077
英文名称: RelationPrompt: Leveraging Prompts to Generate Synthetic Data for Zero-Shot Relation Triplet Extraction
中文名称:
论文地址: https://arxiv.org/abs/2203.09101
期刊/时间: ACL2022
前置知识
摘要
- 问题是什么?
- 尽管关系抽取在建立和表示知识方面很重要,但对未见过的关系类型生成的研究较少。
- 我们要做什么?
- 我们引入了零样本关系三元组提取(ZeroRTE)的任务设置,以鼓励对低资源关系提取方法的进一步研究。
- 大概怎么做的
- 给定一个输入句子,每个提取的三元组由头部实体、关系标签和尾部实体组成,其中关系标签在训练阶段是看不到的。为了解决ZeroRTE,我们提出通过prompting语言模型合生成结构化文本来合成关系实例。具体来说,我们将语言模型提示和结构化文本方法统一起来,设计了一个结构化提示模板,用于在关系标签提示(RelationPrompt)的条件下生成合成关系样本。为了克服在一个句子中提取多个关系三元组的限制,我们设计了一个新颖的三元组搜索解码方法。
- 实验效果
- 在FewRel和Wiki-ZSL数据集上的实验显示了RelationPrompt在ZeroRTE任务和零样本关系分类中的功效。代码和数据见https://github.com/declare-lab/RelationPrompt
介绍
按照起承转合的思想阅读。
- 起。做的哪方面工作?
- 关系提取旨在预测非结构化文本中实体之间的关系,其应用包括知识图谱构建和问答。然而,现有的方法往往需要大量的标注样本数据集,这些样本的标注成本很高,而且有一套固定的关系。目前,较少的研究集中在零样本设置上,在这种情况下,模型需要归纳到未见过的关系集,而没有可用的标注样本。
- 承。相关工作
- 转。相关工作的不足和转机
- 虽然有现有的零样本关系任务设置,但它们不需要提取完整的关系三元组。Chen和Li(2021)之前提出了零样本关系分类(ZeroRC)的任务设置,以对未见过的标签进行给定的头和尾实体对之间的关系分类。然而,假设Ground-Truth实体是现成的,这并不总是实际或现实的。Zero-Shot Relation Slot-Filling旨在根据提供的头部实体和关系来预测尾部实体,但也依赖其他方法来检测实体。因此,它在实践中也面临着误差传播的挑战(Zhong and Chen, 2021)。
- 为了解决数据稀缺的挑战,有几种现有的方法。
- 尽管远程监督可以用来构建具有许多关系类型的关系语料库,但这种方法通常会导致标注质量低于人工标注。此外,远程监督仍然限于现有知识库中固定的关系类型。
- 另一种方法是制定任务目标,使标签空间不受限制。例如,零散的句子分类可以重构为entailment或embedding similarity目标。然而,现有的公式是为序列分类任务设计的,不能直接应用于结构化预测任务,如关系三元组抽取。
