009 GPT
英文名称: Improving Language Understanding by Generative Pre-Training
中文名称: 通过生成性预训练提高语言理解能力
论文地址: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
期刊/时间: 2018
前置知识
摘要
- 问题是什么?
- 本文要做什么?
- 大概怎么做的
-
实验效果
-
自然语言理解包括一系列不同的任务,如文本相关性、问题回答、语义相似性评估和文档分类。虽然大量的无标签文本语料库很丰富,但用于学习这些特定任务的有标签的数据却很少,这使得经过鉴别性训练的模型很难有充分的表现。
-
本文证明,通过在不同的无标签文本语料库上对语言模型进行生成性预训练,然后在每个具体任务上进行鉴别性微调,可以在这些任务上取得巨大的收益。与以前的方法相比,本文在微调过程中利用了任务理解的输入转换来实现有效的转移,同时要求对模型结构进行最小的改变。本文在广泛的自然语言理解基准上证明了本文方法的有效性。
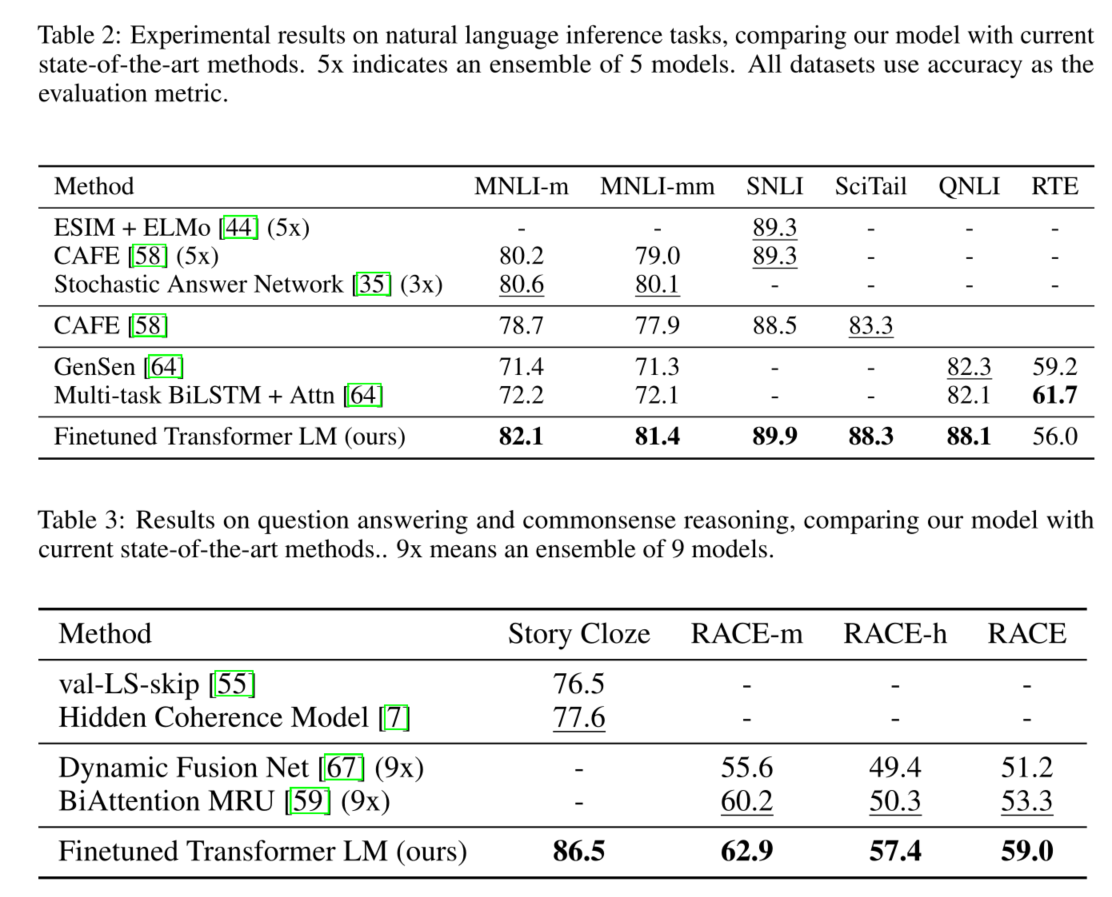
- 本文的通用任务诊断模型优于使用专门为每个任务设计的架构的鉴别性训练模型,在所研究的12个任务中的9个任务中明显改善了技术水平。例如,本文在常识推理(Stories Cloze Test)方面取得了8.9%的绝对改进,在问题回答(RACE)方面取得了5.7%的绝对改进,在文本关联(MultiNLI)方面取得了1.5%的改进。
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 承。相关工作
- 转。相关工作的不足和转机
- 合。本文工作
从原始文本中有效学习的能力对于缓解自然语言处理(NLP)中对监督学习的依赖至关重要。大多数深度学习方法需要大量的手动标记数据,这限制了它们在许多缺乏注释资源的领域的适用性。在这些情况下,能够利用未标记数据的语言信息的模型为收集更多的注释提供了一个有价值的选择,而这可能是费时和昂贵的。此外,即使在有相当多的监督的情况下,以无监督的方式学习好的表征也能提供一个显著的性能提升。到目前为止,最令人信服的证据是广泛使用预训练的词嵌入来提高一系列NLP任务的性能。
