深度学习综述
选自论文Deep Learning
引言
深度学习方法是具有多个表示级别的表示学习方法,通过组合简单和非线性的模块获得,每个模块将一个级别(从原始输入开始)的表示转换为更高、稍微更抽象的级别的表示.通过组合足够多的此类变换,可以学习非常复杂的功能。
监督学习
在训练过程中,我们计算一个目标函数,用于测量输出分数与所需分数模式之间的误差(或距离)。然后机器修改其内部可调参数以减少此错误。这些可调整的参数,通常称为权重,是实数,可以看作是定义机器输入-输出功能的"旋钮"。在典型的深度学习系统中,可能有数亿个这样的可调整权重,以及数亿个用于训练机器的标记示例。
目标函数,对所有训练样例进行平均,可以看作是权值高维空间中的一种丘陵景观。负梯度向量表示该景观中下降最陡的方向,使其更接近最小值,输出误差平均较低。
训练后,系统的性能在称为测试集的不同示例集上进行测量。这用于测试机器的泛化能力——它在训练期间从未见过的新输入上产生合理答案的能力。
为了使分类器更强大,可以使用通用非线性特征,如Kernel方法,但通用特征(如高斯核产生的那些)不允许学习器在远离训练示例的地方很好地泛化。
堆栈中的每个模块都转换其输入以增加表示的选择性和不变性。通过多个非线性层,例如 5 到 20 的深度,系统可以实现其输入的极其复杂的功能,这些功能同时对微小的细节敏感——将萨摩耶犬与白狼区分开来——并且对诸如背景等大的不相关变化不敏感,姿势,照明和周围物体。
