^N\)
-
目标是训练一个零样本关系抽取模型$\mathcal{M}\left(S_i\right) \rightarrow y_s^i \in Y_s$用来预测不可见关系$y_u^j$,可表示为
$\mathcal{M}\left(S^{\prime}\right) \rightarrow y_u^j \in Y_u$
-
- 具体模型

输入句子$X_i$被标记化并输入到上半部分ZS-BERT编码器以获得上下文表示。具体来说,本文提取[CLS]的表示$H_0$和两个实体的表示$H_e^1$、$H_e^2$,然后将它们拼接起来,通过一个完全连接层和激活层来得到句子的表示$\hat{a}_s^i$。在下半部分,使用Sentence-BERT通过编码关系$D_i$的相应描述来获得可见(seen)关系的属性向量$ais$。
本文在多任务学习结构下训练ZS-BERT。一个任务是最小化属性向量$a_s^i$和句子嵌入向量$\hat{a}_s^i$之间的距离。另一种是在训练阶段对可见的关系$y_s^j$进行分类,将关系向量输入softmax层产生关系分类概率。在测试阶段,通过获得新出现的句子和不可见关系的嵌入,我们使用$\hat{a}_s^i$和最近邻搜索来获得不可见关系的预测。
学习关系属性向量
我们将关系描述$D_i$送入预先训练好的Sentence-BERT编码器(Reimers和Gurevych,2019),生成句子级别的表示,作为关系的属性向量$a^i$。
这个过程显示在图2的下半部分。这个例子的基础事实关系是publisher, along with its description Organization or person responsible for publishing books,games or software.我们只向Sentence-BERT提供关系描述,以获得属性向量。也就是说,我们认为派生的Sentence-BERT是一个投影函数g,将关系描述$D_i$转化为$a^i$。请注意,由Sentence-BERT产生的关系属性向量在模型训练期间是固定的
输入句子编码
我们利用BERT(Devlin等人,2019)来生成每个标记的上下文表示。我们首先用WordPiece(Sennrich等人,2016)对输入句子$X_i$进行标记化。两个特殊的标记[CLS]和[SEP]分别被附加到第一个和最后一个位置。由于实体本身在关系提取中确实很重要,我们使用一个实体标记向量,由除实体在句子中出现的索引外的所有为零组成,以指示实体$e_{i1}$和$e{i2}$的位置。
让H0是第一个特殊标记[CLS]的隐藏状态。我们使用tanh激活函数,再加上全连接层,得出表示向量$H_0^{\prime}$,由以下公式给出。$H_0^{\prime}=W_0\left[\tanh \left(H_0\right)\right]+b_0$,其中$W_0$ 和 $b_0$是权重和偏置的可学习参数。我们通过对两个实体的隐藏状态向量($H_e^1$ 和 $H_e^2$)进行平均,得到它们各自的标记隐藏状态向量。
具体来说,如果一个实体$e$由多个标记组成,且指数范围在$q$到$r$之间,我们对隐藏状态向量进行平均化,同时用全连接层增加一个激活操作,以生成其对该实体的表示,由以下公式给出。 \(H_e^c=W_e\left[\tanh \left(\frac{1}{r-q+1} \sum_{t=q}^r H_t\right)\right]+b_e\) 其中 $c=1,2$。句子中两个实体的表征$H_e^c(c=1,2)$共享相同的参数 $W_e$和$b_e$。然后,我们通过连接$H_0^{\prime}, H_e^1$, $H_e^2$来学习属性向量$\hat{a}_s^i$,然后是一个隐藏层,具体如下
\[\hat{a}_s^i=W_1\left(\tanh \left(\left[H_0^{\prime} \oplus H_e^1 \oplus H_e^2\right]\right)\right)+b_1\]其中$W_1$ 和 $b_1$是可学习的参数,$\hat{a}_s^i$的维度为$d$,$\oplus$是连接运算符。
模型训练
训练过程包含两个步骤:
-
使输入句子嵌入与对应关系属性向量(即positive)之间的距离最小,同时保证输入句子嵌入与不匹配关系(即negative)之间的嵌入对彼此距离更远。
-
目标是最大限度地提高基于交叉熵损失的已知关系分类的准确性。
实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析
讨论与总结
在这项工作中,我们提出了一个新颖而有效的模型–ZS-BERT,来解决零样本的关系提取任务。通过多任务学习结构和高质量的上下文表征学习,ZS-BERT不仅可以将输入的句子很好地嵌入到嵌入空间中,而且还能大幅提高性能。我们还进行了大量的实验来研究ZS-BERT的不同方面,从超参数敏感性到案例研究,最终表明ZS-BERT可以在零样本设置下稳定地超越现有的关系提取模型。此外,通过利用关系的原型作为辅助信息,学习有效的关系嵌入也可能有助于半监督学习或少量学习。
- 模型架构中,CLS有什么作用?SEP最后是否有编码进去?模型的输入和输出是什么?
- 损失函数中每一项的具体含义?这样设计的好处是什么?
- 将输入句子的描述与关系描述的分布对齐的依据是什么?有什么启示?
- 本文处理零样本问题的关键思路是什么?