然而,由于两个主要原因,从未标记的文本中利用超过词级的信息是具有挑战性的。首先,目前还不清楚什么类型的优化目标有助于迁移,对学习文本表征最为有效。最近的研究考察了各种目标,如语言建模、机器翻译和话语连贯性,每种方法在不同的任务上都优于其他方法。现有的技术涉及对模型结构进行特定任务的改变,使用复杂的学习方案和增加辅助学习目标的组合。这些不确定因素使得开发有效的语言处理半监督学习方法变得困难。
在本文中,本文探索了一种半监督的方法,使用无监督的预训练和有监督的微调相结合来完成语言理解任务。本文的目标是学习一种通用的表征,这种表征可以在很少的调整下转移到广泛的任务中。本文假设可以获得一个大型的无标签文本语料库和几个带有人工注释的训练实例的数据集(目标任务)。本文的设置并不要求这些目标任务与未标记的语料库处于同一领域。本文采用一个两阶段的训练程序。首先,本文在未标记的数据上使用语言建模目标来学习神经网络模型的初始参数。随后,本文使用相应的监督目标将这些参数调整到目标任务中。
本文的模型架构使用Transformer,它已被证明在各种任务中表现强劲,如机器翻译,文档生成和语法解析。与循环网络等替代方案相比,这种模型选择提供了一种更结构化的内存,用于处理文本中的长期依赖关系,从而实现了跨不同任务的健壮迁移性能。在迁移过程中,本文利用从遍历风格方法派生的特定于任务的输入调整,它将结构化文本输入处理为单个连续的标记序列。正如在实验中所演示的那样,这些适应性使我们能够有效地进行微调,只需要对预训练模型的体系结构进行最小的更改。
本文在四种类型的语言理解任务上评估了方法–自然语言推理、问题回答、语义相似性和文本分类。本文的一般任务诊断模型优于采用专门为每项任务设计的架构的鉴别性训练模型,在所研究的12项任务中,有9项任务明显改善了技术水平。例如,本文在常识推理(Story Cloze Test)、问题回答(RACE)、文本推理(MultiNLI)和最近引入的GLUE多任务基准上取得了8.9%、5.7%和5.5%的绝对改善。本文还分析了预训练模型在四种不同环境下的零样本行为,并证明它为下游任务获得了有用的语言知识。
相关工作
主要介绍背景知识。
方法
- 简要地重复问题
- 解决思路
- 必要的形式化定义
- 具体模型
$\Theta$为超参数。每次使用窗口大小k的词预测下一个词的概率。