- 第三个方向是利用预先训练好的语言模型,使用特定任务的提示模板,这使得模型能够泛化到几乎没有训练样本的新任务,如零样本分类。通过利用提示语中的语义信息来查询预先训练的语言模型的语言理解能力,这种零散的潜力是可能的。
- 合。本文工作
- 我们提出了一个新的、具有挑战性的任务设置,即零样本关系三元组提取(ZeroRTE)。ZeroRTE的目标是从每个句子中提取形式为(头部实体,尾部实体,关系标签)的三元组,尽管没有任何包含测试关系标签的标注训练样本。为了明确比较不同的任务设置,我们在表1中提供了一个总结。据我们所知,这是第一项将关系三元组提取任务扩展到零样本任务的工作。
- 我们提出了RelationPrompt,它将零样本问题重构为合成数据的生成。其核心概念是利用关系标签的语义,促使语言模型生成能够表达所需关系的合成训练样本。然后,合成数据可以被用来训练另一个模型,以执行零样本任务。
- 为了将关系三元组信息编码为可由语言模型生成的文本序列,我们将提示模板与结构化文本格式统一起来。结构化文本使用特殊的标记来编码结构化信息,这些信息可以很容易地被解码为三元组。然而,生成包含多个不同关系三元组的句子是具有挑战性的。设计一个复杂的结构化提示模板来编码多个三元组可能会影响生成质量,因为语言模型需要同时操作多个关系。因此,我们专注于生成单三元组样本,并探索如何通过下游关系提取器模型克服这一限制。具体来说,我们提出了一种名为Triplet Search Decoding的方法,该方法允许在预测时提取多个三元组,尽管在合成样本上进行训练,而每个样本只包含一个三元组。

- 本文贡献:
- 我们介绍了ZeroRTE任务设置,它通过将关系三元组提取任务扩展到零样本任务,克服了先前任务设置中的限制。ZeroRTE作为一个公开的基准,基于重组的FewRel(Han等人,2018)和Wiki-ZSL(Chen和Li,2021)数据集发布。
- 为了使ZeroRTE可以在有监督的情况下解决,我们提出了RelationPrompt,通过提示语言模型生成结构化文本来生成合成的关系实例。
- 我们提出Triplet Search Decoding来克服在一个句子中提取多个关系三元组的限制。
- RelationPrompt超越了先前的ZeroRC方法和ZeroRTE的基线,为未来的工作设立了标准。我们的分析表明,生成的样本是合理的和多样化的,因此可以作为有效的合成训练数据。
方法
- 简要地重复问题
- 解决思路
- 为了在ZeroRTE中提取未见过的关系标签的三元组,我们提出了一个叫做RelationPrompt的框架,它使用关系标签作为提示,生成目标未见过的标签的合成关系实例。然后,这些合成数据可以用来监督任何下游的关系提取模型。
- 我们的框架需要两个模型:一个是用于合成关系样本的关系生成器,另一个是在合成数据上训练的关系提取器,用于预测未见过的关系的三元组。为了表示要由语言模型处理的关系三元组信息,我们设计了结构化的提示模板。关系提取器被设计为同时支持ZeroRTE和ZeroRC任务。我们进一步提出三元组搜索解码,以克服生成具有多个三元组的关系样本的挑战。
- 必要的形式化定义
- 可见的数据集$D_s$,用于训练