关键的部分是目标相对于模块输入的导数(或梯度)可以通过从相对于该模块的输出(或后续模块的输入)的梯度逆向计算来计算。反向传播方程可以重复应用以通过所有模块传播梯度,从顶部的输出(网络产生预测的地方)一直到底部(外部输入被馈入的地方)。一旦计算了这些梯度,就可以直接计算相对于每个模块的权重的梯度。
深度学习的许多应用程序使用前馈神经网络架构(图 1),它学习将固定大小的输入(例如,图像)映射到固定大小的输出(例如,几个类别中的每个类别的概率) .从一层到下一层,一组单元计算其前一层输入的加权和,并将结果传递给非线性函数。目前最流行的非线性函数是整流线性单元(ReLU),简单来说就是半波整流器f(z) = max(z, 0)。
在过去的几十年里,神经网络使用更平滑的非线性,例如 tanh(z) 或 1/(1 + exp(−z)),但 ReLU 通常在具有多层的网络中学习得更快,允许训练深度监督没有无监督预训练的网络。不在输入或输出层中的单元通常称为隐藏单元。隐藏层可以被视为以非线性方式扭曲输入,从而使最后一层可以线性分离类别。
反向传播算法
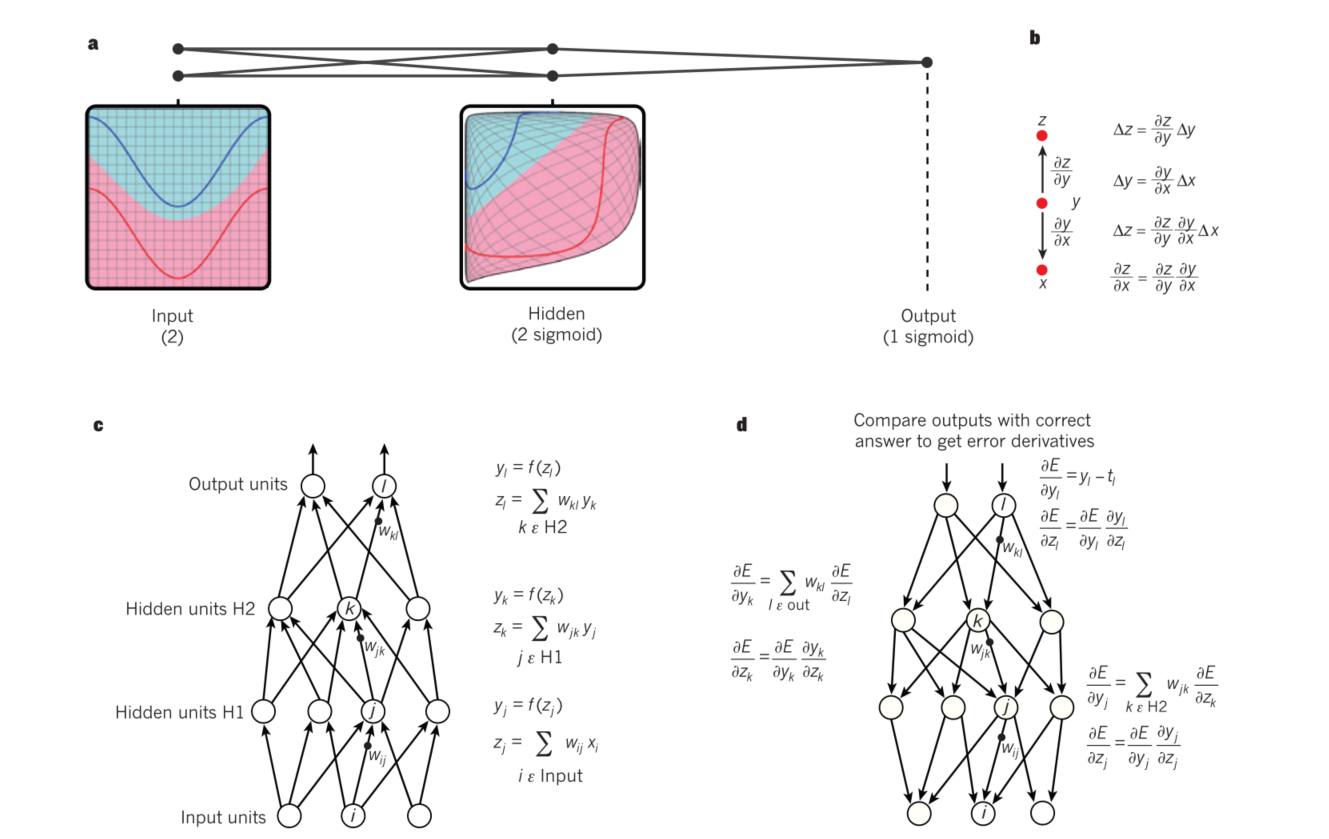
- a.多层神经网络示例
- b.链式传播。
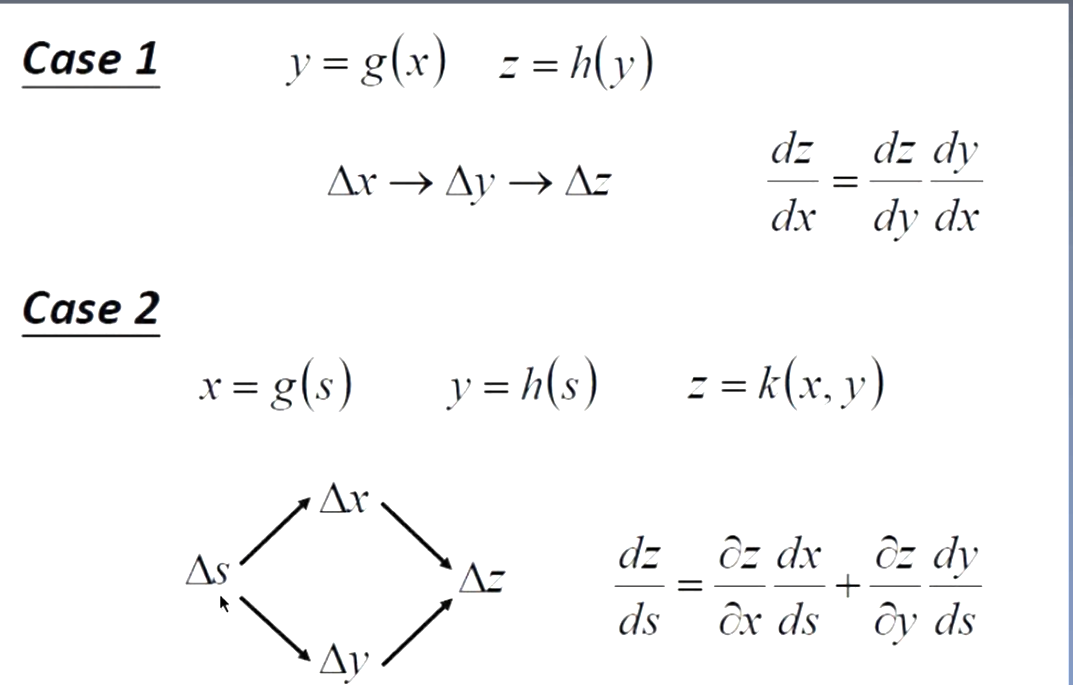
- c.正向传播。
- d.反向传播。
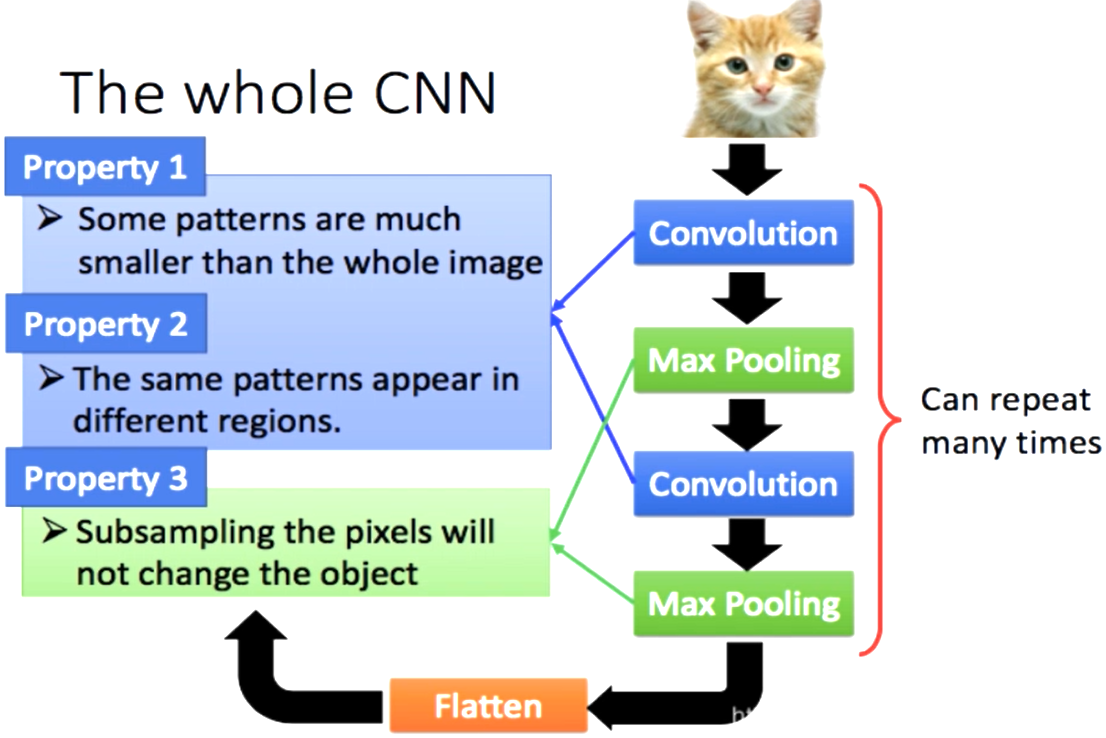
CNN