使用Transformer的解码器,由于Mask的存在,只能看到前面的元素。
\[\begin{aligned} h_0 &=U W_e+W_p \\ h_l &=\operatorname{transformer} \mathrm{block}\left(h_{l-1}\right) \forall i \in[1, n] \\ P(u) &=\operatorname{sof} \operatorname{tmax}\left(h_n W_e^T\right) \end{aligned}\]$U$为token的上下文向量。$h_0$为投影后的上下文向量与位置信息编码$W_e$之和。
训练程序包括两个阶段。
- 第一阶段是在一个大型文本语料库上学习一个高容量的语言模型。
- 第二个阶段是一个微调阶段,在这个阶段,使模型适应带有标记数据的判别性任务
Unsupervised pre-training使用multi-layer Transformer decoder,采用的优化任务是语言模型。Supervised fine-tuning就是在具体任务的标注数据上进行调优,以文本分类任务为例,只需要将最后1个token的最上层的激活向量再过一层线性转换+softmax。
针对其他一些任务的结构化输入数据,提出使用遍历(travelsal-style approach)的方法,模型框架改动小,灵活方便。如下图所示: 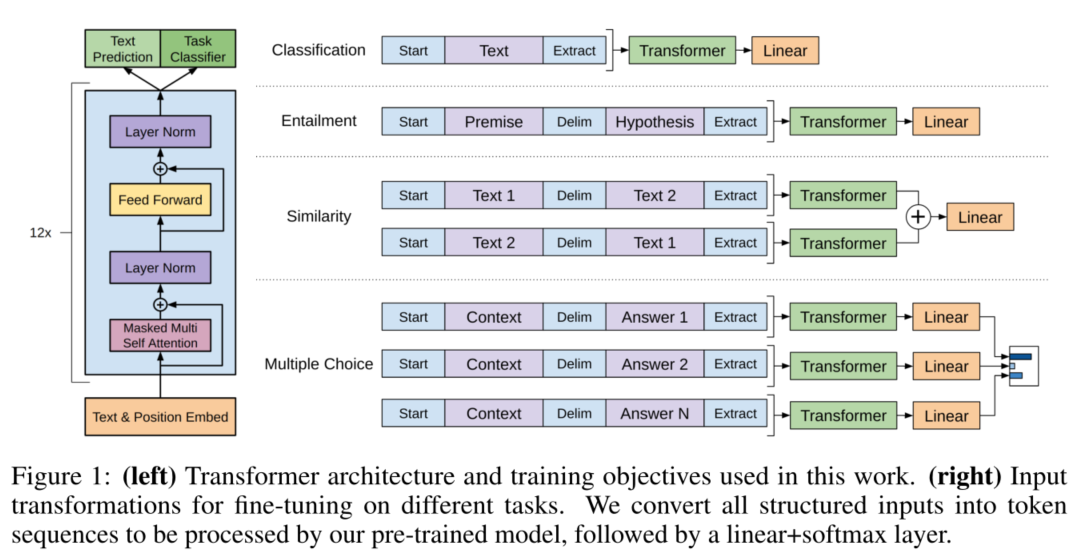
实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析
数据集:
实验结果:
左图主要研究层数的影响。右图对比了Transformer和LSTM的zero-shot效果(不在监督数据上进行训练),证实Transformer能够学到更多信息。
对照实验(Ablation studies),第1行是采用模型的效果,第2行表明pre-training的重要性,第3行表明fine-tuning阶段的辅助任务不一定总是有效的(在一些小数据集上可能没有更好),第4行则再次对比说明Transformer对比LSTM的领先性
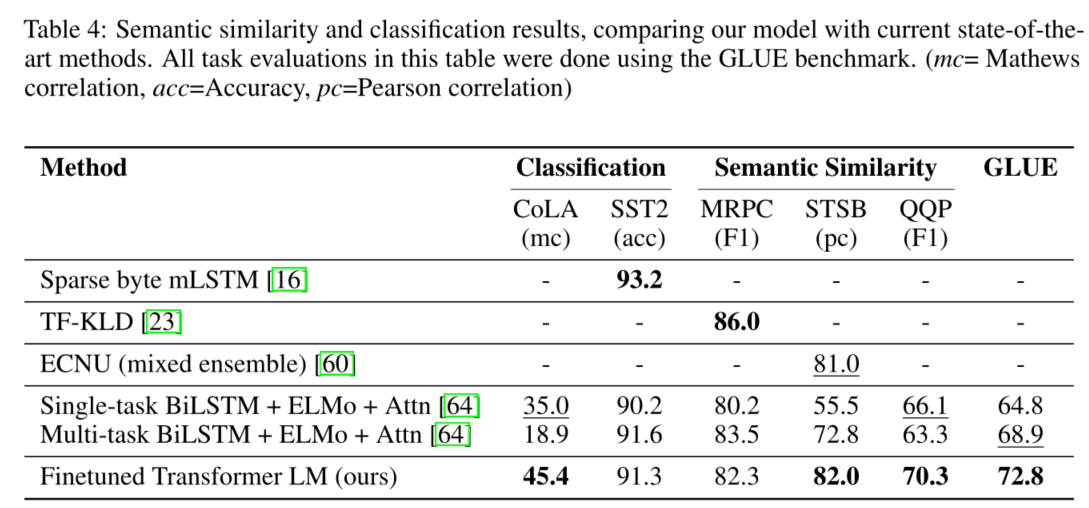