- 生成的不可见数据集$D_u$,用于测试
- 数据集
D=(S,T,Y)。S表示输入句子,T表示输出三元组,Y表示出现在D中的一系列标签 - 每个数据样本包含输入句子
s∈S,它对应于一个列表t∈T,可以包含一个或多个输出三元组。
- 具体模型
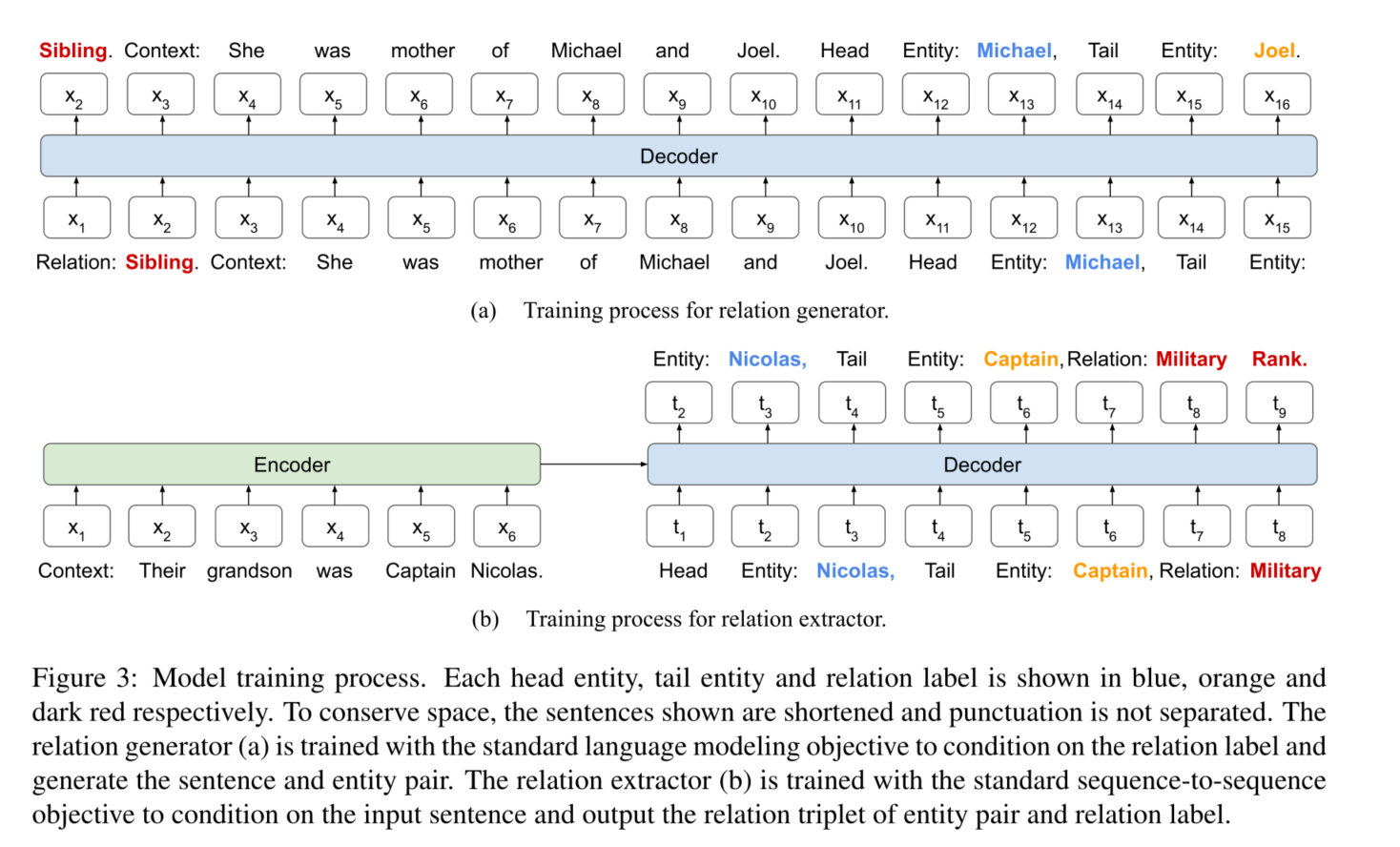
关系生成器(Relation Generator)
我们促使语言模型通过对目标未见过的关系标签进行调节来生成合成样本。如算法1所示,关系生成器$M_g$首先对所见数据集$D_s$的样本进行微调(第1行),然后通过关系标签$Y_u$提示来生成合成样本集$D_{synthetic}$。
输入:Relation: y
输出:Context: s. Head Entity: $e_{head}$, Tail Entity: $e_{tail}$.
我们采用因果语言模型作为我们的关系生成器,以自回归方式对结构化序列进行采样。如果出现解码错误,即在生成的上下文中找不到实体,我们会丢弃该样本并继续生成,直到达到一个固定的有效样本数量。
关系提取器(Relation Extractor)
如算法1所示,关系提取器$M_e$首先在所见数据集$D_s$的样本上进行微调(第2行),最后在合成样本$D_{synthetic}$上进行调整(第4行)。最后,$M_e$被用来预测并从测试句子$S_u$中提取关系三元组(第5和第6行)。
输入: Context: s
输出: Head Entity: $e_{head}$, Tail Entity: $e_{tail}$, Relation:y
我们使用标准的序列-序列目标进行训练,并使用贪婪解码进行生成。为了预测一个给定句子s中的单一关系三元组,我们可以在没有任何初始解码器输入的情况下生成模型输出。在实体或关系无效的情况下,我们将其视为该样本的空预测。另一方面,通过提供实体信息作为初始解码器输入,可以很容易地支持ZeroRC的预测。
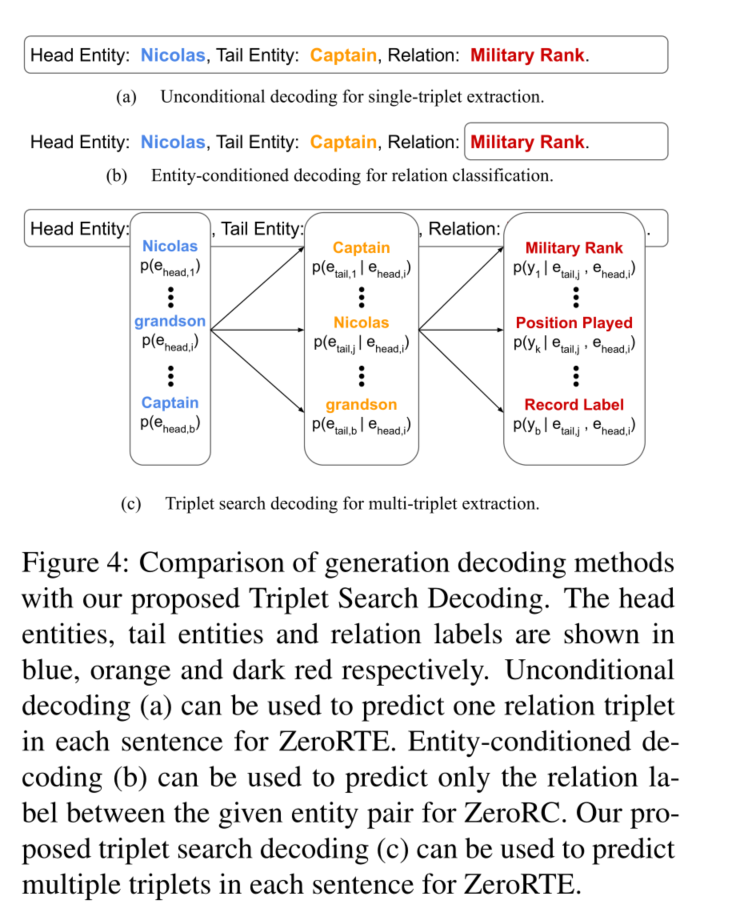
输入: Context: s, Head Entity: $e_{head}$, Tail Entity: $e_{tail}$., Relation:
输出: y
使用三元组搜索解码法(Triplet Search Decoding)提取多个三元组
鉴于关系提取器将一个句子作为输入并以自回归方式生成输出序列,如图4a中的贪婪解码可以输出一个单一的序列。如图4c所示,三联体搜索解码可以输出多个序列,每个序列对应于不同的候选关系三联体。然后我们应用一个似然阈值来过滤最终的输出序列。核心概念是在生成过程中通过考虑头部实体、尾部实体和关系标签的多个候选者来列举多个输出序列。
与其他解码方法(如beam search)相比,三元组搜索解码利用了我们结构化文本模板中的特定关系三元组结构。
整体推断概率表示:
\[\begin{aligned} p\left(\text { triplet }_{i, j, k}\right)=& p\left(e_{\text {head }, i}, e_{\text {tail }, j}, y_k\right) \\ =& p\left(y_k \mid e_{h e a d, i}, e_{\text {tail }, j}\right) \\ & \cdot p\left(e_{\text {tail }, j} \mid e_{h e a d, i}\right) \\ & \cdot p\left(e_{h e a d, i}\right) \end{aligned}\]实验
- 数据集和实验设置
- 主实验,提供详尽的实验分析
在Wiki-ZSL和FewRel数据集上表现SOTA。
相关工作
主要介绍背景知识。
零样本关系抽取: 零样本关系提取以前被框定为一个填槽任务,并通过阅读理解方法解决。然而,他们的方法需要为每个关系标签手动设计模板,这不能很好地扩展到新的关系类型。另一种方法是将其表述为一个包含性的任务,这并不是限制到一个固定的关系标签空间。相反,包含方法确定任意的句子和关系标签对是否兼容。然而,它是为句子分类设计的,不能应用于ZeroRTE。
数据增强:在有监督的低资源任务中,提高模型性能的一个流行方法是数据增强。最初开发了简单的启发式方法,如标记操作,语言建模的新方法提高了增强样本的质量。尽管有一些数据增强方法可以应用于结构化任务,如命名实体识别和关系提取,但它们需要现有的训练样本,不能轻易地适应于零样本的任务。
知识检索: RelationPrompt还利用存储在语言模型中的知识来组成基于现实语境的关系样本。为了确保生成的样本在事实上是准确的,语言模型需要强大的知识检索能力。
语言模型提示: 基于提示的方法已经显示出作为自然语言处理中零样本或小样本推理的新范式的前景。另一个优点是有可能使非常大的语言模型适应新的任务,而无需相对昂贵的微调。同时进行的工作也表明,语言模型可以产生合成训练数据。然而,这种方法尚未被证明对更复杂的任务(如三元组抽取)有效。
结构化预测: RelationPrompt为关系三元组提取生成合成数据,这是一项结构化预测任务。因此,它可以广泛适用于其他结构化预测任务,如命名实体识别、事件提取或方面情感三元组提取。
讨论与总结
- 在这项工作中,我们引入了零样本关系三元组提取(ZeroRTE)的任务设置,以克服以往任务设置中的基本限制,并鼓励在低资源关系提取方面的进一步研究。
- 为了解决ZeroRTE,我们提出了RelationPrompt,并表明语言模型可以通过关系标签提示有效地生成合成训练数据,从而输出结构化文本。
- 为了克服在一个句子中提取多个关系三元组的限制,我们提出了Triplet Search Decoding方法,该方法是有效和可解释的
- 结果表明,我们的方法超过了先前的ZeroRC方法以及ZeroRTE上的强大基线,为未来的工作设定了标准。
- 未来的改进方向可以是确保生成的实体跨度与语言模型提示中的关系语义更加兼容。
思考
抽取关系方式可以借鉴。先使用已有数据训练模型,然后迁移到其他领域。
- 首先使用标注的数据集训练模型
- 其次基于训练的模型和不可见的标签数据生成新的数据集
- 利用生成的数据集微调模型,生成最后的模型
- 基于输入的句子和模型抽取三元组