- 一个神经元无法看到整张图片
- 能够联系到小的区域,并且参数更少
-
图片压缩像素不改变图片内容
分布表示与语言模型
多层神经网络的隐藏层学习以一种易于预测目标输出的方式来表示网络的输入。
上下文中的每个单词都作为 N 中的一个向量呈现给网络,也就是说,一个组件的值为 1,其余的为 0。在第一层,每个单词创建不同的激活模式,或者词向量。在语言模型中,网络的其他层学习将输入词向量转换为预测下一个词的输出词向量,该输出词向量可用于预测词汇表中任何一个词作为下一个词出现的概率。网络学习包含许多活动组件的词向量,每个活动组件都可以解释为单词的单独特征,正如在学习符号的分布式表示的上下文中首次展示的那样。
在引入神经语言模型之前,语言统计建模的标准方法没有利用分布式表示:它基于对长度不超过 N 的短符号序列(称为 N-gram)的出现频率进行计数。
可能的 N-gram 的数量在 \(V^N\) 的数量级上,其中 V 是词汇量,因此少数单词就可能需要非常大的训练语料库。N-gram 将每个单词视为一个原子单元,因此它们不能泛化语义相关的单词序列,而神经语言模型可以,因为它们将每个单词与一个实值特征向量相关联,并且语义相关的单词最终彼此接近在那个向量空间中。
循环神经网络
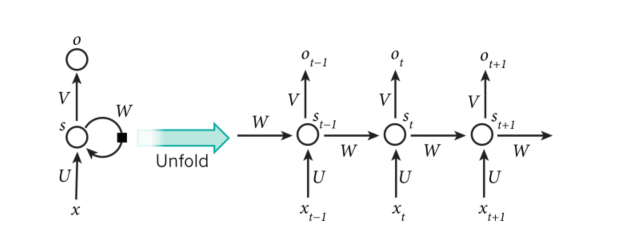
特点:
- RNN在每个时间点连接参数值,参数只有一份
- 除了输入以外,还会简历在以前的记忆基础上
- 内存的要求与输入的规模有关