模型细节和Transformer的Decoder基本一致,有一些小改动,例如层数增大,激活函数改用GELU等。在Natural Language Inference, Question answering and commensense reasoning, Semantic Similarity, Classification等多个任务的多份数据集上均取得了很大提升。
论文在fine-tuning阶段,引入辅助任务(例如还是语言模型),不仅可以提升泛化能力,还能加速收敛。
讨论与总结
本文引入了一个框架,通过生成性的预训练和辨别性的微调,用一个单一的任务诊断模型实现强大的自然语言理解。通过对具有长篇连续文本的多样化语料库进行预训练,本文的模型获得了重要的世界知识和处理长距离依赖关系的能力,然后成功地转移到解决诸如问题回答、语义相似性评估、尾随确定和文本分类等鉴别性任务上,在本文研究的12个数据集中的9个上提高了技术水平。长期以来,使用无监督(预)训练来提高鉴别性任务的性能一直是机器学习研究的一个重要目标。本文的工作表明,实现显著的性能提升确实是可能的,并提示了哪些模型(transformer)和数据集(具有长距离依赖性的文本)在这种方法下效果最好。本文希望这将有助于对自然语言理解和其他领域的无监督学习进行新的研究,进一步提高本文对无监督学习如何以及何时发挥作用的理解。
问题
- 与Bert的区别是什么? Bert使用的是带掩码的语言模型,利用Transformer的编码器,使用的是一种完形填空的方式,既能看到前面的词,又能看到后面的词, GPT使用的方式是用历史预测未来的方式,利用Transformer的解码器;使用编码器和解码器并不是两者的主要区别,主要区别在于目标函数的选取,GPT预测未来比Bert完形填空要难。
- 论文的创新与不足是什么? 核心点:不管下游任务输入及输出如何变化,模型的结构都不变。 主要贡献在将Transformer发扬光大(相比word-level的嵌入词向量能够学习到更丰富的语义语境信息,相比传统的RNN网络能够建模更长距离的相关信息),沿用Unsupervised pretraining + Supervised fine-tuning的套路,在很多任务上刷新了成绩。但创新性不强,在工业实践上提供了一定参考。